
El Llanto Against I.C.E.: Toward a Latinx Sonic Phenomenology of the Dignified Cry

DOI: https://doi.org/10.59350/xgm8r-acg57
It is July 4, 2025. The air is hot; the sun is beaming on concrete and asphalt. Sweat is accumulating on my cotton Disrupt band t-shirt. My skin is sticky. Inside a suffocating room, the volume penetrating my ears is the racket of voices producing a steady pulsation of disunified sounds. A brown noise. In a studio room in Boyle Heights, the acoustics create a space-time of rebellious gravity. There’s something gestating. We are in that in-between aural space, the time-lag between speaker, musician, or performance. The MC is letting the crowd know what is next. We all desired to know.
Yaotl—the vocalist of Xicano hip-hop/punk group Aztlán Underground—is the MC. He is speaking to the crowd during that transition to the next set. Doing so, Yaotl used this exact instance to identify the political moment we were all witness to, the historical cause for the event here, and then, surprising everyone, facilitated a collective llanto. He called it “scream therapy.” The dignified cry, as I am calling it, for him, is sticky, piercing, and angry—a sonorous form of dignified rage. We are all here for Xican@ Records and Film annual cultural event, the Farce of July that hosts vendors and musicians. Yaotl readies the crowd, his contagious call for a llanto also fused with the intimate violences of coloniality, what decolonial theorists of modernity, such as semiotician Walter Mignolo, have called its darker side or underside. “I want everyone to scream your fucking rage against all this shit.” He counts to three. One. Two. Three. We scream. We yell. We cry and cry out together. We manifest the sound of el llanto.

Gritos, llantos, sonidos, caos, and roncas are not new in Latinx Sound Studies. Their history, particularly in Latinx cultural studies, is intimate with the genealogy of not only musical or popular cultural forms (think rancheras in Mexico) but ancestral ceremony, rituals, and mythic stories (like La Llorona). From the invasion of Mexico-Tenochtitlan by Cortés in 1519 to the sonic protest of the 2018 Llanto Colectivo against the Otay Mesa Detention Center in San Diego, we can adequately identify the historically loud opposition against racism and coloniality in the United States. I explore the function of el llanto in relationship to a generalized response to the fascist sequences of repression emerging in the United States, showing how llantos orient both the listener and participant toward a discernment of grief and catharsis. This twofold function facilitates an embodied practice of corporeal sound-making and its therapeutic effect, which I ground here as a form of affective suture. Suffering, transmuted into coraje (angry-tinged courage), generates a collective sounding that pulls listeners into the acoustic llanto. In doing so, it transforms the listener into an agent of dignified rage.
Theorizing llantos requires a Latinx sound and listening methodology grounded in sonic phenomenology—drawing from phenomenological and sound studies traditions—that develop an “acoustic perception” sensitive to the “sonic environment.” I contribute to the notes toward a Latinx listening methodology introduced by Wanda Alarcón, Dolores Inés Casillas, Esther Díaz Martín, Sara Veronica Hinojos, and Cloe Gentile Reyes, who affirm faithful listening as, “attuned not only to sound, but to histories, structures, and acts of refusal that resist dehumanization.” Historically, phenomenologists have privileged the visual phenomenal field, the primacy of visuality being the ocular sense to discern or disclose the meaning of consciousness and lived experience. The sonic phenomenologist tunes into the soundscape as the totality of the aural experience.
The sonic phenomenologist of el llanto, or the dignified cry, develops a decolonial listening technique to perceive the aural structure of coloniality, the audition of dispossession mediated by anti-migrant animus, and the desire for emancipation from such sonic hauntings in everyday life. Many who let out a llanto do so in the face of anti-immigrant, anti-Latinx racism. It emerges as a vocal response to coloniality as lived and enforced through everyday regimes of racialized governance, from linguistic profiling and labor precarity to the slow violence of immigration delay and the spectacle of public kidnappings.
The collective llanto in July came at a time when in Los Angeles, California a popular revolt broke out in the early days of June amongst dissenters against I.C.E. raids and the Trump administration’s deployment of the National Guard to the streets. The spectacle, of a Xicano hip-hop/punk ensemble inviting a collective llanto, became much more than the cacophony of discordant screams but the dissensus of an aggrieved community. In their grief, mediated by the capture, detainment, and transport of undocumented migrants to detention centers, the catharsis of a llanto fueled the connection between desire and social movement. The sounds exiting the body, resonating as vibration in a shared room, identified the mutual feelings of others, in the exhalation of a noisy, impulsive breath.
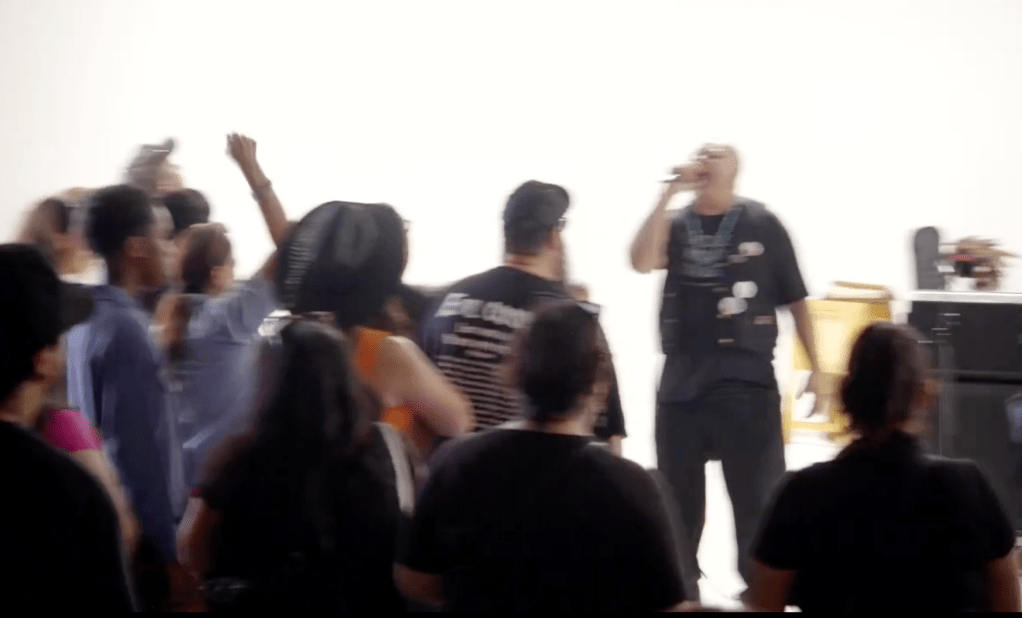
This was not euphoria.
This instance of a rageful cry—loud, infectious, piercing – builds on the “faithful witnessing” articulated by María Lugones and Yomaira Figueroa-Vásquez, disclosing collective anguish fused with a tender fury. The listener must resist the organization of the dignified cry as melodic, rhythmic, or joyful. Rather, the llanto disturbs, ruptures, and erupts as a thunderous dissonance. Its saturation of auditory space interrupts the experience of conviviality or seriality and enchants the temporal form of the ensemble where the participants disappear behind the guttural and raucous sounds.
Faithful listening not only decolonizes racializing sonic structures but amplifies resistance, revolt, and coraje. Llantos are spontaneous, organized, lived. To voice el llanto is to become el llanto; an affective suture where a new auditory imaginary links with the Xicanacimiento of Yaotl’s specificity. Llantos, thus, are particular vocal moments continually shaped and fashioned. For the critical Latinx listener, el llanto offers a few seconds of catharsis and collective grief.
—
Featured Image: Aztlan Underground en Tenochtitlán by Flickr User Joél Martínez CC BY-NC-SA 2.0
—
Kristian E. Vasquez is a Ph.D. candidate in the Department of Chicana and Chicano Studies at the University of California, Santa Barbara. His research on the affects, performances, sounds, and semiosis of La Xicanada expands the concept of Xicanacimiento, centering the aesthetic force of expressive cultural forms in California.
—
.

REWIND!…If you liked this post, you may also dig:
Boom! Boom! Boom!: Banda, Dissident Vibrations, and Sonic Gentrification in Mazatlán—Kristie Valdez-Guillen
Listening to MAGA Politics within US/Mexico’s Lucha Libre –Esther Díaz Martín and Rebeca Rivas
Ronca Realness: Voices that Sound the Sucia Body—Cloe Gentile Reyes
Echoes in Transit: Loudly Waiting at the Paso del Norte Border Region—José Manuel Flores & Dolores Inés Casillas
Share this:

The Absurdity and Authoritarianism of Now: My Chemical Romance’s The Black Parade Resonates Queerly, Anew

DOI: https://doi.org/10.59350/g8byn-fea85
My Chemical Romance fans are speculating about new music after the band wiped their X account clean and wrapped up the Latin America leg of their tour this month. Whether another album is on the way or not, MCR’s magnum opus – The Black Parade – continues to endure two decades later. The sound now resonates through MCR’s commentary on fascism, critiquing the nation while holding the crowd accountable for our participation or passivity.
As the band tours The Black Parade for its 20th anniversary, the members have rejected nostalgia in favor of a new storyline, playing alter-ego characters who have been conditioned to perform for a dictator. The plot, slightly shifting night to night, encourages fans to follow along.
In the first run of the tour, each concert paused midway for an “election.” Four hooded figures walked out to the center stage. Nearby, an army official watched. Singer Gerard Way asked the audience to vote: Support these candidates or reject them? Each person in the crowd had a sign. One side: YEA. The other side: NAY.
“Now we need to hear you,” Way says. The audience roars, jeering and cheering.
No matter the spectators’ will, the result is the same: execution.
The warped election – and the sound of The Black Parade – reflects the absurdism of authoritarianism. Here is a democracy that ends in death, regardless of how you vote. Viewers log into livestreams to watch the fanfare repeat.
MCR’s commentary echoes the ramping authoritarianism and upheaval in the United States:
- The Supreme Court cleared the way for immigration agents to use race as a reason to stop and check someone’s citizenship documents. Daily ICE arrests reached a decade high last year. 2025 also marked the deadliest year for people in ICE custody in two decades.
- Protests have swept the nation, with outrage further increasing after federal agents killed two Minneapolis demonstrators this January.
- Cuts and changes to Medicaid and SNAP are on their way. The longest government shutdown also ended without extending subsidies for health care.
- The Epstein files were released, showing ties between powerful leaders and sex offender Jeffrey Epstein.
- The Department of Governmental Efficiency, named after an outdated Internet meme (DOGE), has resulted in the elimination of at least 290,000 jobs.
- The U.S. withdrew from the Paris Agreement and World Health Organization. The country also pulled out of 66 international organizations.
- Trump continues to enact steep tariffs after a Supreme Court ruling against his policy.
- Layoffs soared past 1.1 million job cuts in 2025, the highest since 2020’s COVID-19 shutdown.
This list represents a fraction of stories and executive orders in 2025; a “flood the zone” strategy overwhelmed the news cycle. Despite censorship efforts – such as the federal defunding of NPR and PBS – much of this information is available to us at the click of a button. State-sanctioned propaganda even encourages the spectacle. Just take a look at footage of ICE raids on the WhiteHouse’s TikTok account, set to songs and images of pop stars:
Yet fatigue and fearmongering keep many complacent; looming economic crises also draw our attention and time. I do not mean to diminish people’s efforts of resistance. But I am interested in the way technology has expanded our potential to witness violence, without ever requiring us to act – as well as the power of entertainment to distract.
So I turn back to MCR’s spectacle, which twists and mirrors this descent into fascism. Up against the tour’s faux-executions, the boos and the cheers of the crowd collapse into a cacophony. I locate the sound of our times within these screams, where dissent seems to go unheard and melds into the chorus of support.
The Black Parade is full of these bombastic wails, but the most intense of them are in “Mama,” a song that balloons into an extended eight-minute performance in the Long Live the Black Parade Tour. Within “Mama,” I try to make some sense of these screams, finding queer resonance with the present moment.
With my analysis, I ask: How might we hold fascist figures to account without squirming out of our own role in the daily exchange of authoritarianism? I argue My Chemical Romance’s 2025-2026 performance of “Mama” highlights structures of violence but also criticizes our participation within them.
In “Mama,” the indulgence of sin is contagious. It’s loud. It’s repeated: “Mama, we all go to hell.” This refrain, set to a polka beat, creates an abject intimacy around our shared fate. Queer listeners have interpreted this song as an angry anthem against the rejection we face from our families and dogmatic religion. For those of us who have heard, “You’re going to hell,” the response, “We all go to hell,” serves as a relief. Verses like “You should’ve raised a baby girl, I should’ve been a better son” have been reclaimed by transgender fans.
Other fans have taken issue with these interpretations, arguing queer attachments distract from the “true” meaning of the song. Indeed, “Mama” tells the story of a soldier writing from the trenches of war, while his mother judges him from afar. But I argue that by placing a queer reading in tandem with the canonical narrative, generative meanings emerge. Queer theory provides tools to understand the role of the mother here. Mama is the title of the song. Mama is pervasive. Mama is mean. Mama is on his mind. But she is also almost entirely absent, avoiding accountability for her son’s violence and instead blaming him: “She said, ‘You ain’t no son of mine.’”
The soldier finds that the trenches are not just his domain, but also his mama’s: “Mama, we’re all full of lies…And right now, they’re building a coffin your size.” His plea to his mother helps us wonder: What about the culture that birthed this violence? In this metaphor, critiquing the mother extends to critiquing the nation.
At the climax of the song, these sentiments come through screams: 30 seconds of an extended, “AHHHHHH” and a crying out of, “Mama, Mama, Mama.” In these wails, I find a soldier begging to share responsibility with his motherland, even as he contends with his own role in the violence. The cries puncture the polka, demonstrating “Mama” is not a celebration, after all.
Mama only sings one line back, through the voice of theater icon Liza Minnelli: “And if you would call me a sweetheart/I’d maybe then sing you a song.” Minnelli’s voice connects the song’s sound to her role in Cabaret, a musical which mixes together queer aesthetics and indulgent decadence with a foreboding rise of fascism. This allusion to Cabaret, as well as the tour performance, serve as a reminder: pleasure and entertainment does not always equal resistance.
In the extended version of “Mama” on tour, these lines are sung by an opera singer, whose voice, too, serves the dictator. Preceding her performance, the song briefly opens up a space for resistance. A new section of the song, debuted on the tour, includes the lyrics:
A dagger, a dagger
Please fetch me a dagger
A tool for our treasonous needs…
With tears in our eyes we collapse on the crosses
And said death be the son of us all
This war is the son of us all.
Even as Gerard Way’s character plots treason against the dictator, these new lyrics make clear: this “death” and “war” is “the son of us all.” Though we might want to pin fascism on one figure, many Americans have participated in the creation of this “death/war.” There are fatal consequences for our collective actions – or our passivity.
Ultimately, the dramatics of this song, delivered like a sinister weapon, critique violence, while ironically trapping us in its pleasures. If prayer is crying out to our father who art in heaven, “Mama” is yelling back at our mother to bring her to where she belongs: the hell in which we both exist. Given the stakes of our political moment, I argue we need to scream louder, with purpose and strategy, against our motherland.
—
Featured Image: “My Chemical Romance Live at T-Mobile Park 6/11/25,” Image by Flickr User Laura Smith CC BY-ND 4.0
—
Max Lubbers (he/she) is a first-year PhD student in the American Studies and Ethnicity department at the University of Southern California. His research centers on transgender affects and sounds. Max earned a bachelor’s degree in Journalism and Gender and Sexuality Studies from Northwestern University, with a senior thesis on butch affect. She previously worked as a journalist, with pieces in Chicago’s NPR station, Colorado Public Radio, and Windy City Times.
—

REWIND!…If you liked this post, check out:
The Sounds of Equality: Reciting Resilience, Singing Revolutions–Mukesh Kulriya
Vocal Anguish, Disinformation, and the Politics of Eurovision 2016–Maria Sonevytsky
“To Unprotect and Subserve:” King Britt Samples the Sonic Archive of Police Violence —Alex Werth
Share this:






Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments