
SO! Reads: Steph Ceraso’s Sounding Composition: Multimodal Pedagogies for Embodied Listening

 Pedagogy at the convergence of sound studies and rhetoric/composition seems to exist in a quantum state—both everywhere and nowhere at the same time. This realization simultaneously enlightens and frustrates. The first page of Google results for “sound studies” and “writing instruction” turns up tons of pedagogy; almost all of it is aimed at instructors, pedagogues, and theorists, or contextualized in the form of specific syllabi. The same is true for similar searches—such as “sound studies” + “rhetoric and composition”—but one thing that remains constant is that Steph Ceraso, and her new book Sounding Composition (University of Pittsburgh Press: 2018) are always the first responses. This is because Ceraso’s book is largely the first to look directly into the deep territorial expanses of both sound studies and rhet/comp, which in themselves are more of a set of lenses for ever-expanding knowledges than deeply codified practices, and she dares to bring them together, rather than just talking about it. This alone is an act of academic bravery, and it works well.
Pedagogy at the convergence of sound studies and rhetoric/composition seems to exist in a quantum state—both everywhere and nowhere at the same time. This realization simultaneously enlightens and frustrates. The first page of Google results for “sound studies” and “writing instruction” turns up tons of pedagogy; almost all of it is aimed at instructors, pedagogues, and theorists, or contextualized in the form of specific syllabi. The same is true for similar searches—such as “sound studies” + “rhetoric and composition”—but one thing that remains constant is that Steph Ceraso, and her new book Sounding Composition (University of Pittsburgh Press: 2018) are always the first responses. This is because Ceraso’s book is largely the first to look directly into the deep territorial expanses of both sound studies and rhet/comp, which in themselves are more of a set of lenses for ever-expanding knowledges than deeply codified practices, and she dares to bring them together, rather than just talking about it. This alone is an act of academic bravery, and it works well.
Ceraso established her name early in the academic discourse surrounding digital and multimodal literacy and composition, and her work has been nothing short of groundbreaking. Because of her scholarly endeavors and her absolute passion for the subject, it is no surprise that some of us have waited for her first book with anticipation. Sounding Composition is a multivalent, ambitious work informs the discipline on many fronts. It is an act of ongoing scholarship that summarizes the state of the fields of digital composition and sonic rhetorics, as well as a pedagogical guide for teachers and students alike.
 Through rigorous scholarship and carefully considered writing, Ceraso manages to take many of the often-nervewracking buzzwords in the fields of digital composition and sonic rhetorics and breathe poetic life into them. Ceraso engages in the scholarship of her field by demystifying the its jargon, making accessible to a wide variety of audiences the scholar-specific language and concepts she sets forth and expands from previous scholarship (though it does occasionally feel trapped in the traditional alphabetic prison of academic communication).. Her passion as an educator and scholar infuses her work, and Ceraso’s ontology re-centers all experience–and thus the rhetoric and praxis of communicating that experience–back into the whole body. Furthermore, Ceraso’s writing makes the artificial distinctions between theory and practice dissolve into a mode of thought that is simultaneously conscious and affective, a difficult feat given her genre and medium of publication. Academic writing, especially in the form of a university press book, demands a sense of linearity and fixity that lacks the affordances of some digital formats in terms of envisioning a more organic flow between ideas. However, while the structure of her book broadly follows a standard academic structure, within that structure lies a carefully considered and deftly-organized substructure.
Through rigorous scholarship and carefully considered writing, Ceraso manages to take many of the often-nervewracking buzzwords in the fields of digital composition and sonic rhetorics and breathe poetic life into them. Ceraso engages in the scholarship of her field by demystifying the its jargon, making accessible to a wide variety of audiences the scholar-specific language and concepts she sets forth and expands from previous scholarship (though it does occasionally feel trapped in the traditional alphabetic prison of academic communication).. Her passion as an educator and scholar infuses her work, and Ceraso’s ontology re-centers all experience–and thus the rhetoric and praxis of communicating that experience–back into the whole body. Furthermore, Ceraso’s writing makes the artificial distinctions between theory and practice dissolve into a mode of thought that is simultaneously conscious and affective, a difficult feat given her genre and medium of publication. Academic writing, especially in the form of a university press book, demands a sense of linearity and fixity that lacks the affordances of some digital formats in terms of envisioning a more organic flow between ideas. However, while the structure of her book broadly follows a standard academic structure, within that structure lies a carefully considered and deftly-organized substructure.
Sounding Composition begins with a theory-based introduction in which Ceraso lays the book’s framework in terms of theory and structure. Then proceeds the chapter on the affective relationship between sound and the whole body. The next chapter investigates the relation of sonic environments and the body, followed by a chapter on our affective relationship with consumer products, in particular the automobile, perhaps the most American of factory-engineered soundscapes. Nested in these chapters is a rhetorical structure that portrays a sense of movement, but rather than moving from the personal out into spatial and consumer rhetorics, Sounding Composition’s chapter structure moves from an illustrative example that clearly explains the point Ceraso makes, into the theories she espouses, into a “reverberation” or a pedagogical discussion of an assignment that helps students better grasp and respond to the concepts providing the basis for her theory. This practice affords Ceraso meditation on her own practices as well as her students’ responses to them, perfectly demonstrating the metacognitive reflection that so thoroughly informs rhet/comp theory and praxis.

Steph Ceraso and students share a “sonic meal.” Photo by Marlayna Demond, UMBC.
Chapter one, “Sounding Bodies, Sounding Experience: (Re)Educating the Senses,” decenters the ears as the sole site of bodily interaction with sound. Ceraso focuses on Dame Evelyn Glennie, a deaf percussionist, who Ceraso claims can “provide a valuable model for understanding listening as a multimodal event” (29) because these practices expand listening to faculties that many, especially the auditorially able, often ignore. Dame Glennie theorizes, and lives, sound from the tactile ways its vibrations work on the whole body. From the new, more comprehensive understanding of sound Dame Glennie’s deafness affords, we can then do the work of “unlearning” our ableist auditory and listening practices, allowing all a more thorough reckoning with the way sound enables us to understand our environments.
The ability to transmit, disrupt, and alter the vibrational aspects of sound are key to understanding how we interact with sound in the world, the focus of the second chapter in Sounding Composition. In “Sounding Space, Composing Experience: The Ecological Practice of Sound Composition,” Ceraso situates her discussion in the interior of the building where she actually composed the chapter. The Common Room in the Cathedral of Learning, on the University of Pittsburgh’s main campus, is vast, ornate, and possessed of a sense of quiet which “seems odd for a bustling university space”(69). As Ceraso discovered, the room itself was designed to be both vast and quiet, as the goal was to produce a space that both aesthetically and physically represented the solemnity of education.

Cathedral of Learning Ceiling and Columns, University of Pittsburgh, Pittsburgh, Pennsylvania, Image by Flickr User Matthew Paulson (CC BY-NC-ND 2.0)
To ensure a taciturn sense of stillness, the building was constructed with acoustic tiles disguised as stones. These tiles serve to not only hearken back to solemn architecture but also to absorb sound and lend a reverent air of stillness, despite the commotion. The deeply intertwined ways in which we interact with sound in our environment is crucial to further developing Ceraso’s affective sonic philosophy. This lens enables Ceraso to draw together the multisensory ways sound is part of an ecology of the material aspects of the environment with the affective ways we interact with these characteristics. Ceraso focuses on the practices of acoustic designers to illustrate that sound can be manipulated and revised, that sound itself is a composition, a key to the pedagogy she later develops.
Framing the discussion of sound as designable—a media manipulated for a desired impact and to a desired audience–serves well in introducing the fourth chapter, which examines products designed to enhance consumer experience. “Sounding Cars, Selling Experience: Sound Design in Consumer Products,” moves on to discuss the in-car experience as a technologically designed site of multisensory listening. Ceraso chose the automobile as the subject of this chapter because of the expansive popularity of the automobile, but also because the ecology of sound inside the car is the product of intensive engineering that is then open to further manipulation by the consumer. Whereas environmental sonic ecologies can be designed for a desired effect, car audio is subject to a range of intentional manipulations on the listener. Investigating and theorizing the consumer realm not only opens the possibilities for further theorization, but also enhances the possibility that we might be more informed in our consumer interactions. Understanding the material aspects of multimodal sound also further informs and shapes disciplinary knowledge at the academic level, framing the rhetorical aspect of sonic design as product design so that it focuses on, and caters to, particular audiences for desired effects.

Heading Up the Mountain, Image by Flickr User Macfarland Maclean,(CC BY-NC-ND 2.0)
Sounding Composition is a useful and important book because it describes a new rhetoric and because of how it frames all sound as part of an affective ontology. Ceraso is not the first to envision this ontology, but she is the first to provide carefully considered composition pedagogy that addresses what this ontology looks like in the classroom, which are expressed in the sections in Sounding Composition marked as “Reverberations.” To underscore the body as the site of lived experience following chapter two, Ceraso’s “reverberation” ask students to think of an experience in which sound had a noticeable effect on their bodies and to design a multimodal composition that translates this experience to an audience of varying abledness. Along with the assignment, students must write an artist statement describing the project, reflecting on the composition process, and explaining each composer’s choices.
To encourage students to think of sound and space and the affective relationship between the two following chapter three, Ceraso developed a digital soundmap on soundcities.com and had students upload sounds to it, while also producing an artist statement similar to the assignment in the preceding chapter. Finally, in considering the consumer-ready object in composition after the automobile chapter, students worked in groups to play with and analyze a sound object, and to report back on the object’s influence on them physically and emotionally. After they performed this analysis, students are then tasked with thinking of a particular audience and creating a new sonic object or making an existing sonic object better, and to prototype the product and present it to the class. Ceraso follows each of these assignment descriptions with careful metacognitive reflection and revision.
Steph Ceraso interviewed by Eric Detweiler in April 2016, host of Rhetoricity podcast. They talked sound, pedagogy, accessibility, food, senses, design, space, earbuds, and more. You can also read a transcript of this episode.
While Sounding Composition contributes to scholarship on many levels, it’s praxis feels the most compelling to me. Ceraso’s love for the theory and pedagogy is clear–and contagious—but when she describes the growth and evolution of her assignments in practice, we are able to see the care that she has for students and their individual growth via sound rhetoric. To Ceraso, the sonic realm is not easily separated from any of the other sensory realms, and it is an overlooked though vitally important part of the way we experience, navigate, and make sense of the world. Ceraso’s aim to decenter the primacy of alphabetic text in creating, presenting, and formulating knowledge might initially appear somewhat contradictory, but the old guard will not die without a fight. It could be argued that this work and the knowledge it uncovers might be better represented outside of an academic text, but that might actually be the point. Multimodal composition is not the rule of the day and though the digital is our current realm, text is still the lingua franca. Though it may seem like it will never arrive, Ceraso is preparing us for the many different attunements the future will require.
—
Featured Image: Dame Evelyn Glennie Performing in London in 2011, image by Flickr User PowderPhotography (CC BY-NC-ND 2.0)
—
Airek Beauchampis an Assistant Professor of English at Arkansas State University and Editor-at Large for Sounding Out! His research interests include sound and the AIDS crisis, as well as swift and brutal punishment for any of the ghouls responsible for the escalation of the crisis in favor of political or financial profit. He fell in love in Arkansas, which he feels lends undue credence to a certain Rhianna song.
—
 REWIND! . . .If you liked this post, you may also dig:
REWIND! . . .If you liked this post, you may also dig:
Queer Timbres, Queered Elegy: Diamanda Galás’s The Plague Mass and the First Wave of the AIDS Crisis– Airek Beauchamp
Botanical Rhythms: A Field Guide to Plant Music -Carlo Patrão
Sounding Our Utopia: An Interview With Mileece–Maile Colbert
Share this:

What is a Voice?

 Welcome to Voices Carry. . . a forum meditating on the material production of human voices the social, historical, and political material freighting our voices in various contexts. What are voices? Where do they come from and how are their expressions carried? What information can voices carry? Why, how, and to what end? In today’s post, Alexis Deighton MacIntyre explores society’s interpretations of voicing, sounding and listening. Inspired by Christine Sun Kim and Evelyn Glennie, Alexis advocates for understanding voicing as movement and rhythm instead of strictly articulated sound. – SO! Intern Kaitlyn Liu
Welcome to Voices Carry. . . a forum meditating on the material production of human voices the social, historical, and political material freighting our voices in various contexts. What are voices? Where do they come from and how are their expressions carried? What information can voices carry? Why, how, and to what end? In today’s post, Alexis Deighton MacIntyre explores society’s interpretations of voicing, sounding and listening. Inspired by Christine Sun Kim and Evelyn Glennie, Alexis advocates for understanding voicing as movement and rhythm instead of strictly articulated sound. – SO! Intern Kaitlyn Liu
The following post is a companion to Alexis’ voicings essay published in the Journal of Interdisciplinary Voice Studies 3.2.
What is a voice, and what does it mean to voice?
Definitions of the voice may be pragmatic: working titles that depend in part on their institutional basis within ethnomusicology, literature, or psychoacoustics, for example.
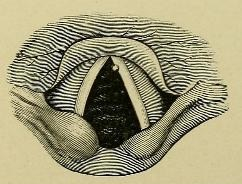
“Autoscopy of the larynx and trachea” by Flickr user Medical Heritage Library Inc.
Or, to take another strategy, voice is given by an impartial biological framework, a respiratory-laryngeal-oral assembly line. Its product, an acoustic signal, is transmitted via material vibration to an ear, and then a brain. The mind of a listener is this system’s endpoint. Although this functional description may smack of scientific reductionism, the otolaryngeal voice often stands in for embodiment in humanist discourse.
For Adriana Cavarero, the voice means “sonorous articulation[s] that emit from the mouth” (Caverero 2005, 14), involving “breath” and “[w]et membranes and taste buds” (134). Quoting Italo Calvino, she affirms that “a voice involves the throat, saliva.” According to Brandon Labelle, the mouth is “wrapped up in the voice, and the voice in the mouth, so much so that to theorize the performativity of the spoken is to confront the tongue, the teeth, the lips, and the throat” (Labelle 2014, 1). In Labelle’s view, orality is in fact overlooked, “disappearing under the looming notions of vocality” (8), such that his contribution to voice studies is to “remind the voice of its oral chamber” (4). Conclusions such as these inform our subsequent theoretical, methodological, and political theories of both voicing and listening.
Cavarero and Labelle are right to address the erasure of speaking and listening in Western intellectual history. However, to take for granted that voice is always audible sound, always sounded by a certain system, is to make the case for a fragmented brand of vocal embodiment. Rosi Braidotti terms this “organs without bodies”, and her critique of “instrumental denaturalisation,” whereby biotechnology transforms the body “into a factory of detachable pieces,” could also apply to the implicit processes by which discourse delineates the voice (Braidotti 1994, 59).

“Intersectional Souls” by Flickr user Makoto Sasaki
Yet, a priori constructs like “voice is sound” or “sound is [audibly] heard” have not gone unchallenged. For instance, scholars, artists, and musicians who engage with disability or Deafness resist or redefine taxonomies that ignore or distance other ways of voicing, sounding, and listening. Sarah Mayberry Scott blogs in SO! about the work of Christine Sun Kim, for example, whose performative practice reimagines Western musical norms through a Deaf lens. Kim’s uses of subsonic frequencies and face markers are two of many interventions by which she “reclaims sound” from an aural-centric worldview—not just for herself and other Deaf people, but for all bodies. Indeed, Kim invites hearing people to see and feel familiar social and environmental sounds, to rediscover inaudible channels for themselves, a praxis Jeannette DiBernardo Jones calls the “multimodality of hearing deafly” (DiBernardo Jones 2016, 65)
To hear deafly is thus to enter an expanded field of sound. The same is true of voicing deafly. Kim negotiates her audible voice by “trying on” interpreters, “guiding people to become [her] voice”, and by “leasing” out her own or “borrowing” another’s. But there are also features common to both spoken and signed voices that risk being lost to the spotlight of audition.

Face Opera with Christine Sun Kim as part of the Calder Foundation’s “They May As Well Have Been Remnants of the Boat”
For instance, spontaneous speech occurs with concurrent face, torso, arm, and hand movements. These voicing actions unfold in tight synchrony with words, sighs, and facial expressions. In the case of beat gestures, the “meaningless” strokes made with the hands, they are in fact temporally precedent to stressed syllables; that is, manual prosody is perceptually paired with vocal prosody, but materialises a fraction of a second earlier. When psychologists subtly perturb gestures in the hand, they record analogous effects in oral production. This hand-mouth network is even more evident in some non-Western hearing cultures that also use sign language, where distinguishing between spoken and gestured dialogue is both impractical and nonsensical. Taken together, it seems that the body distributes the voice, neither knowing nor caring for its own discursive fencings.
If gesture is a proprioception, or action-form, of vocality, haptic sensation is another way to hear. In her vibrational theory of music, Nina Sun Eidsheim argues that sound is not a static noun, but a process, such that the so-called musical object—or, indeed, any sonic figure—resists stable definition, but is rather contingent on the myriad ways of experiencing material pulsation. Via air, water, architecture, or people, the oscillatory basis of Eidsheim’s framework disrupts not only the divisions of labour amongst the Cartesian senses, but also those between sound, sound producer, and listener—unity from propagation. Such vibrations can be all-consuming, rendering the body, in Evelyn Glennie’s words, as “one huge ear.” They can also lurk, near the bass-end of traffic, or remain as a trace, as in dubstep, whose shuddering basslines connote tactility. Alluding to the scene’s origins in Jamaican sound system, the “wub” effect is the auditory fetishization of equipment failure, the resounding noise of a speaker pushed to uncontrolled, uncontainable movement.
In her TED Talk, Kim explains that “in Deaf culture, movement is equivalent to sound.” A feature common to most human movement is rhythm, the temporal patterns that emerge in speaking, walking, chewing, typing, weaving, hammering. As the banality of these actions suggests, rhythm permeates throughout everyday life. We join our rhythms in a process known to cognitive sciences as entrainment. Sunflowers entrain their circadian cycles to anticipate the path of the sun, fireflies entrain their flashes at a rate determined by species membership, and grebes, dolphins, and humans (among other animals) entrain their social actions. Neuroscientists theorize that even our neurons entrain to another’s speech, either spoken or signed. Simply put, entrainment is being together in time with someone, or some entity, sharing in a temporal perspective. So quotidian is the state of being entrained that we may not notice when we fall into step with a friend or anticipate our turn in a conversation. But it would not be possible without rhythm, which is both a shared construct through which we time our gestures sympathetically, and a sign of subjectivity, an identifier, a distinctive feature by which we can recognise ourselves or another.

Christine Sun Kim’s musical interpretation of the sign for the words “all night”
Rhythm could therefore form yet another (in)audible nexus within a relational definition of the voice, whose sites could include the larynx, face, hands, cochlea, and on and under the skin, in addition to various inorganic materials. In conversation with John Cage, the hearing composer Robert Ashley considered “time being uppermost as a definition of music,” music that “wouldn’t necessarily involve anything but the presence of people” (Reynolds, 1961). Although Ashley’s “radical redefinition” is stated in temporal terms, the concepts of time, rhythm, and movement are not easily disentangled. Plato explains rhythm as “an order of movement”, while for Jean Luc Nancy, rhythm is the “time of time, the vibration of time itself” (Nancy 2009, 17). As a cycle that is propagated through the medium of entrained bodies, rhythm may well be just another vibration, one suited to Eidsheim’s multisensory groundwork of tactile sound. As with music, the voice need not be “stable, knowable, and defined a priori” (Eidsheim 2015, 22), but dynamic, chimerical, and emergent. Speaking, slinking, signing, swaying—indeed, all our actions, gestures, and locomotions constitute us. Crucially, it is not what we move, but how we move, that is vocal.
_
Featured Image: “Vocal” by Flickr user ArrrRRT eDUarD
_
Alexis Deighton MacIntyre is a musician and PhD candidate in cognitive neuroscience at University College London, where she’s currently researching the control of respiration during rhythmic motor activities, like speech or music. Formerly, she studied cognitive science and music at University of Cambridge and Vancouver Island University. You can follow her on Twitter at @alexisdeighton or read her science blog at https://alexisdmacintyre.wordpress.com/
_
REWIND! . . .If you liked this post, you may also dig:
The Plasticity of Listening: Deafness and Sound Studies – Steph Ceraso
Re-Orienting Sound Studies’ Aural Fixation: Christine Sun Kim’s “Subjective Loudness” – Sarah Mayberry Scott
Mr. and Mrs. Talking Machine: The Euphonia, the Phonograph, and the Gendering of Nineteenth Century Mechanical Speech – J. Martin Vest
On “The Dream Life of Voice:” A Rerecording of Bernadette Mayer Reading from The Ethics of Sleep – John Melillo
Share this:






Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments