
This Past Weekend with Theo Von: Brocasting Trump, Part II


But first. . .
A Brief Synopsis of an Introduction to Bro-casting Trump: A Year-long SO! Series by Andrew Salvati
—
In total, Trump appeared on fourteen podcasts or video streams during his 2024 campaign, which together earned a combined 90.9 million views on YouTube and on other video streaming platforms, not even including audio podcast listens, which, because of the decentralized nature of RSS, are notoriously difficult to pin down.
That’s a lot.
In the following series of posts, I am particularly concerned with Trump’s success with the so-called podcast bros – partially because my own research interests are in the area of mediated masculinities, but also because they may have put him over the edge with a key demographic – with (white) Gen-Z men.
Over this series—which began in January 2026 with Logan Paul—I will examine several of Trump’s appearances on largely apolitical “bro” podcasts during the 2024 campaign season, including his interviews with Logan Paul, Theo Von, Shawn Ryan, Andrew Schulz, the Nelk Boys, and Joe Rogan. In the course of this examination, I will pay attention not only to what Trump said on these shows, but also to the way in which they established a sense of intimacy, and how that intimacy worked to underscore Trump’s reputation for authenticity. Along the way, I will also discuss the podcasts and podcasters themselves and attempt to locate them within the broader scope of the manosphere. Finally, given the passage of time since Trump’s appearances, I will consider to what extent, if any, individual hosts have become critical of his administration’s policies and actions – as Joe Rogan famously has.
Here’s the second installment, on This Past Weekend with Theo Von.
***
This Past Weekend with Theo Von: Brocasting Trump, Part II
DOI: 10.59350/qkwp6-e439

With about five-and-a-half minutes remaining in the podcaster and comedian Theo Von’s August 2024 interview with Donald Trump, the conversation turned to the U.S. southern border. Thus far, the interview had not shied away from policy concerns; however, though the questions were earnest, the answers were evasive and superficial. Noting that he had hosted Border Patrol agents on his show in the past, Von reported that one of the biggest problems that the agency faced was that its officers were arresting the same people over and over again. The reason, according to Von, was that “the people that are coming in illegally aren’t being prosecuted.”
The 44-year-old podcaster then asked the president in his lilting Louisiana accent what he would do differently to alleviate the problem and make the border more secure. Like many, it was a question that allowed Trump to indulge in his penchant for superlative and self-aggrandizement.
“So, the borders, well, I did it. I did it,” Trump declared. “We had the best border … we had the wall built. We had more going to come beyond, long beyond what I promised. I built hundreds of miles of wall, and it worked.”
Now, this post isn’t necessarily the venue for relitigating the failures of what was Trump’s signature project during his first administration, for reminding you, dear reader, that despite his promise on the 2016 campaign trail that he would “build a great, great wall on our southern border” (which Mexico would pay for), and despite signing an executive order just days after taking office that directed the Secretary of Homeland Security “to immediately plan, design, and construct a physical wall along the southern border,” by the end of his term in office in January, 2021, only 452 miles of wall had been constructed – much of which was not new, and had merely replaced existing barriers. Such reminders can be found elsewhere.
Rather, the moment captured the credulity which Von freely gave the former president throughout the interview, and thereby highlighted what I suggested in my last post is the problem – or, from the candidate’s perspective, the virtue – of a media strategy that allotted a significant amount of time to non-journalists: it was unlikely that he’d get much pushback.
***
And after listening through the episode a few times and trying to put myself in the place of an apolitical Theo Von listener, or one perhaps too young to remember the first Trump administration, I began to more fully appreciate the extent to which his apparent authenticity coupled with a sense that he is not just a political outsider, but an autonomous agent free of obligation to party. Typically, this last part comes out when Trump takes aim at “them” – Joe Biden, Kamala Harris, Chuck Schumer, Nancy Pelosi, and other unnamed Democratic elites, as well as any other members of the “deep state,” or “establishment” who oppose him.
In contrast to these shadowy figures, Trump presents himself as someone who, largely because of his wealth, remains independent, and as such, is uncorrupted by “them.” He can thus position himself as a man of the people, and in fact frequently trumpeted his own popularity during the episode – with Von only too happy to provide affirmation.

But this turn toward the border and to immigration policy is also significant in retrospect, given that Von has since been critical of the second Trump administration’s mass deportation policies, and of the Department of Homeland Security’s (DHS’s) unauthorized use of his image and voice in one of its marketing videos in a way that seemed as if he supported the department’s deportation efforts.
In the now-deleted video (part of which can be seen here), Von looks directly into the camera and says “Heard you got deported dude, bye.”
The comedian quickly took to X (formerly Twitter) to vent. “Yoo DHS I didn’t approve to be used in this,” he said in a post that he later deleted. “I know you know my address so send a check. And please take this down and please keep me out of your ‘banger’ deportation videos. When it comes to immigration my thoughts and heart are a lot more nuanced than this video allows. Bye!”
Roughly a week later, on October 2, 2025, Von returned to the subject on his podcast with an impassioned statement explaining to his listeners the situation with the video and outlined some of his own thoughts on immigration. Contextualizing the clip by saying that it had been made in a parking lot after one of his comedy shows as a joke – though in Von’s telling, what he said still comes off as callous, as the “girl” who approached him with the camera was trying to tell the comedian that her friend had recently been deported – Von went on to talk about the blowback he received as a result of the DHS video, which was in no way an accurate depiction of his complex thoughts on immigration.
“And my father immigrated here from Nicaragua, right?” he explained, his voice beginning to break. “Like one of my prized possessions is I have his immigration papers [from] when he came here. And I have them in a frame … and, so I have tons of thoughts about it, but this was just fucked up, right? It was fucked up. And it was everywhere. It was on all platforms and stuff.”
What Von seemed to be doing here was saying that, though he may have supported a tough line on illegal immigration and had little tolerance for those who had been admitted into the country with a criminal record, he could not necessarily get behind the Trump DHS’s indiscriminate deportation scheme, which was sweeping up immigrants who had come into the country the “right way” alongside those who maybe hadn’t.
However in listening to Von’s Trump interview from 2024, it’s hard not to hear the future president laying the groundwork for what would become a maximalist strategy on immigration. “We have over 20 million people, in my opinion, right now, that came into our country [the number of unauthorized immigrants in the U.S. was estimated at 14 million in 2023]. Many come from prisons, jails, mental institutions, many terrorists,” Trump claimed, later adding that “we’re going to spend a lot of time getting the criminals out … we have a lot of people, hundreds of thousands of murderers. We have people, drug dealers … it’s not even believable.”
Although it would have been difficult at the time of the recording to imagine the terror that Trump’s Immigration and Customs Enforcement (ICE) sweeps would unleash on communities like Los Angeles, Chicago, New York, and Portland in the months following his return to office, we can hear in his attempts to vilify unauthorized foreign nationals, and in his fear-mongering about how many of them were bad actors, a justification for the use of blunt force rather than nuanced policy.
And it seemed like Von agreed, at least in principle, with the law-and-order logic underpinning Trump’s statements. “Oh, I don’t think people should be allowed to be in our country if they’re criminals,” he stated.
To give this conversation a charitable reading, it is perhaps likely that Von assumed that, once in office, Trump’s administration would have the tools to determine which foreign nationals were authorized to be in the country and which were not. Further, he may also have believed ICE would know who among this group had a criminal record – and not conduct mass roundups based on race.
Yet, as we should have all probably known by the summer of 2024, for Trump and his chief advisers, blunt force (and cruelty) was the point. Recall the so-called “Muslim Ban” instituted during Trump’s first term, which was hardly an example of a well-calibrated policy, but was rather a “total and complete shutdown” of travelers and immigrants from seven Muslim-majority countries (though even this wasn’t without its conflicts of interest as it excluded several countries like Saudi Arabia and the United Arab Emirates where Trump had business dealings).
Even the wall, which was conceived by Trump insiders in 2015 as a mnemonic device intended to help their boss to remember to mention illegal immigration at his campaign rallies, was deemed effective precisely because it was not subtle. As Trump 2016 campaign adviser Sam Nunberg told Business Insider, “I think one issue is people did understand walls … the wall in 2016 was symbolic of Donald Trump: common sense, practical solutions, simplified answers – as opposed to long nuanced, detailed policy speak.”

President Donald J. Trump’s signature is seen on a plaque on the border wall Tuesday, Jan. 12, 2021, at the Texas-Mexico border near Alamo, Texas. (Official White House Photo by Shealah Craighead) (PDM 1.0)
And this would be a fair characterization of Trump’s remarks on This Past Weekend – when Von asked earnest policy questions, Trump offered simplified, seemingly common sense responses that presented his own approach to the problems of government as something different than politics-as-usual, different because it was guided by an intensely practical, no-nonsense ethos.
Like his appearance on Logan Paul’s Impaulsive, Trump’s calm, yet forceful tone of voice on This Past Weekend tended to support his overall credibility as a leader capable of bringing logical solutions to a crisis-ridden government – of brining decisive, masculine order to the chaos in Washington. Such was the impression that listeners may have gotten, for instance, from Trump and Von’s discussion of the president’s first term executive order mandating price transparency for hospital care, which Von asked Trump about specifically, and which, Trump claimed, “would have brought down the cost of care by 50, 60%” if Biden and Kamala had enforced it.
But Trump’s appeals to common sense also provided cover for what might have otherwise been an embarrassing bit of hypocrisy. When Von began to turn the conversation toward the power of lobbyists, asking why it was that the government couldn’t seem to do anything about the so-called revolving door, Trump explained that there was a “whole constitutional thing there” (the First Amendment right to petition the government), and agreed with Von that it was “a problem and … a big problem,” adding that “we were [in his first term] doing things about it.”
What his administration did, was issue an executive order banning executive branch employees from becoming lobbyists for a period of five years. This move may have seemed like it indicated a genuine desire to “drain the swamp,” as Trump routinely promised to do on the campaign trail in 2016, but, as ProPublica revealed in a 2019 report, his administration had actually hired 1 lobbyist for every 14 political appointees that it had made since taking office (281 in total), which was four times more than Obama had appointed six years into office.
Given that they had provided ingress to the executive branch, it is perhaps unsurprising that they would eventually provide egress, executive order notwithstanding. Indeed, on the final day of his first term, Trump revoked the order without giving explanation, clearing the way for members of his administration to secure lucrative lobbying gigs. Such contradictions, however, were more or less concealed behind Trump’s populist rhetoric, behind his apparent recognition that conflicts of interest are a problem in politics, or that medical debt is crushing Americans.

But taking a sound studies perspective, we can also see – or hear – how Trump’s tone of voice, which admittedly seems less energetic than it was during his Logan Paul interview, tended to convey an assurance that what he said was an authentic expression of his own thoughts and perspectives. Again, this was not the kind of stream-of-consciousness raving that we have come to expect from his rallies, but rather a low-key, intimate conversation about relevant issues and facts – or, at least facts as Trump saw them.
The implication here is that Trump as a political leader is free to operate in ways that mere politicians and government officials simply can’t because of their obligations to party, to donors, or to lobbyists. What is likely missed in all of this, however, is that what Trump is describing is a thoroughly authoritarian approach to political power, one that is of a piece with his claim that “I alone can fix it.” Positioning himself outside the political establishment – and even independent of the Republican Party of which he is nominally the leader – Trump can offer himself as a political messiah and claim the moral authority to act without regard for democratic processes in the name of a specious popular mandate.
In other words, by contrasting himself with “them,” and by holding himself at a distance from the dominant political order, Trump clears himself of the obligation to work with any group or individual that he deems to be opposed to his own quasi-populist agenda.
And for Von and those in his audience who are fed up with the status quo, that is a powerful appeal.
—
Featured Image: Theo Von, Edited James Tamim, Wikimedia Images (CC BY-SA 2.0)
—
Andrew J. Salvati is an adjunct professor in the Media and Communications program at Drew University, where he teaches courses on podcasting and television studies. His research interests include media and cultural memory, television history, and mediated masculinity. He is the co-founder and occasional co-host of Inside the Box: The TV History Podcast, and Drew Archives in 10.
—
REWIND! . . .If you liked this post, you may also dig:

Impaulsive: Bro-casting Trump, Part I—Andrew Salvati
Taters Gonna Tate. . .But Do Platforms Have to Platform?: Listening to the Manosphere—Andrew Salvati
Listening to MAGA Politics within US/Mexico’s Lucha Libre –Esther Díaz Martín and Rebeca Rivas
Gendered Sonic Violence, from the Waiting Room to the Locker Room–Rebecca Lentjes
—
Layout by Jennifer L. Stoever
Share this:

El Llanto Against I.C.E.: Toward a Latinx Sonic Phenomenology of the Dignified Cry

DOI: https://doi.org/10.59350/xgm8r-acg57
It is July 4, 2025. The air is hot; the sun is beaming on concrete and asphalt. Sweat is accumulating on my cotton Disrupt band t-shirt. My skin is sticky. Inside a suffocating room, the volume penetrating my ears is the racket of voices producing a steady pulsation of disunified sounds. A brown noise. In a studio room in Boyle Heights, the acoustics create a space-time of rebellious gravity. There’s something gestating. We are in that in-between aural space, the time-lag between speaker, musician, or performance. The MC is letting the crowd know what is next. We all desired to know.
Yaotl—the vocalist of Xicano hip-hop/punk group Aztlán Underground—is the MC. He is speaking to the crowd during that transition to the next set. Doing so, Yaotl used this exact instance to identify the political moment we were all witness to, the historical cause for the event here, and then, surprising everyone, facilitated a collective llanto. He called it “scream therapy.” The dignified cry, as I am calling it, for him, is sticky, piercing, and angry—a sonorous form of dignified rage. We are all here for Xican@ Records and Film annual cultural event, the Farce of July that hosts vendors and musicians. Yaotl readies the crowd, his contagious call for a llanto also fused with the intimate violences of coloniality, what decolonial theorists of modernity, such as semiotician Walter Mignolo, have called its darker side or underside. “I want everyone to scream your fucking rage against all this shit.” He counts to three. One. Two. Three. We scream. We yell. We cry and cry out together. We manifest the sound of el llanto.

Gritos, llantos, sonidos, caos, and roncas are not new in Latinx Sound Studies. Their history, particularly in Latinx cultural studies, is intimate with the genealogy of not only musical or popular cultural forms (think rancheras in Mexico) but ancestral ceremony, rituals, and mythic stories (like La Llorona). From the invasion of Mexico-Tenochtitlan by Cortés in 1519 to the sonic protest of the 2018 Llanto Colectivo against the Otay Mesa Detention Center in San Diego, we can adequately identify the historically loud opposition against racism and coloniality in the United States. I explore the function of el llanto in relationship to a generalized response to the fascist sequences of repression emerging in the United States, showing how llantos orient both the listener and participant toward a discernment of grief and catharsis. This twofold function facilitates an embodied practice of corporeal sound-making and its therapeutic effect, which I ground here as a form of affective suture. Suffering, transmuted into coraje (angry-tinged courage), generates a collective sounding that pulls listeners into the acoustic llanto. In doing so, it transforms the listener into an agent of dignified rage.
Theorizing llantos requires a Latinx sound and listening methodology grounded in sonic phenomenology—drawing from phenomenological and sound studies traditions—that develop an “acoustic perception” sensitive to the “sonic environment.” I contribute to the notes toward a Latinx listening methodology introduced by Wanda Alarcón, Dolores Inés Casillas, Esther Díaz Martín, Sara Veronica Hinojos, and Cloe Gentile Reyes, who affirm faithful listening as, “attuned not only to sound, but to histories, structures, and acts of refusal that resist dehumanization.” Historically, phenomenologists have privileged the visual phenomenal field, the primacy of visuality being the ocular sense to discern or disclose the meaning of consciousness and lived experience. The sonic phenomenologist tunes into the soundscape as the totality of the aural experience.
The sonic phenomenologist of el llanto, or the dignified cry, develops a decolonial listening technique to perceive the aural structure of coloniality, the audition of dispossession mediated by anti-migrant animus, and the desire for emancipation from such sonic hauntings in everyday life. Many who let out a llanto do so in the face of anti-immigrant, anti-Latinx racism. It emerges as a vocal response to coloniality as lived and enforced through everyday regimes of racialized governance, from linguistic profiling and labor precarity to the slow violence of immigration delay and the spectacle of public kidnappings.
The collective llanto in July came at a time when in Los Angeles, California a popular revolt broke out in the early days of June amongst dissenters against I.C.E. raids and the Trump administration’s deployment of the National Guard to the streets. The spectacle, of a Xicano hip-hop/punk ensemble inviting a collective llanto, became much more than the cacophony of discordant screams but the dissensus of an aggrieved community. In their grief, mediated by the capture, detainment, and transport of undocumented migrants to detention centers, the catharsis of a llanto fueled the connection between desire and social movement. The sounds exiting the body, resonating as vibration in a shared room, identified the mutual feelings of others, in the exhalation of a noisy, impulsive breath.
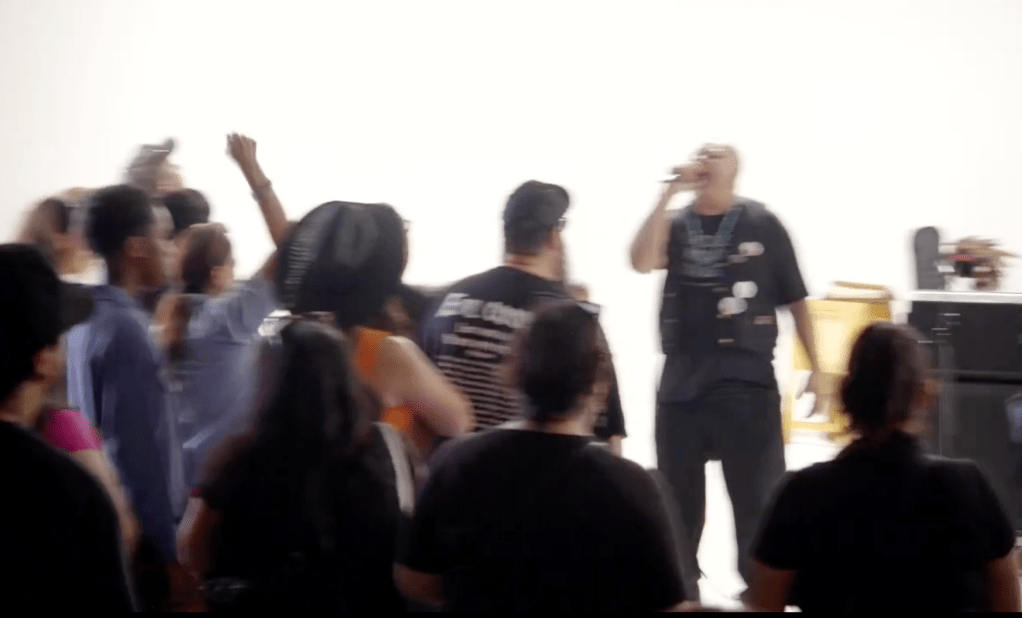
This was not euphoria.
This instance of a rageful cry—loud, infectious, piercing – builds on the “faithful witnessing” articulated by María Lugones and Yomaira Figueroa-Vásquez, disclosing collective anguish fused with a tender fury. The listener must resist the organization of the dignified cry as melodic, rhythmic, or joyful. Rather, the llanto disturbs, ruptures, and erupts as a thunderous dissonance. Its saturation of auditory space interrupts the experience of conviviality or seriality and enchants the temporal form of the ensemble where the participants disappear behind the guttural and raucous sounds.
Faithful listening not only decolonizes racializing sonic structures but amplifies resistance, revolt, and coraje. Llantos are spontaneous, organized, lived. To voice el llanto is to become el llanto; an affective suture where a new auditory imaginary links with the Xicanacimiento of Yaotl’s specificity. Llantos, thus, are particular vocal moments continually shaped and fashioned. For the critical Latinx listener, el llanto offers a few seconds of catharsis and collective grief.
—
Featured Image: Aztlan Underground en Tenochtitlán by Flickr User Joél Martínez CC BY-NC-SA 2.0
—
Kristian E. Vasquez is a Ph.D. candidate in the Department of Chicana and Chicano Studies at the University of California, Santa Barbara. His research on the affects, performances, sounds, and semiosis of La Xicanada expands the concept of Xicanacimiento, centering the aesthetic force of expressive cultural forms in California.
—
.

REWIND!…If you liked this post, you may also dig:
Boom! Boom! Boom!: Banda, Dissident Vibrations, and Sonic Gentrification in Mazatlán—Kristie Valdez-Guillen
Listening to MAGA Politics within US/Mexico’s Lucha Libre –Esther Díaz Martín and Rebeca Rivas
Ronca Realness: Voices that Sound the Sucia Body—Cloe Gentile Reyes
Echoes in Transit: Loudly Waiting at the Paso del Norte Border Region—José Manuel Flores & Dolores Inés Casillas
Share this:






Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments