
Sounds of Science: The Mystique of Sonification

 Welcome to the final installment of Hearing the UnHeard, Sounding Out!‘s series on what we don’t hear and how this unheard world affects us. The series started out with my post on hearing, large and small, continued with a piece by China Blue on the sounds of catastrophic impacts, and Milton Garcés’ piece on the infrasonic world of volcanoes. To cap it all off, we introduce The Sounds of Science by professor, cellist and interactive media expert, Margaret Schedel.
Welcome to the final installment of Hearing the UnHeard, Sounding Out!‘s series on what we don’t hear and how this unheard world affects us. The series started out with my post on hearing, large and small, continued with a piece by China Blue on the sounds of catastrophic impacts, and Milton Garcés’ piece on the infrasonic world of volcanoes. To cap it all off, we introduce The Sounds of Science by professor, cellist and interactive media expert, Margaret Schedel.
Dr. Schedel is an Associate Professor of Composition and Computer Music at Stony Brook University. Through her work, she explores the relatively new field of Data Sonification, generating new ways to perceive and interact with information through the use of sound. While everyone is familiar with informatics, graphs and images used to convey complex information, her work explores how we can expand our understanding of even complex scientific information by using our fastest and most emotionally compelling sense, hearing.
– Guest Editor Seth Horowitz
—
With the invention of digital sound, the number of scientific experiments using sound has skyrocketed in the 21st century, and as Sounding Out! readers know, sonification has started to enter the public consciousness as a new and refreshing alternative modality for exploring and understanding many kinds of datasets emerging from research into everything from deep space to the underground. We seem to be in a moment in which “science that sounds” has a special magic, a mystique that relies to some extent on misunderstandings in popular awareness about the processes and potentials of that alternative modality.
For one thing, using sound to understand scientific phenomena is not actually new. Diarist Samuel Pepys wrote about meeting scientist Robert Hooke in 1666 that “he is able to tell how many strokes a fly makes with her wings (those flies that hum in their flying) by the note that it answers to in musique during their flying.” Unfortunately Hooke never published his findings, leading researchers to speculate on his methods. One popular theory is that he tied strings of varying lengths between a fly and an ear trumpet, recognizing that sympathetic resonance would cause the correct length string to vibrate, thus allowing him to calculate the frequency. Even Galileo used sound, showing the constant acceleration of a ball due to gravity by using an inclined plane with thin moveable frets. By moving the placement of the frets until the clicks created an even tempo he was able to come up with a mathematical equation to describe how time and distance relate when an object falls.

Illustration from Robert Hooke’s Micrographia (1665)
There have also been other scientific advances using sound in the more recent past. The stethoscope was invented in 1816 for auscultation, listening to the sounds of the body. It was later applied to machines—listening for the operation of the technological gear. Underwater sonar was patented in 1913 and is still used to navigate and communicate using hydroacoustic phenomenon. The Geiger Counter was developed in 1928 using principles discovered in 1908; it is unclear exactly when the distinctive sound was added. These are all examples of auditory display [AD]; sonification-generating or manipulating sound by using data is a subset of AD. As the forward to the The Sonification Handbook states, “[Since 1992] Technologies that support AD have matured. AD has been integrated into significant (read “funded” and “respectable”) research initiatives. Some forward thinking universities and research centers have established ongoing AD programs. And the great need to involve the entire human perceptual system in understanding complex data, monitoring processes, and providing effective interfaces has persisted and increased” (Thomas Hermann, Andy Hunt, John G. Neuhoff, Sonification Handbook, iii)
Sonification clearly enables scientists, musicians and the public to interact with data in a very different way, particularly compared to the more numerous techniques involving vision. Indeed, because hearing functions quite differently than vision, sonification offers an alternative kind of understanding of data (sometimes more accurate), which would not be possible using eyes alone. Hearing is multi-directional—our ears don’t have to be pointing at a sound source in order to sense it. Furthermore, the frequency response of our hearing is thousands of times more accurate than our vision. In order to reproduce a moving image the sampling rate (called frame-rate) for film is 24 frames per second, while audio has to be sampled at 44,100 frames per second in order to accurately reproduce sound. In addition, aural perception works on simultaneous time scales—we can take in multiple streams of audio data at once at many different dynamics, while our pupils dilate and contract, limiting how much visual data we can absorb at a single time. Our ears are also amazing at detecting regular patterns over time in data; we hear these patterns as frequency, harmonic relationships, and timbre.
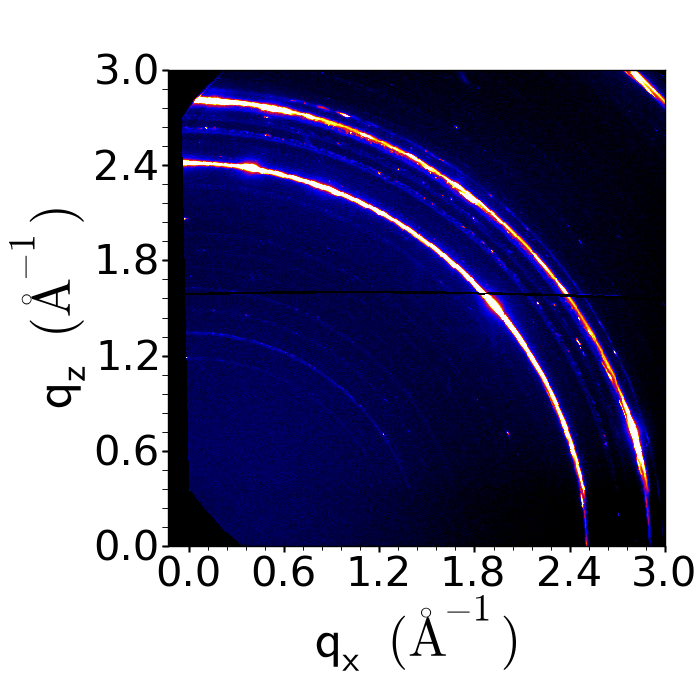
Image credit: Dr. Kevin Yager, Brookhaven National Lab.
But hearing isn’t simple, either. In the current fascination with sonification, the fact that aesthetic decisions must be made in order to translate data into the auditory domain can be obscured. Headlines such as “Here’s What the Higgs Boson Sounds Like” are much sexier than headlines such as “Here is What One Possible Mapping of Some of the Data We Have Collected from a Scientific Measuring Instrument (which itself has inaccuracies) Into Sound.” To illustrate the complexity of these aesthetic decisions, which are always interior to the sonification process, I focus here on how my collaborators and I have been using sound to understand many kinds of scientific data.
My husband, Kevin Yager, a staff scientist at Brookhaven National Laboratory, works at the Center for Functional Nanomaterials using scattering data from x-rays to probe the structure of matter. One night I asked him how exactly the science of x-ray scattering works. He explained that X-rays “scatter” off of all the atoms/particles in the sample and the intensity is measured by a detector. He can then calculate the structure of the material, using the Fast Fourier Transform (FFT) algorithm. He started to explain FFT to me, but I interrupted him because I use FFT all the time in computer music. The same algorithm he uses to determine the structure of matter, musicians use to separate frequency content from time. When I was researching this post, I found a site for computer music which actually discusses x-ray scattering as a precursor for FFT used in sonic applications.
To date, most sonifications have used data which changes over time – a fly’s wings flapping, a heartbeat, a radiation signature. Except in special cases Kevin’s data does not exist in time – it is a single snapshot. But because data from x-ray scattering is a Fourier Transform of the real-space density distribution, we could use additive synthesis, using multiple simultaneous sine waves, to represent different spatial modes. Using this method, we swept through his data radially, like a clock hand, making timbre-based sonifications from the data by synthesizing sine waves using with the loudness based on the intensity of the scattering data and frequency based on the position.
We played a lot with the settings of the additive synthesis, including the length of the sound, the highest frequency and even the number of frequency bins (going back to the clock metaphor – pretend the clock hand is a ruler – the number of frequency bins would be the number of demarcations on the ruler) arriving eventually at set of optimized variables.
Here is one version of the track we created using 10 frequency bins:
.
Here is one we created using 2000:
.
And here is one we created using 50 frequency bins, which we settled on:
.
On a software synthesizer this would be like the default setting. In the future we hope to have an interactive graphic user interface where sliders control these variables, just like a musician tweaks the sound of a synth, so scientists can bring out, or mask aspects of the data.
To hear what that would be like, here are a few tracks that vary length:
.
.
.
Finally, here is a track we created using different mappings of frequency and intensity:
.
Having these sliders would reinforce to the scientists that we are not creating “the sound of a metallic alloy,” we are creating one sonic representation of the data from the metallic alloy.
It is interesting that such a representation can be vital to scientists. At first, my husband went along with this sonification project as more of a thought experiment rather than something that he thought would actually be useful in the lab, until he heard something distinct about one of those sounds, suggesting that there was a misaligned sample. Once Kevin heard that glitched sound (you can hear it in the video above), he was convinced that sonification was a useful tool for his lab. He and his colleagues are dealing with measurements 1/25,000th the width of a human hair, aiming an X-ray through twenty pieces of equipment to get the beam focused just right. If any piece of equipment is out of kilter, the data can’t be collected. This is where our ears’ non-directionality is useful. The scientist can be working on his/her computer and, using ambient sound, know when a sample is misaligned.

It remains to be seen/heard if the sonifications will be useful to actually understand the material structures. We are currently running an experiment using Mechanical Turk to determine this kind of multi-modal display (using vision and audio) is actually helpful. Basically we are training people on just the images of the scattering data, and testing how well they do, and training another group of people on the images plus the sonification and testing how well they do.
I’m also working with collaborators at Stony Brook University on sonification of data. In one experiment we are using ambisonic (3-dimensional) sound to create a sonic map of the brain to understand drug addiction. Standing in the middle of the ambisonic cube, we hope to find relationships between voxels, a cube of brain tissue—analogous to pixels. When neurons fire in areas of the brain simultaneously there is most likely a causal relationship which can help scientists decode the brain activity of addiction. Computer vision researchers have been searching for these relationships unsuccessfully; we hope that our sonification will allow us to hear associations in distinct parts of the brain which are not easily recognized with sight. We are hoping to leverage the temporal pattern recognition of our auditory system, but we have been running into problems doing the sonification; each slice of data from the FMRI has about 300,000 data points. We have it working with 3,000 data points, but either our programming needs to get more efficient, or we have to get a much more powerful computer in order to work with all of the data.
On another project we are hoping to sonify gait data using smartphones. I’m working with some of my music students and a professor of Physical Therapy, Lisa Muratori, who works on understanding the underlying mechanisms of mobility problems in Parkinsons’ Disease (PD). The physical therapy lab has a digital motion-capture system and a split-belt treadmill for asymmetric stepping—the patients are supported by a harness so they don’t fall. PD is a progressive nervous system disorder characterized by slow movement, rigidity, tremor, and postural instability. Because of degeneration of specific areas of the brain, individuals with PD have difficulty using internally driven cues to initiate and drive movement. However, many studies have demonstrated an almost normal movement pattern when persons with PD are provided external cues, including significant improvements in gait with rhythmic auditory cueing. So far the research with PD and sound has be unidirectional – the patients listen to sound and try to match their gait to the external rhythms from the auditory cues.In our system we will use bio-feedback to sonify data from sensors the patients will wear and feed error messages back to the patient through music. Eventually we hope that patients will be able to adjust their gait by listening to self-generated musical distortions on a smartphone.
As sonification becomes more prevalent, it is important to understand that aesthetic decisions are inevitable and even essential in every kind of data representation. We are so accustomed to looking at visual representations of information—from maps to pie charts—that we may forget that these are also arbitrary transcodings. Even a photograph is not an unambiguous record of reality; the mechanics of the camera and artistic choices of the photographer control the representation. So too, in sonification, do we have considerable latitude. Rather than view these ambiguities as a nuisance, we should embrace them as a freedom that allows us to highlight salient features, or uncover previously invisible patterns.
__
Margaret Anne Schedel is a composer and cellist specializing in the creation and performance of ferociously interactive media. She holds a certificate in Deep Listening with Pauline Oliveros and has studied composition with Mara Helmuth, Cort Lippe and McGregor Boyle. She sits on the boards of 60×60 Dance, the BEAM Foundation, Devotion Gallery, the International Computer Music Association, and Organised Sound. She contributed a chapter to the Cambridge Companion to Electronic Music, and is a joint author of Electronic Music published by Cambridge University Press. She recently edited an issue of Organised Sound on sonification. Her research focuses on gesture in music, and the sustainability of technology in art. She ran SUNY’s first Coursera Massive Open Online Course (MOOC) in 2013. As an Associate Professor of Music at Stony Brook University, she serves as Co-Director of Computer Music and is a core faculty member of cDACT, the consortium for digital art, culture and technology.
—
Featured Image: Dr. Kevin Yager, data measured at X9 beamline, Brookhaven National Lab.
—
Research carried out at the Center for Functional Nanomaterials, Brookhaven National Laboratory, is supported by the U.S. Department of Energy, Office of Basic Energy Sciences, under Contract No. DE-AC02-98CH10886.
—
 REWIND! ….. If you liked this post, you might also like:
REWIND! ….. If you liked this post, you might also like:
The Noises of Finance–N. Adriana Knouf
Revising the Future of Music Technology–Aaron Trammell
A Brief History of Auto-Tune–Owen Marshall
Share this:

The Better to Hear You With, My Dear: Size and the Acoustic World

Today the SO! Thursday stream inaugurates a four-part series entitled Hearing the UnHeard, which promises to blow your mind by way of your ears. Our Guest Editor is Seth Horowitz, a neuroscientist at NeuroPop and author of The Universal Sense: How Hearing Shapes the Mind (Bloomsbury, 2012), whose insightful work on brings us directly to the intersection of the sciences and the arts of sound.
That’s where he’ll be taking us in the coming weeks. Check out his general introduction just below, and his own contribution for the first piece in the series. — NV
—
Welcome to Hearing the UnHeard, a new series of articles on the world of sound beyond human hearing. We are embedded in a world of sound and vibration, but the limits of human hearing only let us hear a small piece of it. The quiet library screams with the ultrasonic pulsations of fluorescent lights and computer monitors. The soothing waves of a Hawaiian beach are drowned out by the thrumming infrasound of underground seismic activity near “dormant” volcanoes. Time, distance, and luck (and occasionally really good vibration isolation) separate us from explosive sounds of world-changing impacts between celestial bodies. And vast amounts of information, ranging from the songs of auroras to the sounds of dying neurons can be made accessible and understandable by translating them into human-perceivable sounds by data sonification.
Four articles will examine how this “unheard world” affects us. My first post below will explore how our environment and evolution have constrained what is audible, and what tools we use to bring the unheard into our perceptual realm. In a few weeks, sound artist China Blue will talk about her experiences recording the Vertical Gun, a NASA asteroid impact simulator which helps scientists understand the way in which big collisions have shaped our planet (and is very hard on audio gear). Next, Milton A. Garcés, founder and director of the Infrasound Laboratory of University of Hawaii at Manoa will talk about volcano infrasound, and how acoustic surveillance is used to warn about hazardous eruptions. And finally, Margaret A. Schedel, composer and Associate Professor of Music at Stonybrook University will help readers explore the world of data sonification, letting us listen in and get greater intellectual and emotional understanding of the world of information by converting it to sound.
— Guest Editor Seth Horowitz
—
Although light moves much faster than sound, hearing is your fastest sense, operating about 20 times faster than vision. Studies have shown that we think at the same “frame rate” as we see, about 1-4 events per second. But the real world moves much faster than this, and doesn’t always place things important for survival conveniently in front of your field of view. Think about the last time you were driving when suddenly you heard the blast of a horn from the previously unseen truck in your blind spot.
Hearing also occurs prior to thinking, with the ear itself pre-processing sound. Your inner ear responds to changes in pressure that directly move tiny little hair cells, organized by frequency which then send signals about what frequency was detected (and at what amplitude) towards your brainstem, where things like location, amplitude, and even how important it may be to you are processed, long before they reach the cortex where you can think about it. And since hearing sets the tone for all later perceptions, our world is shaped by what we hear (Horowitz, 2012).
But we can’t hear everything. Rather, what we hear is constrained by our biology, our psychology and our position in space and time. Sound is really about how the interaction between energy and matter fill space with vibrations. This makes the size, of the sender, the listener and the environment, one of the primary features that defines your acoustic world.
You’ve heard about how much better your dog’s hearing is than yours. I’m sure you got a slight thrill when you thought you could actually hear the “ultrasonic” dog-training whistles that are supposed to be inaudible to humans (sorry, but every one I’ve tested puts out at least some energy in the upper range of human hearing, even if it does sound pretty thin). But it’s not that dogs hear better. Actually, dogs and humans show about the same sensitivity to sound in terms of sound pressure, with human’s most sensitive region from 1-4 kHz and dogs from about 2-8 kHz. The difference is a question of range and that is tied closely to size.
Most dogs, even big ones, are smaller than most humans and their auditory systems are scaled similarly. A big dog is about 100 pounds, much smaller than most adult humans. And since body parts tend to scale in a coordinated fashion, one of the first places to search for a link between size and frequency is the tympanum or ear drum, the earliest structure that responds to pressure information. An average dog’s eardrum is about 50 mm2, whereas an average human’s is about 60 mm2. In addition while a human’s cochlea is spiral made of 2.5 turns that holds about 3500 inner hair cells, your dog’s has 3.25 turns and about the same number of hair cells. In short: dogs probably have better high frequency hearing because their eardrums are better tuned to shorter wavelength sounds and their sensory hair cells are spread out over a longer distance, giving them a wider range.

Interest in the how hearing works in animals goes back centuries. Classical image of comparative ear anatomy from 1789 by Andreae Comparetti.
Then again, if hearing was just about size of the ear components, then you’d expect that yappy 5 pound Chihuahua to hear much higher frequencies than the lumbering 100 pound St. Bernard. Yet hearing sensitivity from the two ends of the dog spectrum don’t vary by much. This is because there’s a big difference between what the ear can mechanically detect and what the animal actually hears. Chihuahuas and St. Bernards are both breeds derived from a common wolf-like ancestor that probably didn’t have as much variability as we’ve imposed on the domesticated dog, so their brains are still largely tuned to hear what a medium to large pseudo wolf-like animal should hear (Heffner, 1983).
But hearing is more than just detection of sound. It’s also important to figure out where the sound is coming from. A sound’s location is calculated in the superior olive – nuclei in the brainstem that compare the difference in time of arrival of low frequency sounds at your ears and the difference in amplitude between your ears (because your head gets in the way, making a sound “shadow” on the side of your head furthest from the sound) for higher frequency sounds. This means that animals with very large heads, like elephants, will be able to figure out the location of longer wavelength (lower pitched) sounds, but probably will have problems localizing high pitched sounds because the shorter frequencies will not even get to the other side of their heads at a useful level. On the other hand, smaller animals, which often have large external ears, are under greater selective pressure to localize higher pitched sounds, but have heads too small to pick up the very low infrasonic sounds that elephants use.

Audiograms (auditory sensitivity in air measured in dB SPL) by frequency of animals of different sizes showing the shift of maximum sensitivity to lower frequencies with increased size. Data replotted based on audiogram data by Sivian and White (1933). “On minimum audible sound fields.” Journal of the Acoustical Society of America, 4: 288-321; ISO 1961; Heffner, H., & Masterton, B. (1980). “Hearing in glires: domestic rabbit, cotton rat, feral house mouse, and kangaroo rat.” Journal of the Acoustical Society of America, 68, 1584-1599.; Heffner, R. S., & Heffner, H. E. (1982). “Hearing in the elephant: Absolute sensitivity, frequency discrimination, and sound localization.” Journal of Comparative and Physiological Psychology, 96, 926-944.; Heffner H.E. (1983). “Hearing in large and small dogs: Absolute thresholds and size of the tympanic membrane.” Behav. Neurosci. 97: 310-318. ; Jackson, L.L., et al.(1999). “Free-field audiogram of the Japanese macaque (Macaca fuscata).” Journal of the Acoustical Society of America, 106: 3017-3023.
But you as a human are a fairly big mammal. If you look up “Body Size Species Richness Distribution” which shows the relative size of animals living in a given area, you’ll find that humans are among the largest animals in North America (Brown and Nicoletto, 1991). And your hearing abilities scale well with other terrestrial mammals, so you can stop feeling bad about your dog hearing “better.” But what if, by comic-book science or alternate evolution, you were much bigger or smaller? What would the world sound like? Imagine you were suddenly mouse-sized, scrambling along the floor of an office. While the usual chatter of humans would be almost completely inaudible, the world would be filled with a cacophony of ultrasonics. Fluorescent lights and computer monitors would scream in the 30-50 kHz range. Ultrasonic eddies would hiss loudly from air conditioning vents. Smartphones would not play music, but rather hum and squeal as their displays changed.
And if you were larger? For a human scaled up to elephantine dimensions, the sounds of the world would shift downward. While you could still hear (and possibly understand) human speech and music, the fine nuances from the upper frequency ranges would be lost, voices audible but mumbled and hard to localize. But you would gain the infrasonic world, the low rumbles of traffic noise and thrumming of heavy machinery taking on pitch, color and meaning. The seismic world of earthquakes and volcanoes would become part of your auditory tapestry. And you would hear greater distances as long wavelengths of low frequency sounds wrap around everything but the largest obstructions, letting you hear the foghorns miles distant as if they were bird calls nearby.
But these sounds are still in the realm of biological listeners, and the universe operates on scales far beyond that. The sounds from objects, large and small, have their own acoustic world, many beyond our ability to detect with the equipment evolution has provided. Weather phenomena, from gentle breezes to devastating tornadoes, blast throughout the infrasonic and ultrasonic ranges. Meteorites create infrasonic signatures through the upper atmosphere, trackable using a system devised to detect incoming ICBMs. Geophones, specialized low frequency microphones, pick up the sounds of extremely low frequency signals foretelling of volcanic eruptions and earthquakes. Beyond the earth, we translate electromagnetic frequencies into the audible range, letting us listen to the whistlers and hoppers that signal the flow of charged particles and lightning in the atmospheres of Earth and Jupiter, microwave signals of the remains of the Big Bang, and send listening devices on our spacecraft to let us hear the winds on Titan.
Here is a recording of whistlers recorded by the Van Allen Probes currently orbiting high in the upper atmosphere:
When the computer freezes or the phone battery dies, we complain about how much technology frustrates us and complicates our lives. But our audio technology is also the source of wonder, not only letting us talk to a friend around the world or listen to a podcast from astronauts orbiting the Earth, but letting us listen in on unheard worlds. Ultrasonic microphones let us listen in on bat echolocation and mouse songs, geophones let us wonder at elephants using infrasonic rumbles to communicate long distances and find water. And scientific translation tools let us shift the vibrations of the solar wind and aurora or even the patterns of pure math into human scaled songs of the greater universe. We are no longer constrained (or protected) by the ears that evolution has given us. Our auditory world has expanded into an acoustic ecology that contains the entire universe, and the implications of that remain wonderfully unclear.
__
Exhibit: Home Office
This is a recording made with standard stereo microphones of my home office. Aside from usual typing, mouse clicking and computer sounds, there are a couple of 3D printers running, some music playing, largely an environment you don’t pay much attention to while you’re working in it, yet acoustically very rich if you pay attention.
.
This sample was made by pitch shifting the frequencies of sonicoffice.wav down so that the ultrasonic moves into the normal human range and cuts off at about 1-2 kHz as if you were hearing with mouse ears. Sounds normally inaudible, like the squealing of the computer monitor cycling on kick in and the high pitched sound of the stepper motors from the 3D printer suddenly become much louder, while the familiar sounds are mostly gone.
.
This recording of the office was made with a Clarke Geophone, a seismic microphone used by geologists to pick up underground vibration. It’s primary sensitivity is around 80 Hz, although it’s range is from 0.1 Hz up to about 2 kHz. All you hear in this recording are very low frequency sounds and impacts (footsteps, keyboard strikes, vibration from printers, some fan vibration) that you usually ignore since your ears are not very well tuned to frequencies under 100 Hz.
.
Finally, this sample was made by pitch shifting the frequencies of infrasonicoffice.wav up as if you had grown to elephantine proportions. Footsteps and computer fan noises (usually almost indetectable at 60 Hz) become loud and tonal, and all the normal pitch of music and computer typing has disappeared aside from the bass. (WARNING: The fan noise is really annoying).
.
The point is: a space can sound radically different depending on the frequency ranges you hear. Different elements of the acoustic environment pop up depending on the type of recording instrument you use (ultrasonic microphone, regular microphones or geophones) or the size and sensitivity of your ears.
![Spectrograms (plots of acoustic energy [color] over time [horizontal axis] by frequency band [vertical axis]) from a 90 second recording in the author’s home office covering the auditory range from ultrasonic frequencies (>20 kHz top) to the sonic (20 Hz-20 kHz, middle) to the low frequency and infrasonic (<20 Hz).](https://soundstudiesblog.com/wp-content/uploads/2014/08/figure3officerange.jpg)
Spectrograms (plots of acoustic energy [color] over time [horizontal axis] by frequency band [vertical axis]) from a 90 second recording in the author’s home office covering the auditory range from ultrasonic frequencies (>20 kHz top) to the sonic (20 Hz-20 kHz, middle) to the low frequency and infrasonic (<20 Hz).
Featured image by Flickr User Jaime Wong.
—
Seth S. Horowitz, Ph.D. is a neuroscientist whose work in comparative and human hearing, balance and sleep research has been funded by the National Institutes of Health, National Science Foundation, and NASA. He has taught classes in animal behavior, neuroethology, brain development, the biology of hearing, and the musical mind. As chief neuroscientist at NeuroPop, Inc., he applies basic research to real world auditory applications and works extensively on educational outreach with The Engine Institute, a non-profit devoted to exploring the intersection between science and the arts. His book The Universal Sense: How Hearing Shapes the Mind was released by Bloomsbury in September 2012.
—
REWIND! If you liked this post, check out …
Reproducing Traces of War: Listening to Gas Shell Bombardment, 1918– Brian Hanrahan
Learning to Listen Beyond Our Ears– Owen Marshall
This is Your Body on the Velvet Underground– Jacob Smith
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments