
Vocal Deformance and Performative Speech, or In Different Voices!

**This post was co-authored by Marit J. MacArthur and Lee M. Miller
Like it or not, we are now accustomed to contemporary pop vocalists manipulating their voices using Autotune and other tools or effects for pitch correction. We may exult in it, and congratulate ourselves on our sophisticated appreciation of the options available to the contemporary vocalist. In another mood, we may scream for low-fi and acoustic music, feel cynical about the possibility that we might ever hear an unmediated voice, live or recorded (if we ever did), and/or laugh off the notion of authenticity in performance entirely. Of course, rather than tricking the audience or trying to sound somehow “better” than they are, many performers manipulate their voices to pose questions about the nature of performance—Reggie Watts and Anna Deavere Smith come readily to mind—and to test essentialist assumptions about and perceptions of voice and sound.
Watts, in an exemplary 2012 TED Talk, plays with the different sorts of authority and affect conveyed by, among other voices: upper-class-British-absurd-explanatory, affectively-meaningful-nonsense-foreign-language, and caz-hip-hop-introducing-a-song-chat. Inhabiting and playing with different voices, he amuses listeners into recognizing how much intonation—the rise and fall of pitch—and other acoustic features affect our perception of a speaker’s voice, and how much we expect people to speak in ways that match our assumptions about their identities.
 We cannot all be so talented at vocal imitation, however. And in sound, voice and performance studies concerned with speech, machine-assisted manipulation of vocal recordings—which we term “vocal deformance”—is much less common than in the creative industries. A playful approach to vocal deformance, as a critical and creative practice, has much to teach us about our perceptions of speech in general, and performative speech in particular. Too often, when we use archival poetry recordings in our teaching, they may reify an idea that students are often loathe to relinquish: a poem is a finished art object, weighted with authorial intention and biographical significance, with one possible interpretation (the instructor’s). When we play a single canonical recording of T.S. Eliot reading The Waste Land in 1946, for instance, his particular intonation, together with assumptions that he was a stuffy, overeducated, repressed snob, can foreclose the possibility of a fresh encounter with the many voices of the poem and a multitude of interpretations.
We cannot all be so talented at vocal imitation, however. And in sound, voice and performance studies concerned with speech, machine-assisted manipulation of vocal recordings—which we term “vocal deformance”—is much less common than in the creative industries. A playful approach to vocal deformance, as a critical and creative practice, has much to teach us about our perceptions of speech in general, and performative speech in particular. Too often, when we use archival poetry recordings in our teaching, they may reify an idea that students are often loathe to relinquish: a poem is a finished art object, weighted with authorial intention and biographical significance, with one possible interpretation (the instructor’s). When we play a single canonical recording of T.S. Eliot reading The Waste Land in 1946, for instance, his particular intonation, together with assumptions that he was a stuffy, overeducated, repressed snob, can foreclose the possibility of a fresh encounter with the many voices of the poem and a multitude of interpretations.
Using vocal deformance in the classroom and in our own research and scholarship, we can unsettle overdetermined readings of poems, essentialist assumptions about the poets who speak them and questions of poetic authority, and recover the crucial oral components of poetry. Below we offer some examples of vocal deformance of poetry readings, and consider the potential and limits of this technique for teaching and research with recordings of performative speech. As John Hyland wrote in Sounding Out! in 2014, “The act of listening to recorded poetry … poses particular analytic challenges, which become more complex when the politics of identity are brought to bear on … questions of voice and poetry.” Among these challenges are essentialist assumptions, both about identity and recording medium, which are difficult to avoid when we listen. Hyland concludes that, when we listen to recordings, “the poet’s voice falsely takes on an authoritative ‘aura,’ as Walter Benjamin used that word”; one way to counter to this is to listen to the same poem read by the poet at different points in their career, in different contexts, as Hyland does with three recordings of Amiri Baraka’s “Black Dada Nihilismus.” Another approach is to play with recordings.
***

“Glitch” by Ray Weitzenberg, Attribution 2.0 Generic (CC BY 2.0)
***
The concept of deformance dates to a 1999 essay by Jerome McGann and Lisa Samuels. They take inspiration from Emily Dickinson, who sometimes liked to read poems backward, for the potential insights of reading against the form, scrambling the original sequence, and so on. According to McGann and Samuels, Dickinson’s
critical model is performative, not intellectual [. . . ]. it is anti-theoretical: not because it is opposed to theory (i.e., speculative thought), but because it places theory in a subordinated relation to practice. Deformative moves reinvestigate the terms … [of] critical commentary [, with] dramatic exposure of subjectivity as a live and highly informative option of interpretive commentary, if not indeed one of its essential features. [our italics]
Too often in the literature class room, the subjectivity of interpretation is something of a problem. While we might initially encourage a somewhat fluffy reader-response discussion of a poem, eventually we might also worry that students are simply wandering too far from it, following their own random associations with a phrase or metaphor, without learning to parse the rich intricacy of the whole poem. One effect of vocal deformance is that it makes space for the playful response, and also keeps bringing students back to the telling phrase, to the words of the poem, imagining what difference it makes if they are said in different ways, trying on different interpretations, as it were.
While vocal deformance can be applied to any performative speech, it particularly lends itself to poetry recordings. Poetry is, of course, an oral form with a fraught relationship between text and performance, and poetry reading styles are often perceived to be highly conventional, so that we feel we are listening to a Poem rather than a particular poem. From a literary and performance studies perspective, what could be more tiredly familiar than a canonical recording of a canonical poem by a canonical poet in a conventional style of poetry reading that deadens the audience to the charms and nuances of that poem? And how can we do something productive and interesting with the (sometimes extremely) idiosyncratic subjectivity of student responses to canonical texts?
As an interpretive practice, vocal deformance opens up new possibilities for testing assumptions about performance, poetic authority and gender, and, potentially, about race, class, education, region, and canonicity. Is The Waste Land (1922) the deadly serious poem that many readers often take it to be, partly because it is presented to them as an immensely influential Modernist monolith? How does T.S. Eliot’s seemingly grim reading of it, and our perception of his style, contribute to such an interpretation of the poem? After all, the working title of the poem was “He Do the Police in Different Voices,” from Charles Dickens’s Our Mutual Friend (1864-65), and it includes many different voices or speakers, from the clairvoyant Madame Sosistris to Tiresias. What better way to defamiliarize and exploit the authority of the poem than to deform Eliot’s authoritative reading voice?
How do we respond to the now-canonical voice of Eliot reading the opening lines of The Waste Land, “April is the cruellest month, breeding / lilacs out of the dead land”?
.
Okay. Now what if we raise his pitch? Is he suddenly his own great-aunt? What does the same lament mean, spoken by a voice that sounds like an elderly woman?
.
And if we leave his pitch alone, but speed up his speaking rate, does he suddenly sound like an old-school radio announcer, the poem a deranged weather forecast?
.

Glitch Decoration GIF, Licensed under CC-BY-SA 3.
In terms of digital humanities research, a refreshing aspect of vocal deformance is that it avoids some of the easy and misleading reassurances of the empirical move. It’s not that it only clarifies what we thought we were hearing (as visualizing intonation through pitch contours can), but that it encourages multiplicity in listening.
Vocal deformance is essentially a playful strategy for defamiliarization that reminds us, in many ways, of the subjective, creative, even arbitrary nature of interpretation. In this, it has clear affinities with the OULIPO movement (which Dickinson’s practice of reading backwards presages). It may help us imagine, create and respond to alternative sequences and versions of recorded canonical texts—and to any apparently stable, singular performance of a text. The art of the glitch is one deformative practice, with the goal countering screen essentialism, the unreflective assumption that a digital artefact is immutable, stable and coherent. For an example of glitching photographs, see Trevor Owens’s “Glitching Files for Understanding: Avoiding Screen Essentialism in Three Easy Steps,” and Michael Kramer’s blog post about using audio deformance in a digital folk music history seminar at Northwestern University, “Distorting History to Make It More Accurate,” which demonstrates some potential insights gained by glitching newspaper images, photographs and music (Bob Dylan’s “Tangled Up in Blue”). John Melillo and Johanna Skibsrud’s “Two Sides for Wallace Stevens,” on Harvard’s Woodberry Poetry Room site, also offers a beguiling example of audio deformance.
Most deformative practices work with text and image, however, and the few that manipulate recordings introduce noise, skipped phrases, repetition, etc., usually without changing the acoustic features of the voice. It is well worth applying deformance more often to speech, not only in linguistics and the neurobiology of speech perception, but in humanistic study of performative speech because our perception of speech is nothing if not subjective, not to say mysterious, for two reasons.
First, our expectations of what we will hear influence what we do hear, from simple sounds to complex language comprehension. Often these expectations, which can be visual, auditory, cultural, etc., have been naturalized by the listener over time as unconscious reactions. Though many have anecdotal experience of this phenomenon (see an example about a black student, a white teacher, and a black student-teacher disagreeing on what the student said in a 2012 Sounding Out! piece by Christina Sharpe), it is has been demonstrated in many experiments as well. For instance, our perception of foreign-accented speech changes rapidly as we hear a few sentences and calibrate our internal expectations, as shown by Clarke and Garret’s 2004 study “Rapid Adaptation to Foreign-accented English.” And, according to Richard Warren’s “Perceptural Restoration of Missing Speech Sounds” (1970), “when natural speech is interrupted by noisy gaps like a cough or a slammed door, we unknowingly “fill in” the noise, vividly hearing speech sounds that do not exist acoustically. This phenomenon arises both from linguistic expectations as well as our deep familiarity with basic speech acoustics, as shown in Shahin, Bishop, and Miller’s “Neural mechanisms for illusory filling-in of degraded speech.” Similarly, in an illusion called the McGurk effect—noted by Harry McGurk and John MacDonald in 1976—just seeing a talker’s lip movements changes the perception of speech sounds categorically, say from “buck” to “duck.”
Though much of this reshaping of our acoustic perception happens unconsciously, we can also profoundly alter what we hear through selective attention. Particularly in everyday acoustic environments, we hear speech better when we expect it, and when it matches our specific expectations: from a given location, from a certain talker or type of talker, at a certain pitch, and so on (See “Speech Recognition in Adverse Conditions: A Review” by Mattys, Davis, et al. 2012). Perceptual filters fundamentally constrain our experience: if we attend to a talker in one ear, we may not even realize when a second talker in the other ear switches from English to German, as Cherry concluded in “Some Experiments on the Recognition of Speech” in 1953. Social and cultural knowledge also changes what we hear. Listening to someone whom a listener visually perceives as a “non-native speaker” can make speech sound not only more “accented” (see Donald Rubin’s “Nonlanguage Factors Affecting S Judgments of Nonnative English-Speaking Teaching Assistants” from 1992)—what we might call a subjective quality—but, as Molly Babel and Jamie Russell found in 2015’s “Expectations and Speech Intelligibility,” it can also trigger speech processing reactions that make the speech less intelligible to the listener making visual judgments regarding accented speech.

Waveform from a sine wave composition, “Wave Hello to Outsiders.” Rendered in Adobe Audition by Matthew Potter. Attribution 2.0 Generic (CC BY 2.0)
Given what we know about the brain, the fact that expectations affect perception—of recorded voices reading poems, in this case—should not come as a surprise. A growing consensus holds that the brain’s job is not merely to represent the world; rather it strives to predict the world, make inferences about it, and correct those expectations whenever a mismatch is detected (see Knill and Pouget’s “The Bayesian brain: the role of uncertainty in neural coding and computation” [2004] and Karl Friston’s 2010 “The free-energy principle: a unified brain theory?”) In somewhat familiar environments and situations (pretty much everything after infancy), predictive inference is far more efficient than continually rendering the perceptual world de novo. This means that vocal deformance—particularly when it manipulates a known voice, as with canonical poets, or a familiar way of speaking, as with conventional poetry reading styles—waves a red flag at the brain. Change wakes up the quiescent, habitual brain to something new and potentially informative, because the voice does not fit our expectations for what the person would or should sound like. Listen to Reggie Watts!
This effect can also operate inversely; that is, if we do not expect someone to have a particular voice, we may adjust the stories we tell ourselves about our perceptions, to better match our expectations. In musicology, we might think of Nina Eidsheim’s article on the racialized reception of opera singer Marian Anderson, the first African American to sing at New York’s Metropolitan Opera:
the timbre of her voice has routinely (if often admiringly) been characterized as ‘black,’ … [despite] classical music’s minimal indulgence of individual style … this distinction [has] to be based on an assumption that the black body is intrinsically different from the white body and that even when emitting a timbre recognized as classical, the resonance of a singer’s black body is evident (3, 4).
Certainly, as Jennifer Stoever writes, “listening [is] an interpretive site where racial difference is coded, produced, and policed” (62). The same is true of gender difference and many other identity markers and cultural factors related to authority and authenticity. As Shai Burstyn notes in the article “In Quest of the Period Ear,” about attempts to imagine how contemporary audiences experienced medieval music, “culture plays a highly significant—though not exclusive—role in shaping the cognitive skills of its members” (695). If it is remarkably difficult to escape our stereotypical expectations and perceptions of what a person’s voice “should” sound like, that is partly because our brain uses such expectations to make predictions about our sonic experience. We cannot overcome our expectations through good will alone, and engaging with these issues in the classroom, which can be challenging, also provides an opportunity to help students think critically about essentialism and voice, for those moments when a student in the back of the room mutters in surprise that Langston Hughes “doesn’t sound black,” or exclaims that Walt Whitman “doesn’t sound gay.” Though it is not designed to assess stereotyping in speech perception, the Harvard implicit bias test is a good way to engage students in questions of cultural bias and perception [also, see “So You Flunked a Racism Test. Now What?”].
Furthermore, our affective responses to acoustic, non-verbal qualities of speech matter tremendously to our interpretation of verbal semantics, of the meaning of the words spoken. According to voice perception research in Foundations of Voice Studies: An Interdisciplinary Approach to Voice Production and Perception by Jody Kreiman and Diana Sidtis, when we listen to speech, “[s]ome authors … have claimed that normal adults usually believe the tone of voice rather than the words…. For example, the contrast in ‘I feel just fine’ spoken in a tense, tentative tone might be politely ignored, while, ‘I’m not angry’ spoken in hot anger would not” (304). The teacher’s boring tone of voice on the Peanuts cartoon makes the point.
In other words, we pick up on the affective meaning of a speaker’s tone of voice, and weigh it against the semantic meaning of the words spoken. While Kreiman and Sidtis argue that tone cannot be reduced to intonation patterns, “the fundamental frequency of the human voice [pitch] … heads the list of important cues for emotional meanings” (311). Pitch manipulation, then, changes the affective meaning of speech. Tone of voice is also influenced by other acoustic features, including speaking rate or tempo, and rhythm. In poetry recordings, the poet’s tone of voice influences the listener’s interpretation of a poem.
Two fundamental intonation patterns are rising or falling pitch. In American English, relatively high or relatively low pitch at the end of an utterance, compared to the beginning and middle, seems to carry distinct meanings, as demonstrated by Janet Pierrehumbert and Julia Hirschberg. They developed the ToBI (Tones and Break Indices) system for marking the prosody or intonation of speech. Rising intonation can make any utterance sound like a question, whether it is one or not. A relatively high pitch at the end of an utterance—called a high boundary tone—can make the speaker sound less confident or assertive, and more open to other’s opinions. Rising intonation implies that more is to come, that the utterance is not conclusive or concluded, that it should be understood in connection to the next utterance, and sometimes, that the speaker seeks the listener’s agreement before proceeding.
Uptalk, notably practiced among Generation Xers and now millennials, sounds conciliatory, agreeable and open, on the one hand, and lacking in confidence and authority, on the other—depending on the listener and the context. Marybeth Seitz-Brown argues that criticizing uptalk “implies that if women just spoke like men, our ideas would be valuable … [and] sexist listeners would magically understand us, and we would be taken seriously. But the problem is not with feminized qualities, of speech or otherwise, the problem is that our culture pathologizes feminine traits as something to be ashamed of or apologize for.”
Conversely, women can be criticized when they sound too much like men; see “Why Do So Many People Hate the Sound of Hillary Clinton’s Voice?” Falling intonation—and ending an utterance on a relatively low pitch, or a low boundary tone, implies conclusion, closure and confidence. The utterance, such intonation implies, finishes the argument (if there is one), does not seek the listener’s agreement or opinion, and suggests that this utterance can be understood on its own, without connection to subsequent utterances. Donald Trump, for example, is fond of falling intonation and low boundary tones (for a parody of masculine confident declarative intonation, have a listen at Troy McClure from The Simpsons.)
Of course, not all women use uptalk, and not all men use falling intonation with low boundary tones. In American culture, for better or worse, low boundary tones do seem to carry a tone of authority. And in poetry reading as well. Eliot’s original, and now canonical, reading of the opening line of The Waste Land, “April is the cruellest month,” uses falling intonation, so that it sounds like a confident assertion, with a low boundary tone on “month.”

Click on the image to enlarge the pitch contour graph showing Eliot’s low boundary tone.
.
“[B]reeding / lilacs out of the dead land” sounds like a steady, inevitable process, ending on a slightly higher relative pitch, implying that there is more to come, and that the phrase should be understood in connection to the next line, “mixing / Memory and desire, stirring / Dull roots with spring rain.”
What is so compelling and seemingly authoritative about Eliot’s reading style? In some basic sense, the falling intonation of the first phrase does it. Why does it strike many contemporary listeners as pompous? How might we undercut the seeming authority of the Eliotic voice? Make him do uptalk. Here we have simply inverted his intonation.
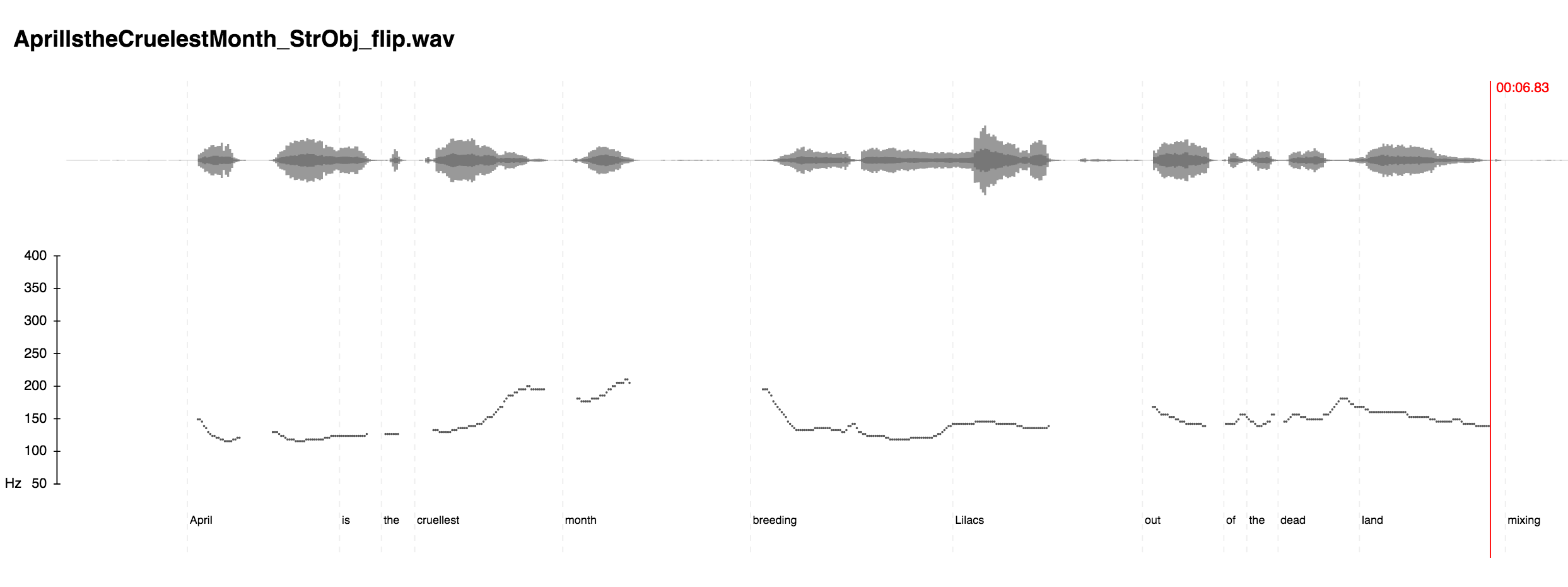
Click on the image to enlarge the pitch contour graph of Eliot’s voice “flipped.”
.
Suddenly he sounds doubtful. The opening line becomes a question—“April is the cruellest month[?]”—instead of a confident statement. Suddenly, Eliot himself expresses the skepticism or confusion many an undergraduate has felt—before we encountered this poem, did we not assume that spring, the return of life and fertility, is a cheerful escape from winter? And his deformed recital of “breeding / Lilacs out the dead land” suddenly sounds more like an agonized complaint, expressing the painful, reluctant awakening of desire in one who had found the dull sleep of winter comforting. Inverting the typical poetic authority of falling intonation into uptalk may embolden readers to entertain very different readings of the poem’s opening.
The editors of Poetry Archive had hopes of stimulating listeners of The Waste Land when they made available a 1935 recording of the poem, claiming: “Whilst the sound quality is understandably not so good, the recording is fascinating for Eliot’s faster, more energetic rendition. Listening to this urgent interpretation blows the dust of this iconic poem and helps us encounter it afresh.” However, if the fundamental falling intonation pattern of Eliot’s reading style doesn’t change—and overall, it doesn’t, between the 1935 and 1946 recordings—his voice may remain, for listeners, an aloof poetic authority.

Adrienne Rich reading her poetry
Falling intonation with low boundary tones, then, is a fundental tone of poetic authority. Listen to Adrienne Rich reading from her poem, “What Kind of Times Are These” (1995), which leads the reader to a place “between two stands of trees … near … [where] the persecuted / … disappeared into the shadows.” She insists, “this isn’t a Russian poem, this is not somewhere else but here,” and concludes, “to have you listen at all it’s necessary / to talk about trees.”

Click here to enlarge the pitch contour graph of Rich’s “original” reading
.
She sounds like she means it. Rich has to write poems about nature, her tone implies, to wake people up to the political horrors of the American past and present. Poetry as a form, in pastoral guise, allows her to sneak in political content, potentially grabbing the attention of people who might only listen to poetry if they think it is safely, simply about nature. (Click here to hear the entire poem, starting at 4:01.)
When we invert her intonation, turning it into uptalk, she sounds as if she is questioning the wisdom of this approach, and/or chiding her listeners for making her take it. In this case, uptalk exerts a different kind of authority, the challenging question.

Click image to enlarge the pitch contour graph of Rich’s voice “flipped.”
.
Is it ethical to manipulate the intonation and other vocal qualities on poetry recordings, for the purposes of teaching and research? Obviously it would not be, if we were to present the manipulated recordings as the authentic voice of a poet. And all peoples have the right to protect culturally sensitive recordings, such as sacred songs, music, dances and prayers; see “Native American Intellectual Property Issues.” Otherwise, potential conflicts are similar to those with sampling in the music industry (See Kembrew McLeod and Peter DiCola’s Creative License: The Law and Culture of Digital Sampling [2011]). Vocal deformance, however, can help remind us that no single reading of a poem, by the poet or someone else, is the ultimately authoritative one.

Photograph of Auden speaking at the Boston Sheraton Hotel, February 23, 1966, Box 60, Folder 9, Francis W. Sweeney, SJ, Humanities Series Director’s Records, MS2002-37, John J. Burns Library, Boston College. Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0)
In teaching writing, we (the authors) sometimes ask our students to explore alternative methods of presenting the same material. This can be as simple as writing the same sentence, the thesis for instance, in three different ways, or it can involve a different format. Write a poem, record oneself reading it, then try to represent it with a collage of images. Turn a 2,000-word essay into a 250-word presentation with verbal and sonic components. An instructive trick with the opening line of W.H. Auden’s “Musée des Beaux Arts” (1940): “About suffering they were never wrong, the Old Masters.” They were never wrong, the Old Masters, about suffering. The Old Masters were never wrong about suffering. Each version of the opening creates a subtly different emphasis, on suffering versus the wisdom of the Old Masters.
Too often, we lock ourselves into one approach, and cannot imagine an alternative. Locked into one approach, too often we cannot imagine an alternative. Alternatives we cannot imagine, if we lock into one approach too quickly. Writing three different opening paragraphs to the same essay, or rearranging the lines of the poem, stimulates our imagination and our critical faculties because it dramatizes different possibilities, possibilities that offer a different emphasis. And when we play with the pitch, intonation and speaking rate of a poem, this can change the tone as dramatically, from a challenge to confession, or an assertion into doubt.
In the classroom, poet Harryette Mullen is often popular with students, both for her poems on the page and for her expressive reading style, while students can sometimes resist recordings by Adrienne Rich (saying that she sounds lecture-y) and Louise Glück (saying that she sounds bored by her own poems), even as they are engaged by the poems on the page.
When Mullen reads “Present Tense” (2002)—a beguiling comical poem, loosely about the grammatical present and the speaker’s and the world’s present circumstances —what is it about her contrastive intonation that sounds expressive? She ends her opening phrases, “Now that my ears are connected to a random answer machine” with rising intonation and high boundary tones. This draws the reader on: keep listening, the statement’s not finished.

Click image to enlarge the pitch contour graph of Mullen’s reading
.
When we flip the intonation pattern, so that each utterance ends on a relatively low pitch, she sounds more conventional, a poetic authority declaring observations, confident and closed off.

Click image to enlarge the pitch contour graph of Mullen’s reading “flipped”
.
Another tone of poetic authority approaches pure monotony. It was practiced by Alfred Lord Tennyson, Irish modernist poet W.B. Yeats and, perhaps through Yeats’s influence, by American poets such as Yvor Winters. Note how similar they sound here. Winters reads the opening of his poem “The Journey” (1931), moving into a Yeatsian monotone after the title and location of Snake River Country, “I now remembered slowly how I came[.]”

Click here to enlarge the pitch contour graph of Winters reading “The Journey.”
.
Here is Yeats reading the opening of “The Lake Isle of Innisfree”: “I will arise and go now, and go to Innisfree[.]”

Click image to enlarge the pitch contour graph of Yeats reading “The Isle of Innisfree”
.
All we have to do to turn Winters into Yeats is raise his pitch a bit:

Click image to enlarge the pitch contour graph of “Winters as Yeats.”
.
Monotone performance is—at least acoustically—quite uninformative for the brain. Early parts of the auditory brain rapidly adapt or habituate to a wide array of regularities such as pitch and temporal pattern, and they only signal when the pattern changes, as noted in “Early selective-attention effect on evoked potential reinterpreted” (Näätänen, Gaillard et al., 1978). But expectations can work differently across speech’s descriptive dimensions. When speech is usually vivid, as in a direct quotation (“He said ‘I’m leaving now”), higher-level voice-processing areas in the right temporal lobe actually work harder to process (unexpectedly) monotone quotes, according to Yao, Belin, et al.’s “Brain ‘talks over’ boring quotes: top-down activation of voice-selective areas while listening to monotonous direct speech quotations” (2012). In other words, sameness of pitch often means the brain must work harder to grasp meaning.
Interestingly, David Hadbawnik relates in Sounding Out! his disappointment with the productions of three audio recordings of three poetic specimens from Middle English created with SPARSAR, because “they produced monotone outputs that fail to account for prosody.” Vocal deformance might allow him to try to approximate Middle English prosody with the specimens.
MacArthur has written elsewhere about “poet voice,” which she also calls “monotonous incantation.” But how close are contemporary canonical poets to actual monotone, compared to Tennyson and Yeats? Here is Glück, whose reading style is often mentioned as an example of Poet Voice, reading the third stanza of “The Wild Iris” (1992): “It is terrible to survive / as consciousness / buried in the dark earth”:

Click image to enlarge the pitch contour graph of Glück reading “The Wild Iris.”
.
Not much manipulation is required to make it purely monotone, which may account for some students saying she sounds bored by her own poems—though they do not say that about Yeats. They say Yeats’s voice makes them feel like they are in church.
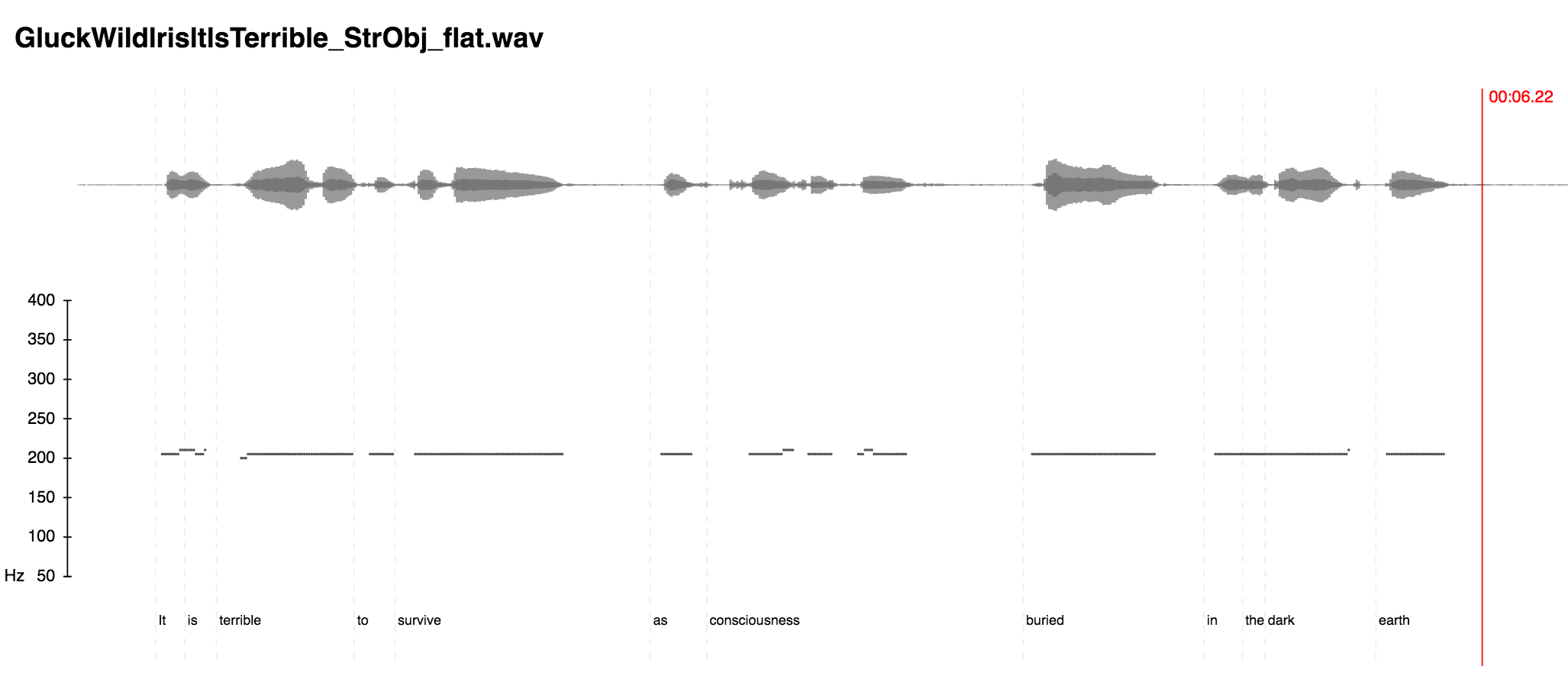
Click image to enlarge the pitch contour graph of Glück “flattened.”
.
Ideally, Glück’s manner of reading her poem should not prevent students from appreciating it. While in other contexts we may defend women’s use of uptalk, it also seems fair to raise the point that academic poetry reading can seem to discourage the expression of affect. (See Donald Hall’s well-known polemic, “The Poetry Reading: Public Performance / Private Art” (1985) and David Groff’s “The Peril of the Poetry Reading: Page Versus Performance” [2005].) Vocal deformance, among other strategies, might help students perceive as much drama in Glück’s poems as they do in Mullen’s—and find as much as poetic authority in both poets’ voices as they do in Yeats’s churchy one. Here, we’ve manipulated Glück’s voice to sound more like Mullen’s style of reading, with a wider pitch range and rising intonation and high boundary tones.

Click image to enlarge the pitch contour graph of Glück reading “expressively.”
.
If we want to explore alternatives to conventional modes of reading poetry, as many do, directly deforming the acoustic qualities of canonical recordings is an excellent way to defamiliarize performance conventions. Ideally, it can help us listen to alternate versions of the history of poetic performance and to different, unimagined possibilities in the present. Given the extraordinary vitality of spoken word and slam poetry outside the academy, it would be a missed opportunity to suppress varied reading styles in the classroom. At the same time, it would be a great shame to leave behind canonical American poetry when the poets’ reading styles fail to appeal to students.
Finally, if we want to liberate students from the anti-performative tendencies of academic culture, resist essentialist readings of poems according to our assumptions about the identities of the poets who wrote them, and dramatize the idea that there are many ways to read a poem, vocal deformance can help, alongside other strategies. As Yvon Bonenfant wrote in a 2014 Sounding Out! piece, “we are mostly neurotic, or otherwise hung up on, what kinds of sounds we make, where and when.”
Instead, let’s play in different voices.
—
NOTE: To illustrate vocal deformance, we used Straight, a state-of-the-art open-source voice synthesis program developed by Hideki Kawahara at Wakayama University in Japan, with the Advanced Telecommunications Research Institute and the Auditory Brain Project. We also used Drift, an open-source pitch-tracking tool that uses an algorithm developed by Byung Suk Lee and Dan Ellis, implemented by Robert Ochshorn and Max Hawkins with support from MacArthur’s ACLS Digital Innovations Fellowship in 2015-16, to visualize intonation with pitch contours.
—
Marit J. MacArthur is associate professor of English at California State University, Bakersfield, and a research associate in Cinema and Digital Media at the University of California, Davis.
Lee M. Miller is associate professor of Neurobiology, Physiology, & Behavior at the University of California, Davis, and technical director of the Center for Mind and Brain.
—
Featured Image: Cropped and Enlarged version of Bill Smith’s “Voice Glitch,” Attribution 2.0 Generic (CC BY 2.0)
—
 REWIND! . . .If you liked this post, you may also dig:
REWIND! . . .If you liked this post, you may also dig:
A Listening Mind: Sound Learning in a Literature Classroom–Nicole Furlonge
Audio Culture Studies: Scaffolding a Sequence of Assignments–Jentery Sayers
“HOW YOU SOUND??”: The Poet’s Voice, Aura, and the Challenge of Listening to Poetry–John Hyland
Hearing the Tenor of the Vendler/Dove Conversation: Race, Listening, and the “Noise” of Texts–Christina Sharpe
Share this:

“All their ioynts & properties”: Orthography and Sound in Early English Poetry

 Each of the essays in this month’s “Medieval Sound” forum focuses on sound as it, according to Steve Goodman’s essay “The Ontology of Vibrational Force,” in The Sound Studies Reader, “comes to the rescue of thought rather than the inverse, forcing it to vibrate, loosening up its organized or petrified body (70). These investigations into medieval sound lend themselves to a variety of presentation methods loosening up the “petrified body” of academic presentation. Each essay challenges concepts of how to hear the Middle Ages and how the sounds of the Middle Ages continue to echo in our own soundscapes.
Each of the essays in this month’s “Medieval Sound” forum focuses on sound as it, according to Steve Goodman’s essay “The Ontology of Vibrational Force,” in The Sound Studies Reader, “comes to the rescue of thought rather than the inverse, forcing it to vibrate, loosening up its organized or petrified body (70). These investigations into medieval sound lend themselves to a variety of presentation methods loosening up the “petrified body” of academic presentation. Each essay challenges concepts of how to hear the Middle Ages and how the sounds of the Middle Ages continue to echo in our own soundscapes.
The posts in this series begins an ongoing conversation about medieval sound in Sounding Out!. Our opening gambit in April 2016, “Multimodality and Lyric Sound,” reframes how we consider the lyric from England to Spain, from the twelfth through the sixteenth centuries, pushing ideas of openness, flexibility, and productive creativity. We will post several follow-ups throughout the rest of 2016 focusing on “Remediating Medieval Sound.” And, HEAR YE!, in April 2017, look for a second series on Aural Ecologies of noise! –Guest Editors Dorothy Kim and Christopher Roman
–
During the “grammar wars” of the sixteenth century, when some scholars sought to restrict English letters to an “isomorphic” (or phonemic) relationship between sound and spelling, Richard Mulcaster emerged as a champion of a more broad and complex vernacular orthography in his 1582 Elementarie, with profound implications for the growing English language. In particular, Mulcaster’s insight that language is shaped by “custom” bolsters the argument for variety over phonemic standardization; as he writes (in the 1925 Oxford University Press reprint):
letters ca[n] expresse sou[n]ds withall their ioynts & properties, no fuller than the pencill can the form and lineaments of the face, whose praise is not life but likeness: as the letters yeld not alwaie the same, which sound exactlie requireth, but allwaie the nearest, wherwith custom is content (99).
Mulcaster seems to strongly indicate here that we should not expect vernacular orthography to capture sound in any reliable way. Custom – meaning actual usage, etymological roots, and so on, muddies the waters of spelling-based sound. Anyone familiar with Modern English, given its complex conventions and silent, or variably pronounced letters, might agree. Yet as John Wesley notes in “Mulcaster’s Tyrant Sound,” “Mulcaster’s orthography continually oscillates … between a conception of letters as completely divorced from sound, and one that finds sound and sight interacting (not always in conflict)” (349).
Indeed, looking more closely at Mulcaster’s statement, it is possible to discern the specter of a scribe, pencil in hand, attempting to capture the “joints and properties” of a poet’s sound in letters – using different letters depending on the dialectal orthography of the compositional time and space: a listening body making a visual representation of sound.

Image of a scribe by Nathan Adams @Flickr CC BY-NC-ND
Certainly, we encounter instances of orthographical representations of distinctive sounds in more recent and deliberate dialect poetry. John Hyland, writing on sound and African diasporic poetry in his unpublished dissertation Atlantic Reverberations, notes of late nineteenth- / early twentieth-century black dialect poems that “in a certain way, they are meant to be read and heard as talking machines. The sound technology, in this case, is the poem; it is a construction and a recording of a ‘black’ voice that socially and culturally functions in a manner analogous to the gramophone” (31). [Ed. Note: you can also read his work on Sounding Out! here]. Following this, it is interesting to try to figure out how the text of a poem can gesture toward and suggest a “sound” that belongs to a localized (even stereotyped) body, despite the text’s being mute on the page. New computational linguistic programs can help play back these ancient sound files, but based on my experience in using them with Middle English texts, there is a ways to go in matching their analytic capabilities with idiosyncratic early English spelling to produce satisfying results.
While late medieval English poems cannot be thought of as deliberate “constructions” of a voice in quite the same way as some contemporary forms of black poetry—although portions of Chaucer’s The Reeve’s Tale, in which “northern speech” is represented through alternate spellings and diction, might be an exception—I propose that we imagine orthography (and by extension, the scribes who implemented it) as a kind of “sound technology” analogous to early sound reproduction devices such as the phonograph. The analogy will break down at certain points, but in suggesting it I hope to answer two related questions: First, to what extent can orthography reliably encode sound (or, to put it another way, offer a score for “decoding” sound)? Second, can we extend back in time the critique of sound technology made by recent “sound theorists,” who tend to focus on texts and technologies from the modern period – and, if so, what can be gained thereby?

A medieval alphabet. Image by Cesar Ojeda @Flickr CC BY-NC-ND
The answer to the first question is, I believe, a very qualified “yes.” Yes, English orthography can and does encode sound, but like so many things about the English language and its highly idiosyncratic spelling conventions, it’s complicated. The second question leads to an elusive, but promising, framework in which to consider the role of orthography in shaping English poetic sound. In short, I will argue that orthographic profiles act as a sort of “performance” in which spelling collaborates with the sound of language to offer a socio-linguistic context within which to experience a given poem.s
I used SPARSAR, “an expressive poetry reader” developed by computational linguists Rodolfo Delmonte and Anton Maria Prati, to produce audio recordings of three poetic specimens from Middle English: The specimens are: Osbern Bokenham’s “Life of St. Anne,” (ll. 41-64); Geoffrey Chaucer’s The Franklin’s Prologue, (V.709-28); and John Audelay’s “Conclusion,” (ll.1-13). The specimens were chosen with the idea of dialectal variety in mind: Bokenham is associated with Suffolk, Chaucer with London, and Audelay with the West Midlands. According to its creators, SPARSAR uses “prosodic durational parameters” for English syllables developed by the authors with the aim of “evaluat[ing] objective presumed syllable and feet prosodic distribution at line level,” producing a version of a poem that can be read by Text to Speech (TTS) software with “an appropriate expressivity” (73).
The problem with TTS software is that it produces monotone outputs that fail to account for prosody, let alone expressivity. SPARSAR, I hoped, would “level the playing field” between differing orthographies in the poems, from an analytic standpoint: “the poem is translated into a phonetic form preserving its visual structure and its subdivision into lines and stanzas. Phonetically translated words are associated to mean duration values taking into account position in the word and stress” (Delmonte and Prati 74). Yet textual analysis of poems in Middle English is challenging precisely because of orthographical variation, and this holds true for SPARSAR as well. Before SPARSAR could recognize the speech of the poems, I had to run them through a “normalizing” program—VARD, although Morphadorner offers a similar service—thus in some ways defeating the purpose of testing orthography’s ability to encode sound, as well as muddling SPARSAR’s fine-grained prosodic analysis.
Audelay first with and then without SPARSER.

Audelay for VARD. Image used with permission by the author.
Thus, for example, in the second line of my selection from John Audelay, “Here may ye cnow hwat ys this worlde,” I replaced “cnow” with the modern “know” (thus losing the /k/ sound), “hwat” with “what,” “ys” with “is,” and “worlde” with “world.” One easily discerns the loss of information with respect to not only sound, but also scansion (the inflectional “e” ending). SPARSAR also does not account for the Great Vowel Shift in reproducing Middle English pronunciations. For how this would change the pronunciation of some words, see Simon Horobin, Does Spelling Matter? (2013).
The recordings produced by the resulting SPARSAR files are, then, a record of failure with respect to my project. But they are instructive failures, nonetheless, and I include them here alongside the “raw” TTS recordings of the poems to illustrate my point: orthography is a key way of encoding sound, yielding both geographic and temporal sonic data. Moreover, such failures – and they are inevitable to a certain extent in any digital analysis of pre-modern English – point out the urgent need to work ever backwards and include ever more variant spellings in software databases. I am reminded of the comical difficulties that iPhone’s Siri software has in deciphering Scots English, though in that scenario the trouble is not necessarily with orthography, but accent.
Imagine, however, Siri attempting to decipher an accurately voiced reading of a Robert Burns poem based on its textual appearance.
Echoing Mulcaster’s statement on orthography, Ralph H. Emerson writes in “English Spelling and Its Relation to Sound” that “alphabetic spelling … [can] be a kind of backbone that supports the flesh and muscle of all the phonetic and phonemic variants in different dialects and idiolects” (260). The problem, as Mulcaster would point out, is the matter of those phonemic variants, a point Emerson concedes: “Western orthography … is largely a tale of how people have squeezed as many values as possible out of the very short Roman alphabet” (262). As Simon Horobin writes, the phoneme /r/ is pronounced differently in England even among different speakers of Northern dialect; the various realizations of /r/ that do not alter meaning require the designation of an “allophone”: [r] (21). In order to encode all the various pronunciations, we would need further phonemic symbols. At the risk of oversimplifying several hundred years of the development of spelling conventions in English, the desire for a less arbitrary connection between letter and sound is at the heart of the debates and attempted reforms in which grammarians like Mulcaster were involved.
Bokenham first with and then without SPARSER.

Bokenham for VARD. Image used with permission by the author.
Yet as much as Mulcaster argues for an orthography freed from “tyrant sound,” as Wesley notes, his arguments keep circling back to sound’s importance. Wesley writes, “Despite his claims regarding the ‘heard’ Z and its subjugation to the ‘sene’ S, the sound of Z creates a variety of problems for Mulcaster; in fact, its sound means Mulcaster must adjust the appearance and frequency of various other letters” (348). The reason for this is the complex set of rules in English regarding how letters interact with and influence each other in shaping the sound of a word. A more systematic analysis of these rules is precisely what allows Emerson to argue that orthography can, in fact, encode sound in English. He writes, “almost any dialect can be described as a plausible and usually predictable realization of the spelling, one word at a time” (265). Emerson describes a “four-step process” for this spelling-based description, which begins with “segment[ing] the spelling into elemental graphemes”; then “assign[ing] the segments their proper graphophonemes, that is, their abstract but systematically universal protovalues.” The next step “shows how the graphophonemes are phonemically realized in particular circumstances within individual dialects.” The example Emerson gives is “hair,” which segments into “H + AI + R, or //her//” (265). From this, he argues, we can reliably derive all the variant pronunciations of “hair.” To complete the process, a litereme is needed; e.g., the litereme <<s>> matches the phoneme //s// but also provides the “natural characteristic spelling” that expresses the “s” and “soft c” in English (266). Emerson concludes,
To describe how spelling encodes sound in a particular language is simply to chart the relationships between segments on these different levels … the litereme is the key: THAT is what everything else is really standing for, spellings and sounds and graphophonemes alike. (The letters themselves can be thought of as archiliteremes, with <<C>>having the reflexes <<k>> and <<s>>, <<A>> having <<ā>> and <<ă>>, etc.) … The simple universal phonology of written English gives birth to the infinite particularities of spoken English. (267)
Fortunately – for the purposes of looking at orthographically expressed Middle English variants, “present orthography still represents the pronunciation of Middle English” (Emerson 267). Unfortunately, though the letter-to-sound relationship in Middle English is much closer, we cannot be sure what those pronunciations were. But we can guess, and orthography is our best (perhaps only) clue.

From letters to sounds. Image by Michael Summers @Flickr CC BY-NC-ND.
The notion of “suggested” pronunciation is indeed where sound studies offers a compelling model for considering the relationship between poem and scribe, and how the former is recorded orthographically by the latter. Jonathan Sterne’s The Audible Past proposes to construct a “history of sound” that troubles the notion of “face to face” communication as being more “authentic” than sound reproduction technologies, adding, “This history of sound begins by positing sound, hearing, and listening as historical problems rather than as constants on which to build a history” (22). As medievalists know all too well, scribes and scribal variation in the copying of texts constitute a rich field of study when it comes to the question of textual “authenticity.”
Intriguing in light of such variation is Sterne’s idea of “transducers, which turn sound into something else and that something else back into sound” (22) – for which we might read orthography as a kind of technology with “moving parts” that work in concert to reproduce sound, as outlined above. More intriguing, perhaps, is Sterne’s description of the development of “audile technique,” a “practice of listening” that he bases on a study of “virtuosic and highly technical listening skills” during the nineteenth century and the advent of the telegraph, phonograph, and telephone. Sterne writes that with audile technique:
listening became more directional and directed, more oriented toward constructs of private space and private property. The construct of acoustic space as private space in turn made it possible for sound to become a commodity. Audile technique did not occur in the collective, communal space of oral discourse and tradition (if such a space ever existed); it happened in a highly segmented, isolated, individuated acoustic space (24).
In this context, Chaucer’s famous admonition to his scribe “Adam” becomes all the more charged and suggestive (650 in The Riverside Chaucer). We must certainly think of medieval scribes as early practitioners of “audile technique,” taking advantage of orthography as a tool by which to turn sound into a commodity in the form of manuscripts for various occasions and audiences.
Chaucer first with and then without SPARSER.

Chaucer for VARD. Image used with permission by the author.
Rethinking medieval texts in this way leaves us with a collaborative sonic performance in which the particular orthographies of the scribes help to pull an author’s text into a certain sound-space, even if it is inexact and in some sense inauthentic. Our ability to “hear” that space, to share it, is limited by our limited mapping of the incredibly multiform ways that English was uttered, and how those utterances were scored on the page by poets and scribes. Wesley notes the importance of discipline to Mulcaster’s educational-grammatical program as set forth in the Elementarie; discipline also hovers over the listening bodies performing audile technique for the sake of increasingly commodified sound spaces described by Sterne. English letters resist such discipline, sliding around various orthographies depending on time, place, poet, and scribe. In order to begin to use programs like SPARSAR to recreate, however tentatively, the sound they encode, we must loosen the standardizing discipline of our technology in parsing letters of the past.
—
Featured image “Mixed Media Painting” by See-ming Lee @Flickr CC BY-SA
—
David Hadbawnik is a poet, translator, and medieval scholar. His Aeneid Books 1-6 were published by Shearsman Books in 2015. He is the editor and publisher of Habenicht Press and the journal kadar koli, a co-editor of eth press, which focuses on creative interactions with medieval texts, and associate director of punctum books. Currently, he is an Assistant Professor of English at the American University of Kuwait.
—
REWIND! . . .If you liked this post, you may also dig:
The Hysterical Alphabet–John Corbett, Terri Kapsalis, and Danny Thompson
The Eldrich Voice: H.P. Lovecraft’s Weird Phonography–James A. Steintrager
Mouthing the Passion: Richard Rolle’s Soundscapes–Christopher Roman
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments