
Robin Williams and the Shazbot Over the First Podcast

Histories of technology have politics. The way we discuss the emergence and development of media technologies implicates the priorities and interests of those telling the story, and how we understand a technology’s meaning and potential.
Among podcasters familiar with the history of the medium, Dave Winer– the developer behind the RSS feed –is usually credited as the progenitor of the form. This past summer, however, this narrative was challenged by Podnews editor James Cridland–(good naturedly, I presume)–who suggested that the comedian Robin Williams may actually have been the first podcaster, predating Winer’s RSS (“Rich Site Summary,” or “Really Simple Syndication”) distribution model by a few months. These origin stories have important technical differences that lead to political repercussions: the Winer narrative envisions podcasting as open and decentralized, and therefore theoretically an inherently emancipatory technology. The Williams narrative, in contrast, locates the birth of the medium within a closed, corporate-controlled platform – which just might mean there’s nothing inherrently open or democratic about internet-distributed audio content at all.
Though both perspectives are undoubtedly “great white man” visions of the medium’s history–or more precisely versions of Susan Douglas’s “inventor-hero”–what’s particularly interesting here is how both views implicate a politics of what podcasts are and what they ought to be. Although this quarrel was a dispute between colleagues that was ultimately abandoned, I argue it’s well worth a deeper examination, as the ideological conflict at its center isn’t just about the past, but rather competing visions of podcasting’s future – over the continued flourishing or gradual eclipse of RSS.
Indeed, debates over the technical definition of a podcast, and over who was—and who was not–the first podcaster based on that definition, reveal anxieties among long-time podcasters and developers about corporate consolidation in the industry as well as the apparent irrelevance of technical distinctions to listeners and creators who may not appreciate the way in which walled gardens negate the very thing that makes podcasting so special. Likewise, to suggest that podcasting may have first emerged as a proprietary form may retroactively justify corporate platform enclosures in the present. And, though I’m just as suspicious of corporate hegemony as the next person, nuancing the early history of the medium can help us think through the distinctions between technology and cultural form.
In the consensus version of podcasting’s history, the emergence of the medium is typically traced to software developer Dave Winer’s publication – with significant contribution from the former MTV VJ and Internet entrepreneur Adam Curry– of RSS (“Rich Site Summary,” or “Really Simple Syndication”) version 0.92 in December 2000, which allowed for the distribution of digital audio files. The first podcast feed followed in January 2001, and, with the launch of Curry’s iPodder podcast aggregator and his program Daily Source Code in 2004, podcasting began to coalesce as both technology and cultural form. In the 20-odd years since, the medium’s technical infrastructure has remained essentially unchanged: RSS continues to be the predominant format of podcast syndication.

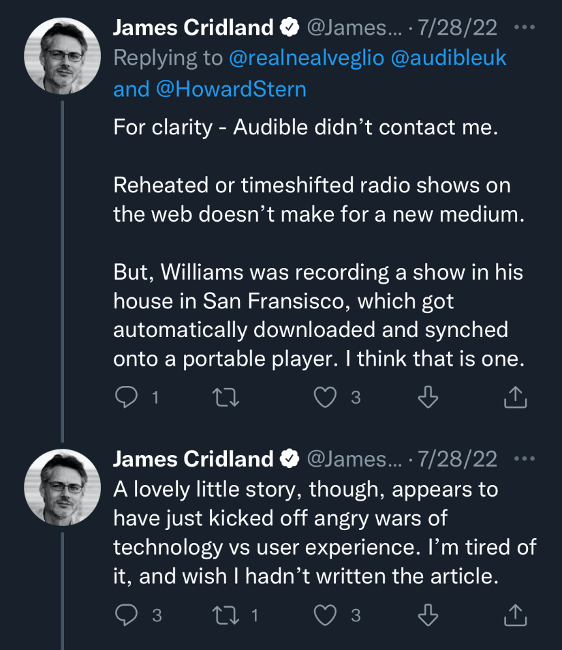
So this past July, when Podnews editor James Cridland cheekily suggested that it was not Dave Winer, nor “the podfather” Adam Curry, but comedian Robin Williams who had actually been the world’s first podcaster, industry graybeards were quick to push back on his claim.
Cridland’s argument went like this: As an early investor in Audible.com, Williams launched a bi-weekly talk show called RobinWilliams@Audible in early 2000 (several months before Winer’s pioneering RSS), which listeners could download onto their mp3 players. Subscribers who owned an Audible Mobile Player could even have RobinWilliams@Audible automatically pushed to their device. “Of course, that’s what the first podcast was, too,” Cridland noted, “something you downloaded to your computer, then synched to your mp3 player.”
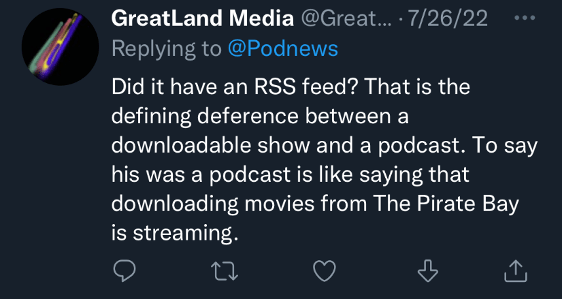
The crucial distinction, however, was that RobinWilliams@Audible was not distributed via RSS. For some, this meant that the show was definitively not a podcast – and Cridland’s claim patently absurd.
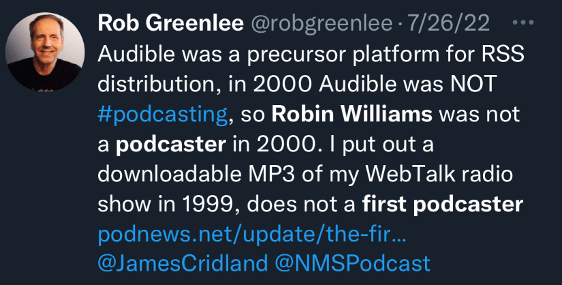
On The New Media Show, for instance, Todd Cochrane, founder-CEO of Blubrry, and Rob Greenlee, VP of Libsyn, spent nearly eighteen minutes on the subject, recounting the early history of online file sharing and concluding that a podcast could only be a podcast if it used RSS. For Audible to suggest that they had been the first in podcasting (Cridland’s post relied in part on Audible founder Don Katz as a source) was ego-driven revisionism.
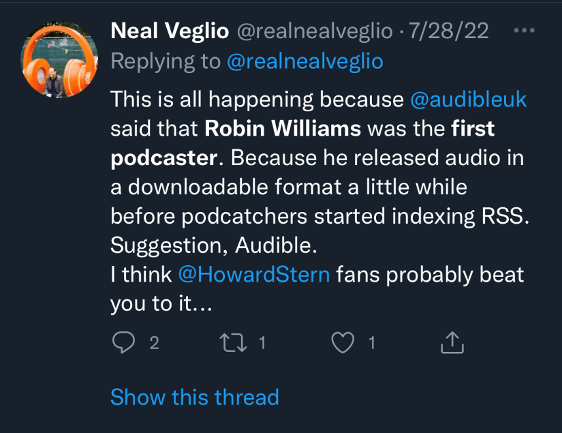
On Twitter (an ancient social media app where people used to go to eviscerate each other), Cridland’s article provoked a squall of exceptions, which generally argued that downloadable audio without RSS does not a podcast make; and though Audible’s platform may have been innovative, and even shared some characteristics with podcasting, the fact that its programs were limited to the company’s proprietary platform meant that they were definitively not podcasts.
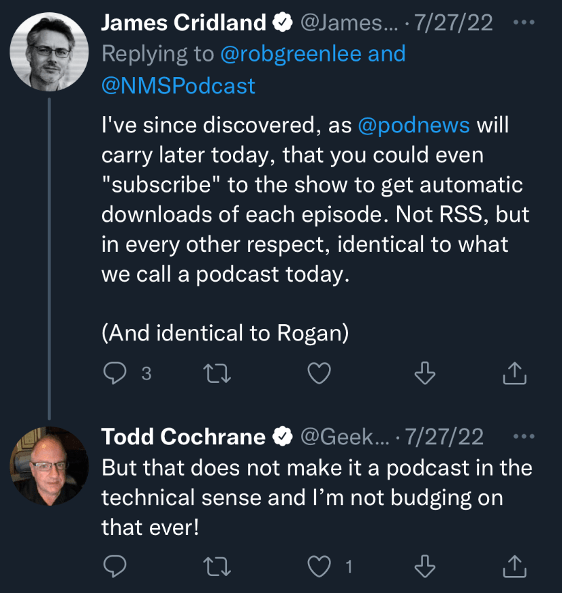
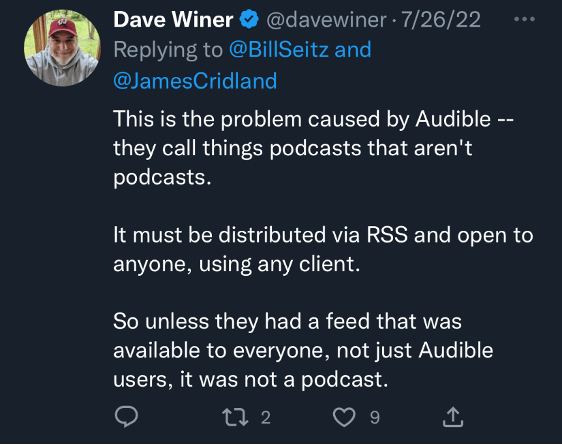
Rob Greenlee, for example, replied to Cridland’s article by clarifying that Audible was a precursor platform for RSS, but that its audio programs were definitively not podcasting. When Cridland pushed back, noting the automatic download feature on Audible, Greenlee’s co-host Todd Cochrane replied that this feature still did not make RobinWilliams@Audiblea podcast; and he insisted that he wasn’t going to budge on this point. A minor flap ensued, which ended with Cridland resignedly saying that he wished he had never written the article in the first place.In the end, even Dave Winer got involved, arguing that a piece of downloadable audio media had to have an RSS feed and be open to anyone, using any client, to qualify as a podcast.
To get a sense of the response to Cridland’s article on Twitter, and to let participants speak for themselves, I have selected a sampling of replies to Cridland’s original tweet teasing the article and reproduced them below. The conversation is arranged roughly in chronological order.

Admittedly, this was a very niche dispute – a handful of predominantly white tech dudes arguing over which white dude(s) had been the first podcaster. After a day or two, they all moved on.
But however minor (and however much Cridland may have wished he hadn’t written the article), the flap over RobinWilliams@Audible is a useful lens with which to understand contemporary debates over the future of podcasting: about whether the decentralized and open RSS-based ecosystem will long endure, or whether walled gardens—“limited set[s] of technology or media information provided to users with the intention of creating a monopoly or secured information system“—will prevail.
To better understand, however, let’s back up a bit.
By the fall of 2000, Dave Winer had earned a reputation as a pioneer of web syndication – he had been credited with launching the first blog – and someone who, according to the podcaster and author Eric Nuzum, “believed in making systems open, democratic, and easily accessible,” pushing back against the trend toward centralization and proprietary control of Internet infrastructures.

On a trip to New York that October, Winer met up with Adam Curry, who had been closely following his work. Over several hours in Curry’s hotel room, the entrepreneur attempted to convince Winer that web syndication technologies could be leveraged to distribute audio and video files – a vision of the Internet as “Everyman’s broadcast medium” – if only the so-called “last yard” problem of slow DSL connections could be resolved. By his own admission, Winer at first didn’t quite understand what Curry had in mind, but he was open experimenting with using RSS as “virtual bandwidth” that could deliver large media files during off-peak hours. In January 2001, Winer successfully used an RSS enclosure tag to distribute a single Grateful Dead song (it was U.S. Blues), inaugurating the first podcast feed – though what he had created wouldn’t become known as a “podcast” for some time.
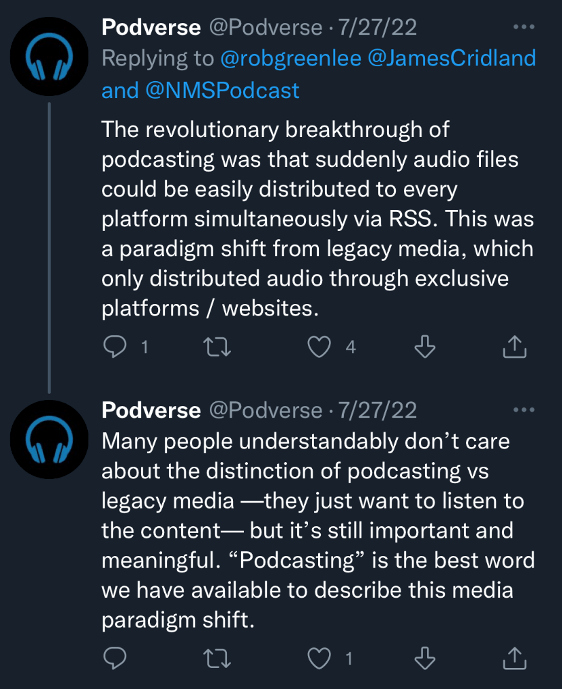
Though interest in RSS-delivered audio files was slow to develop (indeed, even Winer and Curry pursued other projects for a time), “it was not lost on … early adopters,” as Andrew Bottomley has observed, adding “that the technology shifted power to the audience and also opened up opportunities for more democratized radio production” (111-112). The days of corporate gatekeepers exercising oligopolistic control over the production and distribution of audio content seemed numbered; no longer would broadcasting be subject to an economy of scarcity. Theoretically anyone with web hosting, a microphone, and an RSS feed could set themselves up in the radio business.
Since those early days, RSS has become “the currency of podcasting,” to borrow a phrase from Dave Jones, Adam Curry’s Podcasting 2.0 collaborator. Indeed, as Cridland himself wrote in his primer, “What is a Podcast?,” technically speaking, a “podcast” is comprised of an audio file, without DRM restrictions, that is available to download, and is “distributed via an RSS feed using an <enclosure> tag.”
But RSS is not without its detractors. Last July, for instance, Anchor.fm co-founder Michael Mignano argued that while technical standards like RSS (or HTTP, or SMTP, or SMS) provide a “common language” that allows for the rapid spread of new technologies, standardization inevitably stifles growth. “The tradeoff,” he wrote, “is that a lower barrier to entry means more products get created in a category, causing market fragmentation and ultimately, a slow pace of innovation.” The consequence of this “Standards Innovation Paradox” is that even as podcast listening apps proliferate, because they must conform to the RSS standard, the differences between them are superficial. Proprietary systems, Mignano argued, offer an alternative, allowing developers the flexibility to build – and rapidly improve – dynamic user experiences.
Naturally, Mignano pointed to Spotify – which acquired Anchor in 2019 – as an example of how closed systems could break the “curse” of standardization: When the company began to expand from music to other forms of audio content, he wrote, there was some speculation that the company would launch a dedicated podcast app. But, “if they had done so, they’d have to contend with the aforementioned ocean of podcast listening apps which were all offering users roughly the same features that were limited by the standard.” Instead, “Spotify used their existing music user base inside of the existing Spotify app to distribute podcasts to hundreds of millions of users.”

But this framing soft pedals Spotify’s aggressive attempts to steer podcasting away from RSS and toward platform enclosure. As John L. Sullivan argued in a 2019 paper, Spotify’s emphasis on exclusive releases (which has included the removal of content previously available via RSS, like The Joe Budden Podcast), and its $340 million acquisitions of Anchor and Gimlet are all part of an effort to control distribution and “maximize the ‘winner take all’ functions of platforms.” More recently, Anchor has stopped automatically generating an RSS feed at the time of publication, making it an opt-in function (meaning that creators have to know what RSS is to have their podcast distributed to directories otherthan Spotify). “We’ve been able to replace RSS for on-platform distribution,” noted one Spotify executive at a recent investor event, “which means that podcasts created on our platform are no longer held back by this outdated technology.”

Given the challenges that platform enclosure poses to RSS, its defenders’ insistence that “it’s not a podcast if it doesn’t have an RSS feed, and it’s not a podcast app if you can’t add your own RSS feeds,” as an episode title of Curry and Jones’s Podcasting 2.0 puts it, is understandable. Or, as Cochrane declared on The New Media Show, “until you tear my RSS feed through my dead hands, podcasts technically are podcasts that are delivered via RSS.”
And understandable, too, is the prickly reaction to Cridland’s alternate history: To claim that RobinWilliams@Audible may have been the first podcast is to suggest that RSS – and the open and democratic values which it represents – are inessential; and more troubling, that proprietary systems are deeply rooted in the history of the medium.

Of course, there’s also the sticky fact that RobinWilliams@Audible premiered before the word “podcast” entered the lexicon. But even this history is messy. In his original coinage, the technologist Ben Hammersley applied the term to a variety of different forms of downloadable audio media, including Audible originals like In Bed with Susie Bright. According to this early conception, in other words, podcasting described a cultural practice rather than a specific distribution infrastructure.
It is likely, too, that technological distinctions are irrelevant to listeners. Citing data from Edison Research showing that a significant percentage of listeners use Spotify and YouTube to access podcasts (even though content on these platforms don’t meet the strict technical definition of a “podcast”), Cridland has suggested that, for most people, podcasting is simply “on-demand audio. Like a radio show, but on-demand.”
Likewise, the question of whom the first podcaster was is of narrow interest. “Who cares?” an exasperated Cochrane finally concluded.
But reviewing the pre-2004 history of downloadable audio media can open up questions of the interpretive flexibility of technology (how technological artifacts come to have different meanings for different groups of users) and rhetorical closure (when the need for alternative designs diminish) that the late Trevor Pinch and Wiebe Bijker identified as key concepts in the Social Construction of Technology.
And so, rather than arguing about whether RobinWilliams@Audible – or, for that matter, Cochrane’s audio file sharing on FidoNet in the early 1990s – was the “first” podcast, further examination of this complex genealogy suggests the more interesting questions of how and why online distribution of audio files was such a desirable goal that there were severalpaths to its development.
The flap over Robin Williams and the question of the first podcaster also gives us much needed insight into current discourse about corporate influence in the podcasting space. Also It provided a way for proponents of the decentralized Podcasting 2.0 movement to make a technological distinction between a desire for freedom and a desire for control. While the scuffle itself was short-lived, its dust is far from settling.
—
Featured Image of Robin Williams (2008) by Flickr User Shameek (CC BY-NC-ND 2.0)
—
Andrew J. Salvati is an adjunct professor in the Media and Communications program at Drew University, where he teaches courses on podcasting and television studies. His research interests include media and cultural memory, television history, and mediated masculinity. He is the co-founder and occasional co-host of Inside the Box: The TV History Podcast, and Drew Archives in 10.
—

REWIND! . . .If you liked this post, you may also dig:
“I am Thinking Of Your Voice”: Gender, Audio Compression, and a Cyberfeminist Theory of Oppression: Robin James
DIY Histories: Podcasting the Past: Andrew Salvati
SO! Podcast #2: Behind the Podcast: Building Intimate Venues on the Internet – Andreas Duus Pape
Share this:

Stir It Up: From Polyphony to Multivocality in A Brief History of Seven Killings

 For many, the audiobook is a source of pleasure and distraction, a way to get through the To Read Pile while washing dishes or commuting. Audiobooks have a stealthy way of rendering invisible the labor of creating this aural experience: the writer, the narrator, the producer, the technology…here at Sounding Out! we want to render that labor visible and, moreover, think of the sound as a focus of analysis in itself.
For many, the audiobook is a source of pleasure and distraction, a way to get through the To Read Pile while washing dishes or commuting. Audiobooks have a stealthy way of rendering invisible the labor of creating this aural experience: the writer, the narrator, the producer, the technology…here at Sounding Out! we want to render that labor visible and, moreover, think of the sound as a focus of analysis in itself.
Over the next few weeks, we will host several authors who will make all of us think differently about the audiobook selections on our phone, in our car, and in our radios. Last week we listened to a book that listens to Dublin, in a post by Shantam Goyal. Today we have seven narrators telling us the story of an assassination attempt on Bob Marley. What will the audiobook whisper to us that the book cannot speak?
—Managing Editor Liana Silva
Reviews of A Brief History of Seven Killings, Marlon James’ 686-page rendering of the echoes of an assassination attempt on Bob Marley, almost invariably invoke the concept of polyphony to name its adroit use of multiple narrators. In The New York Times, Zachary Lazar maintained that the “polyphony and scope” of the 2014 novel made it much more than a saga of drug and gang violence stretching from 1970s Kingston to 1990s New York. And the Booker Prize, which James was the first Jamaican to win, similarly praised it as a “rich, polyphonic study,” with chief judge Michael Wood calling attention to the impressive “range of voices and registers, running from the patois of the street posse to The Book of Revelation.” It was thus not only the sheer number of voices in a preliminary three-page “Cast of Characters” that critics so unanimously admired but also the variety and nuance evident within them. Norwegian publisher Mime Books even took these polyphonic features a step further by hiring not one but twelve translators in a casting process that auditioned prominent novelists, playwrights, and performers.

Cover of the book, under fair use
James recalls realizing early on that this novel would be one “driven only by voice” (687), which might make such enthusiastic responses to its plurality of perspectives seem unsurprising. But what happens when such polyphony leaves the page behind and actual material voices drive its delivery? If the audiobook is a format of the novel (and here I follow Jonathan Sterne’s definition of format in MP3: The Meaning of a Format as “a whole range of decisions that affect the look, feel, experience, and workings of a medium” [7]), what lessons can listeners learn that print cannot provide? As I argue, the 26-hour-long audiobook version of A Brief History, which Highbridge Audio produced with seven actors (Robertson Dean, Cherise Boothe, Dwight Bacquie, Ryan Anderson, Johnathan McClain, Robert Younis, Thom Rivera), allows us to engage with multivocality rather than polyphony, which is to say the multiple vocal performances of a single individual rather than the presence of many narrators within a print work. And just as this novel’s polyphonic structure destabilizes any attempt at a definitive account of the events it portrays, the multifaceted performances of its audio format work to untrain ears that have been conditioned to hear necessary ties between voices and bodies.
Of course, this effect is not one that most listeners consciously seek, as reviews of the audiobook articulating various reasons for turning to this format as well as diverging responses to it readily attest. Gayle, on Audible, began with the print version: “but as soon as I got to the first chapter that was written in Jamaican patois I knew that I was not able to do that in my head and I was going to miss a lot.” Sound here conveys sense more swiftly than the page, the ear apparently better suited than the eye to encounter difference. (Woodsy, another reviewer, even felt emboldened to ventriloquize in text that sonically distinctive speech: “I found that listening to the Audible version was helpful. Now all me need do is stop thinking in Jamaican.”) Yet it was Andre who offered by far the most memorable characterization of the audiobook and its affordances. As he explained, in James’ novel “the language is a thick, tropical forest of words. Audiobook is the machete that slices through this forest of words so I can enjoy the treasures inside.” The violence of this metaphor matches that of the novel’s most disturbing scenes, yet what is most striking is the way it reiterates once more how reviewers found it easier to access the work aurally rather than visually.

“Studio Microphone” by Richard Feliciano, CC BY-NC-ND 2.0
These reviews, and other similarly favorable appraisals, rarely consider the audiobook on its own terms, insisting instead on comparisons with the text. Negative ones, however, often note distinctively sonic features, with some reviewers echoing one of the Booker judges—who reportedly consulted a Jamaican poet about the accuracy of James’ ear for dialogue—by questioning the veracity of the Jamaican accents in a novel that also features American, Colombian, and Cuban ones. Tending to readily identify themselves as Jamaican, these writers and listeners rarely acknowledge that at least some of the actors were born on the island when asserting that the accents are off. In any case, such efforts to link sound and authenticity, as Liana Silva has argued with respect to the audiobook, wrongly suggest that those who belong to a group must conform to a single sound. James, too, distrusts discourses of the authentic, as characters repeatedly cast suspicion and scorn on anyone uttering the phrase “real Jamaica.”
If the polyphony in James’ novel prevents any one perspective from becoming either representative or definitive, the audiobook pushes this process even further by demonstrating how a single performer’s voice can possess such range that it seems to contain multiple ones. Each performer is responsible for all the voices within the sections narrated by their primary characters, which means that the same character can occasionally be voiced by different actors. In one section, a performer does the voices of a tough-talking Chicago-born hitman and the jittery Colombians he speaks with in Miami; in others, that same performer is both a white Rolling Stone journalist from Minnesota who’s attuned to racial difference and the black Jamaicans he converses with in Kingston. Continuity or strict one-to-one correspondences between performer and character ultimately matter less than the displays of vocal difference that allow the audiobook to contest essentialized notions of voice.
As a result, the audiobook articulates just how constructed vocal divisions based on race, gender, and class are by having its performers constantly cross them. It amplifies the very arbitrariness of such divisions and thereby reveals how, if the page is the space of polyphony, then what the audiobook stages is multivocality. Although they might seem like synonyms, these two terms can actually help us appreciate crucial differences and, in doing so, highlight the specificity of the audio format. On the one hand, –phony or phōnē, as Shane Butler reminds us in The Ancient Phonograph, ambiguously refers to both voice and the human capacity for speech (36), whereas –vocality centers the voice. On the other, the shift from the Greek poly- to the Latin multi- signals a contrast in what gets counted: while polyphony names the quantity of perspectives contributing to a narrative (when introducing it in Problems of Dostoevsky’s Poetics, Mikhail Bakhtin emphasized that polyphony consisted of “a plurality of independent and unmerged voices and consciousnesses” [6]), multivocality instead specifies how the number of voices can exceed the number of performers. In this way, the concept of multivocality outlined here with respect to the audiobook resonates with its use in another context by Katherine Meizel, who mobilizes it with reference to singing and the borders of identity. In both cases, voice names a multiplicity of practices rather than an immutable or inevitable expression, which in turn aligns with Nina Sun Eidsheim’s argument in The Race of Sound about the voice being not singular but collective and not innate but cultural (9).

“Last Exit (Recording Studio)” by Flickr user Drew Ressler, CC BY-NC-ND 2.0
We can therefore say that where print-based polyphony works on the eye by placing various perspectives on a page without necessarily challenging visual perceptions of difference, multivocality in the audiobook can retrain an ear’s culturally ingrained ideas about voice. James himself has experience with these seemingly inescapable meanings assigned to vocal sounds. In a moving essay for The New York Times Magazine, he recounts how, even at the age of 28, “I was so convinced that my voice outed me as a fag that I had stopped speaking to people I didn’t know.” That was already long after high school, when, as he remembered in a New Yorker profile, he had begun “tape-recording his efforts to sound masculine, repeating words like ‘bredren’ and ‘boss.’” He was well aware of the links that listeners created between voice and identity and that could, as he suggests, prove risky in a place with overt homophobia like Jamaica. Writing, however, offered him a space to take on any voice and, at the same time, not be concerned with the sound of his own.
Yet if the page allowed James to effortlessly shift among narrative voices, the audiobook format exhibits voices that ostensibly shift without any effort. Perhaps the most compelling example emerges in the work of Cherise Boothe, whose performance of the novel’s sole female primary character presents the voices of other figures as well. Toward the end of the novel, this character, Dorcas Palmer, is a caretaker for a much older and wealthier white man with amnesia in New York. Boothe not only captures the changes as Palmer often eliminates her Jamaican accent and occasionally lets it loose but also registers the man’s moments of lucidity and confusion. Even if, as listeners, we understand that Boothe is the voice behind both of these characters, the two vocal performances are so distinct that they effectively erode the basis for any beliefs about how a certain body should sound.
Adopting different voices is certainly not unique to the audiobook, but it does provide one of the few forms of extended exposure to this practice. Yet it is worth noting that A Brief History markedly differs from the model of a more extensive cast like the one comprised of 166 voices that recorded George Saunders’ Lincoln in the Bardo. By assigning a performer to every character, such productions ultimately emphasize vocal uniqueness in roughly the same way that Adriana Cavarero conceives it, namely as an index of individuality. But there the voice remains something singular or somehow essential, for there is no opportunity to perform the plurality that appears across A Brief History. At the same time, the use of seven actors also offers a contrast with the opposite extreme: a single performer responsible for all the roles, which demonstrates multivocality but does so on such a small scale that it feels exceptional instead of ordinary. The middle ground, which is to say the model found in A Brief History, allows us to hear multiple instances of how the voice is entrained rather than essential, possibility rather than inevitability.

Screenshot from Youtube video “Marlon James: A Brief History of Seven Killings” by Chicago Humanities Festival
When briefly addressing audiobooks in an interview, James remarked that this format possesses a distinct advantage: “even something that is not necessarily plain can be translated because of tone and symbol and voice.” In other words, a voice can register its changing surroundings; conveying these subtle transformations on the page, however, is often far more difficult. This shortcoming is one that Edward Kamau Brathwaithe once memorably described when explaining why he insisted on using a tape recorder in a lecture on language in the Caribbean: “I want you to get the sound of it, rather than the sight of it.” The idiomatic familiarity of the first half, which clashes so sharply with the awkwardness of the second, suggests that the multivocality of an audiobook can open ears by accentuating how the voice is not fixed but in constant formation.
—
Featured Image: “Audiobook” by Flickr user ActuaLitte, CC-BY-SA-2.0
—
Sam Carter is a PhD Candidate in Romance Studies at Cornell University. His work on literature and sound in the Southern Cone has appeared in Latin American Textualities: History, Materiality, and Digital Media and is forthcoming in the Revista Hispánica Moderna.
—
 REWIND! . . .If you liked this post, you may also dig:
REWIND! . . .If you liked this post, you may also dig:
SO! Reads: Jonathan Sterne’s MP3: The Meaning of a Format–Aaron Trammell
Radio de Acción: Violent Circuits, Contentious Voices: Caribbean Radio Histories–Alejandra Bronfman
“Scenes of Subjection: Women’s Voices Narrating Black Death“–Julie Beth Napolin
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments