
SO! Amplifies: Phantom Power


Phantom Power is an aural exploration of the sonic arts and humanities, that launched in March 2018 with Episode 1: Dead Air (John Biguenet and Rodrigo Toscano) Hosted by poet + media artist cris cheek and sound + media scholar Mack Hagood, this podcast explores the sounds and ideas of artists, technologists, producers, composers, ethnographers, historians, cultural scholars, philosophers, and others working in sound. Because Phantom Power is about to kick off its second season on February 1, 2019, we thought we’d dig a little deeper into who they are and who they’d like to reach with their good vibrations.
Funded through a generous grant from the Miami University Humanities Center and The National Endowment for the Humanities, Phantom Power was created with the goal of bringing together three important streams of conversation in the humanities
(1) diverse and interdisciplinary scholarly pursuits, taking place under the umbrella of “sound studies,” that analyze and critique the sonic entanglements and practices of human beings;
(2) experimental aesthetic practices that use sound as a medium and inspiration to expand the boundaries of art, music, and poetry;
and (3) the nascent use of podcasting as a mode of scholarship, intra-/interdisciplinary communication, and public outreach.
The public-facing podcast draws on the extensive radio experience of co-host cris cheek, creator of Music of Madagascar, made for BBC Radio 3 in 1994, which won the SONY GOLD AWARD, Specialist Music Program of the Year. In 1998 he made crowding, a three and a half hour live-streamed webcast of largely improvised speech and sound events, commissioned as part of Torkradio from by Junction Multimedia in Cambridge. In 2004, cheek was part of the BBC series Between the Ears, on the subject of speaking in tongues, in conversation with the artist and film-director Steve McQueen, exploring the boundaries of vocal expression with actress Billie Whitelaw, and linguistics professor William Samarin. cheek appears in the first episode talking about the many contradictory experiences of “dead air” in an age of changing media technologies.
Phantom Power also alchemizes the scholarship of co-host Mack Hagood (see Hush: Media and Sonic Self-Control forthcoming in March 2019 from Duke University Press and his 2012 SO! post “Listening to Tinnitus: Roles of Media When Hearing Breaks Down”) as well as his audio production background as a musician, producer, and radio DJ—skills he has long incorporated into his scholarship and teaching. At Indiana University, for example, he and his students and won the Indiana Society of Professional Journalists’ 2012 Best Radio Use of Sound award for our documentary series “I-69: Sounds and Stories in the Path of a Superhighway.” The first episode even featured music by Hagood and by Graeme Gibson, who was touring on drums with Michael Nau and the Mighty Thread at the time. Additional sound is by Cl0v3n.
“We spend a lot of time on the production aspects of this podcast,” says Hagood, “because we want it to be a sonic and affective experience, not just an intellectual one. Many of us in sound studies have complained that we always find ourselves writing about sound. Phantom Power is our attempt to treat sound not only as an object of study, but also a means of understanding and feeling sound scholarship. This makes our show very different from most academic podcasts, which are usually lo-fi discussions between scholars about recent books. We love that kind of podcast but we build upon it by using narrative, sound design, and music to tell a compelling story that we hope will appeal to the public and sound specialists alike.”
In addition to their exploration of “dead air,” Phantom Power’s inaugural season included longform interviews with urban scholar Shannon Mattern (Episode 2, “City of Voices”), sound artist Brian House (Episode 3, “Dirty Rat”), Australia-based sound composer, media artist and curator Lawrence English (Episode 4, “On Listening In” ), and with scholar and SO! ed Jennifer Stoever (Episode 5, “Ears Racing”). The final two episodes explored what “the future will sound like” on World Listening Day (July 18th) [Episode 6: Data Streams (Leah Barclay and Teresa Barrozo) and featured Houston’s SLAB car culture [Episode 7: Screwed & Chopped (Langston Collin Wilkins)].
“I’m super excited about Season Two,” says Hagood. “Our opener stars one of my favorite sound scholars, NYU’s Mara Mills. It also uses one of my favorite formats that cris and I have developed, where one of us brings in some crazy sounds for the other to listen and react to, then we gradually develop the backstory to the sounds through our guest’s words, eventually landing on the sonic and cultural implications of it all. It’s like a fun mystery, where one co-host acts as guide and the other gets to stand in for the listener—reacting, laughing, and questioning.”
When Phantom Power returns next month, other new entries will feature cheek’s interviews with Charles Hayward of legendary experimental rock band This Heat and poet Caroline Bergvall, whose work has been commissioned by such institutions as MoMA and the Tate Modern. “I interview amazing sound scholars, but I’m a bit star struck by some of the musicians, sound artists, and poets cris interviews!” says Hagood.
You can access Phantom Power and subscribe on a plethora of outlets: itunes, android, stitcher, google podcasts, and/or by email.
REWIND!…If you liked this post, you may also dig:
SO! Amplifies: Ian Rawes and the London Sound Survey–Ian Rawes
SO! Amplifies: Cities and Memory–Stuart Fowkes
SO! Amplifies: #hearmyhome and the Soundscapes of the Everyday–Cassie J. Brownell and Jon M. Wargo
Share this:

Technological Interventions, or Between AUMI and Afrocuban Timba
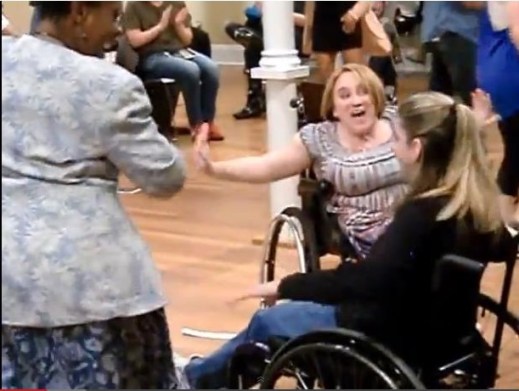
 Editors’ note: As an interdisciplinary field, sound studies is unique in its scope—under its purview we find the science of acoustics, cultural representation through the auditory, and, to perhaps mis-paraphrase Donna Haraway, emergent ontologies. Not only are we able to see how sound impacts the physical world, but how that impact plays out in bodies and cultural tropes. Most importantly, we are able to imagine new ways of describing, adapting, and revising the aural into aspirant, liberatory ontologies. The essays in this series all aim to push what we know a bit, to question our own knowledges and see where we might be headed. In this series, co-edited by Airek Beauchamp and Jennifer Stoever you will find new takes on sound and embodiment, cultural expression, and what it means to hear. –AB
Editors’ note: As an interdisciplinary field, sound studies is unique in its scope—under its purview we find the science of acoustics, cultural representation through the auditory, and, to perhaps mis-paraphrase Donna Haraway, emergent ontologies. Not only are we able to see how sound impacts the physical world, but how that impact plays out in bodies and cultural tropes. Most importantly, we are able to imagine new ways of describing, adapting, and revising the aural into aspirant, liberatory ontologies. The essays in this series all aim to push what we know a bit, to question our own knowledges and see where we might be headed. In this series, co-edited by Airek Beauchamp and Jennifer Stoever you will find new takes on sound and embodiment, cultural expression, and what it means to hear. –AB
—
In November 2016, my colleague Imani Wadud and I were invited by professor Sherrie Tucker to judge a battle of the bands at the Lawrence Public Library in Kansas. The battle revolved around manipulation of one specific musical technology: the Adaptive Use Musical Instruments (AUMI). Developed by Pauline Oliveros in collaboration with Leaf Miller and released in 2007, the AUMI is a camera-based software that enables various forms of instrumentation. It was first created in work with (and through the labor of) children with physical disabilities in the Abilities First School (Poughkeepsie, New York) and designed with the intention of researching its potential as a model for social change.
AUMI Program Logo, University of Kansas
Our local AUMI initiative KU-AUMI InterArts forms part of the international research network known as the AUMI Consortium. KU-AUMI InterArts has been tasked by the Consortium to focus specifically on interdisciplinary arts and improvisation, which led to the organization’s commitment to community-building “across abilities through creativity.” As KU-AUMI InterArts member and KU professor Nicole Hodges Persley expressed in conversation:
KU-AUMI InterArts seeks to decentralize hierarchies of ability by facilitating events that reveal the limitations of able-bodiedness as a concept altogether. An approach that does not challenge the able-bodied/disabled binary could dangerously contribute to the infantilizing and marginalization of certain bodies over others. Therefore, we must remain invested in understanding that there are scales of mobility that transcend our binary renditions of embodiment and we must continue to question how it is that we account for equality across abilities in our Lawrence community.
Local and international attempts to interpret the AUMI as a technology for the development of radical, improvisational methods are by no means a departure from its creators’ motivations. In line with KU-AUMI InterArts and the AUMI Consortium, my work here is that of naming how communal, mixed-ability interactions in Lawrence have come to disrupt the otherwise ableist communication methods that dominate musical production and performance.
The AUMI is designed to be accessed by those with profound physical disabilities. The AUMI software works using a visual tracking system, represented on-screen with a tiny red dot that begins at the very center. Performers can move the dot’s placement to determine which part of their body and its movement the AUMI should translate into sound. As one moves, so does the dot, and, in effect, the selected sound is produced through the performer’s movement.
Could this curious technology help build radical new coalitions between researchers and disabled populations? Mara Mills’s research examines how the history of communication technology in the United States has advanced through experimentation with disabled populations that have often been positioned as an exemplary pretext for funding, but then they are unable to access the final product, and sometimes even entirely erased from the history of a product’s development in the name of universal communication and capitalist accumulation. Therefore, the AUMI’s usage beyond the disabled populations first involved in its invention always stands on dubious historical, political, and philosophical ground. Yet, there is no doubt that the AUMI’s challenge to ableist musical production and performance has unexpectedly affected and reshaped communication for performers of different abilities in the Lawrence jam sessions, which speaks to its impressive coalitional potential. Institutional (especially academic) research invested in the AUMI’s potential then ought to, as its perpetual point of departure, loop back its energies in the service of disabled populations marginalized by ableist musical production and communication.
Facilitators of the library jam sessions, including myself, deliberately avoid exoticizing the AUMI and separating its initial developers and users from its present incarnations. To market the AUMI primarily as a peculiar or fringe musical experience would unnecessarily “Other” both the technology and its users. Instead, we have emphasized the communal practices that, for us, have made the AUMI work as a radically accessible, inclusionary, and democratic social technology. We are mainly invested in how the AUMI invites us to reframe the improvisational aspects of human communication upon a technology that always disorients and reorients what is being shared, how it is being shared, and the relationships between everyone performing. Disorientations reorient when it comes to our Lawrence AUMI community, because a tradition is being co-created around the transformative potential of the AUMI’s response-rate latency and its sporadic visual mode of recognition.

In his work on the AUMI, KU alumni and sound studies scholar Pete Williams explains how the wide range of mobility typically encouraged in what he calls “standard practice” across theatre, music, and dance is challenged by the AUMI’s tendency to inspire “smaller” movements from performers. While he sees in this affective/physical shift the opportunity for able-bodied performers to encounter “…an embodied understanding of the experience of someone with limited mobility,” my work here focuses less on the software’s potential for able-bodied performers to empathize with “limited” mobility and more on the atypical forms of social interaction and communication the AUMI seems to evoke in mixed-ability settings. An attempt to frame this technology as a disability simulator not only demarcates a troubling departure from its original, intended use by children with severe physical disabilities, but also constitutes a prioritization of able-bodied curiosity that contradicts what I’ve witnessed during mixed-ability AUMI jam sessions in Lawrence.
Sure, some able-bodied performers may come to describe such an experience of simulated “limited” mobility as meaningful, but how we integrate this dynamic into our analyses of the AUMI matters, through and through. What I aim to imply in my read of this technology is that there is no “limited” mobility to experientially empathize with in the first place. If we hold the AUMI’s early history close, then the AUMI is, first and foremost, designed to facilitate musical access for performers with severe physical disabilities. Its structural schematic and even its response-rate latency and sporadic visual mode of recognition ought to be treated as enabling functions rather than limiting ones. From this position, nothing about the AUMI exists for the recreation of disability for able-bodied performers. It is only from this specific position that the collectively disorienting/reorienting modes of communication enabled by the AUMI among mixed-ability groups may be read as resisting the violent history of labor exploitation, erasure, and appropriation Mills warns us about: that is, when AUMI initiatives, no matter how benevolently universal in their reach, act fundamentally as a strategy for the efficacious and responsible unsettling of ableist binaries.
The way the AUMI latches on to unexpected parts of a performer’s body and the “discrepancies” of its body-to-sound response rate are at the core of what sets this technology apart from many other instruments, but it is not the mechanical features alone that accomplish this. Sure, we can find similar dynamics in electronics of all sorts that are “failing,” in one way or another, to respond with accuracies intended during regular use, or we can emulate similar latencies within most recording software available today. But what I contend sets the AUMI apart goes beyond its clever camera-based visual tracking system and the sheer presence of said “incoherencies” in visual recognition and response rate.

Image by Ray Mizumura-Pence at The Commons, Spooner Hall, KU, at rehearsals for “(Un)Rolling the Boulder: Improvising New Communities” performance in October 2013.
What makes the AUMI a unique improvisational instrument is the tradition currently being co-created around its mechanisms in the Lawrence area, and the way these practices disrupt the borders between able-bodied and disabled musical production, participation, and communication. The most important component of our Lawrence-area AUMI culture is how facilitators engage the instrument’s “discrepancies” as regular functions of the technology and as mechanical dynamics worthy of celebration. At every AUMI library jam session I have participated in, not once have I heard Tucker or other facilitators make announcements about a future “fix” for these functions. Rather, I have witnessed an embrace of these features as intentionally integrated aspects of the AUMI. It comes as no surprise, then, that a “Battle of the Bands” event was organized as a way of leaning even further into what makes the AUMI more than a radically accessible musical instrument––that is, its relationship to orientation.
Perhaps it was the competitive framing of the event––we offered small prizes to every participating band––or the diversity among that day’s participants, or even the numerous times some of the performers had previously used this technology, but our event evoked a deliberate and collaborative improvisational method unfold in preparation for the performances. An ensemble mentality began to congeal even before performers entered the studio space, when Tucker first encouraged performers to choose their own fellow band members and come up with a working band name. The two newly-formed bands––Jayhawk Band and The Human Pianos––took turns, laying down collaboratively premeditated improvisations with composition (and perhaps even prizes) in mind. iPad AUMIs were installed in a circle on stands, with studio monitor headphones available for each performer.
Jayhawk Band’s eponymous improvisation “Jayhawks,” which brings together stylized steel drums, synthesizers, an 80’s-sounding floor tom, and a plucked woodblock sound, exemplifies this collaborative sensory ethos, unique in the seemingly discontinuous melding of its various sections and the play between its mercurial tessellations and amalgamations:
In “Jayhawks,” the floor tom riffs are set along a rhythmic trajectory defiant of any recognizable time signature, and the player switches suddenly to a wood block/plucking instrument mid-song (00:49). The composition’s lower-pitched instrument, sounding a bit like an electronic bass clarinet, opens the piece and, starting at 00:11, repeats a melodically ascending progression also uninhibited by the temporal strictures of time signature. In fact, all the melodic layers in “Jayhawk,” demonstrate a kind of temporally “unhinged” ensemble dynamic present in most of the library jam sessions that I’ve witnessed. Yet unexpected moves and elements ultimately cohere for jam session performers, such as Jayhawk Band’s members, because certain general directions were agreed upon prior to hitting “record,” whether this entails sound bank selections or compositional structure. All that to say that collective formalities are certainly at play here, despite the song’s fluid temporal/melodic nuances suggesting otherwise.
Five months after the battle of the bands, The Human Pianos and Jayhawk Band reunited at the library for a jam session. This time, performers were given the opportunity to prepare their individual iPad setup prior to entering the studio space. These customized setup selections were then transferred to the iPads inside the studio, where the new supergroup recorded their notoriously polyrhythmic, interspecies, sax-riddled composition “Animal Parade”:
As heard throughout the fascinating and unexpected moments of “Animal Parade,” the AUMI’s sensitivity can be adjusted for even the most minimal physical exertion and its sound bank variety spans from orchestral instruments, animal sounds, synthesizers, to various percussive instruments, dynamic adjustments, and even prefabricated loops. Yet, no matter how familiar a traditionally trained (and often able-bodied) musician may be with their sound selection, the concepts of rhythmic precision and musical proficiency––as they are understood within dominant understandings of time and consistency––are thoroughly scrambled by the visual tracking system’s sporadic mode of recognition and its inherent latency. As described above, it is structurally guaranteed that the AUMI’s red dot will not remain in its original place during a performance, but instead, latch onto unexpected parts of the body.
Simultaneously, the dot-to-movement response rate is not immediate. My own involvement with “the unexpected” in communal musical production and performance moulds my interpretation of what is socially (and politically) at work in both “Jayhawks” and “Animal Parade.” While participating in AUMI jam sessions I could not help but reminisce on similar experiences with the collective management of orientations/disorientations that, while depending on quite different technological structures, produced similar effects regarding performer communication.
Being a researcher steeped in the L.A. area Salsa, Latin Jazz, and Black Gospel scenes meant that I was immediately drawn to the AUMI’s most disorienting-yet-reorienting qualities. In Timba, the form of contemporary Afrocuban music that I most closely studied back in Los Angeles, disorientations and reorientations are the most prized structural moments in any composition. For example, Issac Delgado’s ensemble 1997 performance of “No Me Mires a Los Ojos” (“Don’t Look at Me In the Eyes”)– featuring now-legendary performances by Ivan “Melon” Lewis (keyboard), Alain Pérez (bass), and Andrés Cuayo (timbales)—sonically reveals the tradition’s call to disorient and reorient performers and dancers alike through collaborative improvisations:
Video Filmed by Michael Croy.
“No Me Mires a los Ojos” is riddled with moments of improvisational coalition formed rather immediately and then resolved in a return to the song’s basic structure. For listeners disciplined by Western musical training, the piece may seem to traverse several time signatures, even though it is written entirely in 4/4 time signature. Timba accomplishes an intense, percussively demanding, melodically multifaceted set of improvisations that happen all at once, with the end goal of making people dance, nodding at the principle tradition it draws its elements from: Afrocuban Rumba. Every performer that is not a horn player or a vocalist is articulating patterns specific to their instrument, played in the form of basic rhythms expected at certain sections. These patterns and their variations evolved from similar Rumba drum and bell formats and the improvisational contributions each musician is expected to integrate into their basic pattern too comes from Rumba’s long-standing tradition of formalized improvisation. The formal and the improvisational function as single communicative practice in Timba. Performers recall format from their embodied knowledge of Rumba and other pertinent influences while disrupting, animating, and transforming pre-written compositions with constant layers of improvisation.
What ultimately interests me the most about the formal registers within the improvisational tradition that is Timba, is that these seem to function, on at least one level, as premeditated terms for communal engagement. This kind of communication enables a social set of interactions that, like Jazz, grants every performer the opportunity to improvise at will, insofar as the terms of engagement are seriously considered. As with the AUMI library jam sessions, timba’s disorientations, too, seem to reorient. What is different, though, is how the AUMI’s sound bank acts in tandem with a performer’s own embodied musical knowledge as an extension of the archive available for improvisation. In Timba, the sound bank and knowledge of form are both entirely embodied, with synthesizers being the only exception.
Timba ensembles and their interpretations of traditional and non-Cuban forms, like the AUMI and its sound bank, use reliable and predictable knowledge bases to break with dominant notions of time and its coherence, only to wrangle performers back to whatever terms of communal engagement were previously decided upon. In this sense, I read the AUMI not as a solitary instrument but as a partial orchestration of sorts, with functions that enable not only an accessible musical experience but also social arrangements that rely deeply on a more responsible management of the unexpected. While the Timba ensemble is required to collaboratively instantiate the potential for disorientations, the AUMI provides an effective and generative incorporation of said potential as a default mechanism of instrumentation itself.

Image from “How do you AUMI?” at the Lawrence Public Library
As the AUMI continues on its early trajectory as a free, downloadable software designed to be accessed by performers of mixed abilities, it behooves us to listen deeply to the lessons learned by orchestral traditions older than our own. Timba does not come without its own problems of social inequity––it is often a “boy’s club,” for one––but there is much to learn about how the traditions built around its instruments have managed to centralize the value of unexpected, multilayered, and even complexly simultaneous patterns of communication. There is also something to be said about the necessity of studying the improvisational communication patterns of musical traditions that have not yet been institutionalized or misappropriated within “first world” societies. Timba teaches us that the conga alone will not speak without the support of a community that celebrates difference, the nuances of its organization, and the call to return to difference. It teaches us, in other words, to see the constant need for difference and its reorganization as a singular practice.
The work started with the AUMI’s earliest users in Poughkeepsie, New York and that involving mixed-ability ensembles in Lawrence, Kansas today is connected through the AUMI Consortium’s commitment to a kind of research aimed at listening closely and deeply to the AUMI’s improvisational potential interdisciplinarily and undisciplinarily across various sites. A tech innovation alone will not sustain the work of disrupting the longstanding, rooted forms of ableism ever-present in dominant musical production, performance, and communication, but mixed-ability performer coalitions organized around a radical interrogation of coherence and expectation may have a fighting chance. I hope the technology team never succeeds at working out all of the “discrepancies,” as these are helping us to build traditions that frame the AUMI’s mechanical propensity towards disorientation as the raw core of its democratic potential.
—
Featured Image: by Ray Mizumura-Pence at The Commons, Spooner Hall, KU, at rehearsals for “(Un)Rolling the Boulder: Improvising New Communities” performance in October 2013.
—
Caleb Lázaro Moreno is a doctoral student in the Department of American Studies at the University of Kansas. He was born in Trujillo, Peru and grew up in the Los Angeles area. Lázaro Moreno is currently writing about methodological designs for “the unexpected,” contributing thought and praxis that redistributes agency, narrative development, and social relations within academic research. He is also a multi-instrumentalist, composer, and producer, check out his Soundcloud.
—
REWIND! . . .If you liked this post, you may also dig:
Introduction to Sound, Ability, and Emergence Forum –Airek Beauchamp
Unlearning Black Sound in Black Artistry: Examining the Quiet in Solange’s A Seat At the Table — Kimberly Williams
Experiments in Agent-based Sonic Composition — Andreas Duus Pape
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments