
Listen to the Sound of My Voice

Betrayal
I first realized there was a problem with my voice on the first day of tenth grade English class. The teacher, Mrs. C, had a formidable reputation of strictness and high standards. She had us sit in alphabetical order row after row, and then insisted on calling roll aloud while she sat at her desk. Each name emerged as both a command and a threat in her firm voice.
“Kelly Barfield?”
“Here,” I mumbled quietly. I was a Honor Roll student with consistent good grades, all A’s and one B on each report card, yet I was shy and softspoken in classes. This was an excellent way to make teachers amiable but largely go unnoticed. The softness of my voice made me less visible and less recognizable.
Mrs. C repeated my name. Caught off guard, I repeated “here” a little more loudly. She rose to her feet to get a better look at me. I knew what she saw: a petite girl with long ash blonde hair, big brown eyes, and overalls embroidered with white daisies on the bib. When her gaze finally met mine, Mrs. C frowned at me and cleared her throat loudly. I curled into my desk, hoping to disappear.

“Lincoln High School 9-16-2007 008” by Flickr user Paul Horst, CC BY-NC 2.0
“Miss Barfield, did you hear me call your name twice? In this class, when I call roll, you respond.” I gave a quick nod, but Mrs. C wasn’t finished: “We use our strong voices in here, not our girly, breathy ones.” My cheeks flushed red while Mrs. C droned on about confidence and classroom expectations.
“Do you understand me?”
I stammered a “yes.” Mrs. C turned her attention back to the roll call. Her harsh words rang in my ears. I sank low in my chair, humiliated and angry. I couldn’t help that I sounded girly: I was, in fact, a girl. This was the way my voice sounded. It was not an attempt to sound like the dumb blonde she appeared to think I was.
That day I decided that I would never speak up in her class. Forget the Honor Roll. If the sound of my voice was such a problem, then my mouth would remain firmly shut in this class and all of my others. I would never speak up again.

“Listen” by Flickr user lambda_x, CC BY-ND 2.0
My vow to stop speaking lived a short life. I enjoyed Mrs. C’s serious fixation on diagramming sentences and her attempts to show sophomores that literature offered ideas and worlds we didn’t quite know. At first, I spoke up with hesitation and fear of the inevitable dismissal, but I continued to speak. Becoming louder became my method to seem confident, even when I felt anything but.
Throughout high school, my voice emerged again and again as a problem. Despite the increased volume, my voice still sounded tremulous, squeaky, hesitant, and shrill to my own ears. Other girls had these steady, warm voices that encouraged others to listen to them. Some had higher voices that were melodic and lovely. I craved a lower, more resonant voice, but I was stuck with what I had. In drama club, our director scolded me with increasing frustration about my tendency to end my lines in the form of a question. My nerves materialized as upspeak. The more he yelled at me, the more pronounced the habit became. He eventually gave up, disgusted by my inability to control my vocal patterns.

By Dvortygirl, Mysid [GFDL (http://www.gnu.org/copyleft/fdl.html) or CC-BY-SA-3.0 (http://creativecommons.org/licenses/by-sa/3.0/)%5D, via Wikimedia Commons
Meanwhile, at a big state university in my native Florida, I learned quickly that a Southern accent marks you as a dumb redneck from some rural town that no one had heard of. Students in my classes asked me to say particular words and then giggled at my pronunciations. “You sound like a Southern belle,” one student noted. This was not really a compliment. According to my peers, Southern belles didn’t have a place in the classroom. Southern belles didn’t easily match up with “college student. As a working-class girl from a trailer park, I learned that I surely didn’t sound like a college student should. I worked desperately to rid myself of any hint of twang. I dropped y’all and reckon.
I listened carefully to how other students talked. I mimicked their speech patterns by being more abrupt and deadpan, slowly killing my drawl. When I finally removed all traces of my hometown from my voice, my friends both from home and from college explained that now I sounded like an extra from Clueless. My voice was all Valley girl. I was smarter, they noted with humor, than I sounded and looked. My voice now alternated between high-pitched and fried. Occasionally, it would squeak or crack. I thought I sounded too feminine and too much like an airhead, even when I avidly tried not to. I began to hate the sound of my voice.
My voice betrayed me because it refused to sound like I thought I needed it to. It refused to sound like anyone but me.
When I started teaching and receiving student evaluations, my voice became the target for students to express their displeasure with the course and me. According to students, my voice was too high and grating. Screechy, even: one student said my voice was at a frequency that only bats could hear. In every set of evaluations, a handful of students declared that I sounded annoying. This experience, however, was not something I alone faced. Women professors and lecturers routinely face gender bias in teaching evaluations. According to the interactive chart, Gender Language in Teaching Evaluations, female professors are more likely to be called “annoying” than their male counterparts in all 25 disciplines evaluated. The sound of my voice was only part of the problem, but I couldn’t help but wonder if how I sounded was an obstacle to what I was teaching them.
Once again, I tried to fix my problematic voice. I lowered it. I listened to NPR hosts in my search for a smooth, accentless, and educated sound, and I attempted to create a sound more like them. I practiced pronouncing words like they did. I modulated my volume. I paid careful attention to the length of my vowels. I avoided my natural drawl. None of my attempts seemed to last. Some days, I dreaded lecturing in my courses. I had to speak, but I didn’t want to. I wondered if my students listened, but I wondered more about what they heard.
Sound
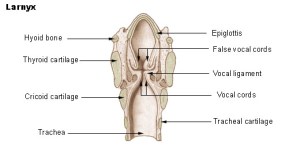
Public Domain, https://commons.wikimedia.org/w/index.php?curid=1393933
The sound of your voice is a distinct trait of each human being, created by your lungs, the length of your vocal cords, and your larnyx. Your lungs provide the air pressure to vibrate your vocal cords. The muscles of your larnyx adjust both the length and the tension of the cords to provide pitch and tone. Your voice is how you sound beyond the resonances that you hear when you speak. It is dependent on both the length and thickness of the vocal cords. Biology determines your pitch and tone. Your pitch is a result of the rate at which your vocal cords vibrate. The faster the rate, the higher your voice. Women tend to have shorter cords than men, which makes our voices higher.
Emotion also alters pitch. Fright, excitement, and nervousness all make your voice sound higher. Nerves would make a teenage girl have an even higher voice than she normally would. Her anxious adult self would too. Her voice would seem tinny because her larnyx clenched her vocal cords tight. Perhaps this is the only sound she can make. Perhaps she is trying to communicate with bats because they at least would attempt to listen.
Biology, the body, gives us the voices we have. Biology doesn’t care if we like the ways in which we sound. Biology might not care, but culture is the real asshole. Culture marks a voice as weak, grating, shrill, or hard to listen to.

“Speak” by Flickr user Megara Tegal, CC BY-NC-ND 2.0
My attempts to change my voice were always destined to fail. I fought against my body and lost. I couldn’t have won even if I tried harder. My vocal cords are determined that my voice would be high, so it is. The culture around me, however, taught me to hate myself for it. Voice and body seem to cast aspersions on intelligence or credentials. It’s the routineness of it all that wears on me. I expect the reactions now.
I wonder if I’m drawn to the quietness of writing because I don’t have to hear myself speak. I crave the silence while simultaneously bristling at it. Why is my voice a problem that I must resolve to placate others? How can I get others to hear me and not the stereotypes that have chased me for years?
Fury
My silence has become fruitful. The words I don’t say appear on the page of an essay, a post, or an article. I type them up. I read aloud what I first refused to say. I wince as I hear my voice reciting my words. I listen carefully to the cadence and tone. This separation of words and voice is why writing appeals to me. I can say what I want to say without the sound of my voice causing things to go awry.
People can read what I write, yet they can’t dismiss my voice by its sound. Instead, they read what I have to say. They imagine my voice; my actual sound can’t bother them. But, they aren’t really hearing me. They just have my words on the page. They don’t know how I wrap the sound around them. They don’t hear me.
Rebecca Solnit, in “Men Explain Things to Me,” writes “Credibility is a basic survival tool.” Solnit continues that to be credible is to be audible. We must be heard to for our credibility to be realized. This right to speak is crucial to Solnit. Too many women have been silenced. Too many men refuse to listen. To speak is essential “to survival, to dignity, and to liberty.”

“Listen” by Flickr user Emily Flores, CC BY-ND 2.0
I agree with her. I underline her words. I say them aloud. The more I engage with her argument, the more I worry. What about our right to be heard? When women speak, do people listen? Women can speak and speak and speak and never be heard. Our words dismissed because of gender and sound. Being able to speak is not enough, we need to be heard.
We get caught up in the power of speaking, but we forget that there’s power in listening too. Listening is political. It is act of compassion and empathy. When we listen, we make space for other people, their stories, their voices. We grant them room to be. We let them inhabit our world, and for a moment, we inhabit theirs. Yes, we need to be able to speak, but the world also needs to be ready to listen us.
We need to be listened to. Will you hear me? Will you hear us? Will you grant us room to be?
When I think of times I’ve been silenced and of the times I haven’t been heard, I feel the sharp pain of exclusion, of realizing that my personhood didn’t matter because of how I sounded. I remember the burning anger because no one would listen. I think of the way that silence and the policing of how I sound made me feel small, unimportant, or disposable. As a teenager, a college student, and a grown woman, I wanted to be heard, but couldn’t figure out exactly how to make that happen. I blamed my voice for a problem that wasn’t its fault. My voice wasn’t the problem at all; the problem was the failure of others to listen.

“listen” by Flickr user Jay Morrison, CC BY-NC-ND 2.0
Loss
While writing this essay on my voice, I almost lost mine, not once but twice. I caught a cold and then the flu. My throat ached, and I found it difficult to swallow. A stuffy nose gave my voice a muted quality, but then, it sounded lower and huskier. I could hear the congestion disrupting the timber of my words. My voice blipped in and out as I were radio finding and losing signal. It hurt to speak, so I was quiet.
“You sound awful,” my husband said in passing. He was right. My voice sounded unfamiliar and monstrous. I tested out this version of my voice. It was rougher and almost masculine. I can’t decide if this is the stronger, more authoritative voice I wanted all along or some crude mockery of what I can never really have. I couldn’t sing along with my favorite songs because my voice breaks at the higher register. I wheezed out words. I croaked my way through conversations. “Are you sick?” my daughter asked, “You don’t sound like you.”
Her passing comment stuck with me. You don’t sound like you. Suddenly, I missed the sound of my voice. I disliked this alien version of it. I craved that problematic voice that I’ve tried to change over the years. I wanted my voice to return.
After twenty years, I decided to acknowledge the sound of me, even if others don’t. I want to be heard, and I’m done trying to make anyone listen.
—
Featured image: “Speak” by Flickr user Ash Zing, CC BY-NC-ND 2.0
—
Kelly Baker is a freelance writer with a religious studies PhD who covers religion, higher education, gender, labor, motherhood, and popular culture. She’s also an essayist, historian, and reporter. You can find her writing at the Chronicle for Higher Education‘s Vitae project, Women in Higher Education, Killing the Buddha, and Sacred Matters. She’s also written for The Atlantic, Bearings, The Rumpus, The Manifest-Station, Religion Dispatches, Christian Century’s Then & Now, Washington Post, and Brain, Child. She’s on Twitter at @kelly_j_baker and at her website.
—
 REWIND!…If you liked this post, you may also dig:
REWIND!…If you liked this post, you may also dig:
Vocal Gender and the Gendered Soundscape: At the Intersection of Gender Studies and Sound Studies — Christine Ehrick
On Sound and Pleasure: Meditations on the Human Voice– Yvon Bonefant
As Loud As I Want To Be: Gender, Loudness, and Respectability Politics — Liana Silva
Share this:

Trap Irony: Where Aesthetics Become Politics

This beat ‘bout to get murdered
Thought this was Future when I heard it
Desiigner sounds kinda like Future. Probably you’ve noticed? Everyone else has. While some reactions are a register of genuine surprise that “Panda” isn’t a Future song (cf Uncle Murda epigraph), many are a combination of reflexive skepticism about Desiigner’s authenticity (He’s never even been to Atlanta!!)–or even the authenticity of New York as a hip hop city–alongside a sort of schadenfreude over his ability to notch a higher rated song than Future has ever managed (“Panda” hit #1 for two weeks in May 2016). This latter observation is certainly true: Southern trap god Future has cracked the Billboard Hot 100 top 10 just once, as a featured artist on Lil Wayne’s “Love Me,” and his other appearances in the top 30 are similarly collaboration. (My discussion of trap focuses here on the hip hop wing of trap. The related but not identical EDM genre also called “trap” lies outside the scope of this particular analysis.) But pointing to the chart “failure” of Future’s singles is also entirely disingenuous, as all four of his official album releases have landed in the Billboard 200 top 10, including a #1 for 2015’s DS2 and 2016’s EVOL. In other words, Future isn’t exactly struggling to be relevant, which is why the nearly reflexive journalistic pairing of “Desiigner sounds like Future” and “Desiigner’s song is more successful than any Future song” gets my critical side-eye popping. The reception of Desiigner as a fake-but-more-successful Future strikes me as a dig at trap music as an easily replicable and therefore unserious genre. Here, I’m listening closely to the ways Desiigner’s vocals sound like Future as an entry point to trap’s political work: a sonic aesthetics of dis-organized polity, of sonic blackness in a post-racial society that I call trap irony.
Sounds Like Future
Though I’ve found several instances of writers comparing Desiigner to Future, that comparison usually includes little detailed support about the Future-istic elements of Desiigner’s sound. There are a number of sonic cues in “Panda” that could lead listeners to mistake the singer for Future, but I’m going to focus on the most obvious similarity: Desiigner’s recorded vocals share timbral and affective similarities to some of Future’s recorded vocals. When critics say Desiigner sounds like Future, the vocals are likely their main point of reference, so I’ve identified five points of sonic similarity between Desiigner and Future.
- Desiigner’s voice on “Panda” is detuned, resonating slightly off pitch with the instrumental, a technique so common in Future songs that I could link to any number of examples. Here are four, all released in the last two years, as a representative sample: “Stick Talk,” “Where Ya At (feat. Drake),” “March Madness,” and “Codeine Crazy.”
- Second, Desiigner delivers his vocals with a flat affect, conveying little emotion through inflection. Listen to the sections in the video above where he repeats the word “panda” [0:33-39, 1:38-46, 2:44-52, 3:51-58]. These repetitions precede each verse and then punctuate the end of the song. Rhythmically they signal what should be a turn-up— a run of at least a measure’s worth of eighth notes just before the full beat drops. But Desiigner’s recitation is emotionless, each instance of the word sounding just like the last. Throughout the rest of the song, if a listener didn’t understand the words, it would be hard to guess what Desiigner is rapping about based on any emotive signals. Love? Aggression? Loss? The vocal performance is reportorial, dispassionate. Future adopts a similar technique in up-tempo songs. His repetition of the words “jumpman” (1:08-10) and “noble” (1:28-30) in “Jumpman” and the word “wicked” (0:13-24) in “Wicked” provide parallels to Desiigner’s recitation of “panda.” And in “Ain’t No Time,” Future delivers lines about his clothes and money as casually as he predicts his enemies ending up outlined in chalk (0:13-26); just as in “Panda,” a listener who didn’t catch the lyrics to “Ain’t No Time” wouldn’t be able to attach any particular emotional content to the song.
- Speaking of not catching lyrics, Desiigner and Future are both notoriously mushmouths: enunciation is optional. A number of online videos and fluff posts revolve around the fact that it’s hard to make out what Desiigner or Future is saying.
- Both Desiigner’s and Future’s performed voices seem to sit low in their registers, produced by opening the backs of their throats and elongating their vocal chords. For context, both artists seem to speak in the same register their recorded vocals fall in, and each is also likely to perform their vocals a little higher in a live setting.
- The bulk of “Panda”’s verses are in “Migos flow.” Named for the ATL trap trio who popularized it in their song, “Versace,” Migos flow is a triplet figure that rises from low to high, 3-1-2 (where 1 is the downbeat). The first twenty seconds of the “Versace” link above is a constant string of Migos flow. It’s pervasive throughout “Panda,” but 0:49-52 stacks two Migos flow lines back-to-back. Future’s verse on Drake’s “Digital Dash” (0:18-2:00) is a good example of an extended Migos flow.
In other words, Desiigner does sound like Future in some significant ways. But that’s not all he sounds like. Detuned vocals isn’t just a Future thing. Adam Krims theorizes this as part of the “hip hop sublime,” and it’s especially common among Southern rappers (for example, Young Jeezy sounded like Future before Future even did) (73-74). Many trap artists rap in a way that confounds efforts to understand what they’re saying; Young Thug, for instance, employs a vocal style distinct from Future and Desiigner but is equally difficult to understand. And the Migos flow, as partially demonstrated in this video, is not Future’s (or Migos’s) proprietary style. It’s been adopted by several (especially Southern) rappers, most recently in conjunction with trap. The elements I describe in the previous paragraph point to some specific ways Desiigner sounds like Future, which in turn points to ways that Desiigner sounds, more broadly, like trap.
The “Panda” beat, which comes from UK producer Menace, bears this out. Southern trap, as can be heard by surveying the songs linked above, features instrumentals with deep, tuned kick drums, usually dry 808 snares, high and bright synth lines, and punctuation from low brass and strings (0:40-1:33 in “Panda,” for the latter). This low/high frequency spread, with the mid-range mostly open, characterizes a good deal of trap music; the freed mid-range leaves more room for the bass to be amplified to soul-rattling levels without crowding out the rest of the instrumental. Also, one of the most iconic sonic elements of trap is the rattling hihat, cruising through subdivisions of the beat at inhuman rates (for instance, Metro Boomin’s hats at 0:16 in the aforementioned “Digital Dash” rattle but good when the full beat drops). Here’s the thing about “Panda,” though: those hats don’t rattle. Instead, they enter oh-so-quietly at 1:06 and bang out a steady eighth note pattern punctuated with a crash cymbal on every fourth beat until the end of the verse.

Sounds Like Trap
The missing hihats are an important piece of “Panda”’s sonic puzzle, and point to some broader observations about trap aesthetics as politics, what I’m calling trap irony. Trap music moves through society in ways it shouldn’t. The image of the trap is a house with only one way in and out, yet trap aesthetics produce a music that seems to constantly find a secret exit, a path not offered, a way around established norms. Materially, the bulk of trap music circulates through and out of Atlanta on mixtapes, beyond the purview of major record labels and, in part because it isn’t controlled by labels, at an astonishing rate—for instance, from January 2015-February 2016, Future released four mixtapes and two official albums. Moreover, trap reverberates as sonic blackness in a society whose mainstream has been explicitly peddling a post-racial ideology for nearly a decade. Trap aesthetics become trap politics.

“I made you a mixtape” by Flickr user badjonni, CC BY-SA 2.0
Sonic blackness, as Nina Sun Eidsheim defines it and as Regina Bradley has expanded it, is the interplay of vocal timbre and current norms about what constitutes blackness; it’s a moving target that nonetheless shapes and is shaped by a society’s notions of race and racialization (Eidsheim, 663-64). In the case of trap, I argue that its sonic blackness is apparent in the context of post-racial ideology. Post-race politics depends on the notion that racism has ended and that race doesn’t matter anymore. In this framework, as Jared Sexton argues in Amalgamation Schemes, multiracialism, the blending of many races together until distinct racial backgrounds are purportedly indecipherable, becomes the ideal. The problem Sexton finds with multiracialism as a discourse is that it doesn’t account for the historical racial hierarchies that institutionalize whiteness as ideal; rather, multiracialism “is a tendency to neutralize the political antagonism set loose by the critical affirmation of blackness” (65).
Trap irony describes the way trap picks up recognizable markers of hip hop blackness (urban spaces, violence, drugs, sexual voracity, conspicuous consumption) so that its existence becomes an affirmation of blackness in a post-racial milieu. In fact, ironies abound in trap. Kemi Adeyemi has written about the use of lean, the codeine-based concoction of choice for many Dirty Southern rappers, as “generat[ing] productively intoxicated states that counter the violent realities of a particularly black everyday life” (first emphasis mine). LH Stallings has argued for the hip hop strip club — trap’s home away from home — to be understood as an always already queer space despite its surface heteronormativity. I’ve elsewhere used Stallings’s “black ratchet imagination” to think about party politics in the south, the way a group like Rae Sremmurd use party music as a refusal to produce and re-produce for the benefit of whiteness. The flat affect of rappers like Desiigner and Future is a similar shirking of emotional labor; where an artist like Kendrick Lamar brings fire and brimstone, Future shows up with dispassionate Autotune warble. Intoxicated but productive, heteronormative but queer, partying but political, affected but flat: in each case, we can hear trap irony navigating the complex assemblages of blackness in a purportedly post-racial society.
The last piece of the “Panda” puzzle is another trap irony, the sonification of a dis-organized polity, a bloc that doesn’t voice its interests as one. Listening to “Panda,” it’s hard to notice that the rattling hihat, integral to so much ATL trap, is missing. That’s because Desiigner vocalizes it himself. Throughout the track, he adds a handful of background vocals that trigger at seemingly random points. Unlike the flat affect of his flow, Desiigner’s vocal ad-libs are full of energy, as if he’s egging himself on. One of these vocals is “brrrrrrrrrrrrrrrah,” a tongue roll of varying lengths that replaces the missing hihat rattle. Listen back to the other trap songs I’ve linked in this essay, or check out nearly any track from trap artists like Young Thug, Rae Sremmurd, or Kevin Gates, and you’ll hear the pervasiveness of the hyped trap background vocals.

Screenshot of Desiigner’s performance at the 2016 BET Awards, June 26, 2016
Trap background vocals, like the aesthetics, politics, and economy of trap itself, is a messy business. Desiigner’s background vocals on “Panda” move in meter and sometimes lock into a sequence, but he triggers enough different ones at unexpected moments that a listener can’t know exactly what sound to expect next nor when it will occur. Desiigner sounds like Future, which is to say he sounds like trap, which is to say he sounds like blackness, and his background vocals, which he turns up loud, are emblematic of the aesthetics and politics of trap. Trap irony means that a genre that renders blackness audible in 2016 does so not through a multiracial neutralization of the critical affirmation of blackness, but by setting loose a disparate set of recognizably black voices sounding from all directions, rattling across the soundscape, routing themselves through any path that doesn’t lead to the designated entry/exit point of the trap.
—
Justin D Burton is Assistant Professor of Music at Rider University, and a regular writer at Sounding Out!. His research revolves around critical race and gender theory in hip hop and pop, and his current book project is called Posthuman Pop. He is co-editor with Ali Colleen Neff of the Journal of Popular Music Studies 27:4, “Sounding Global Southernness,” and with Jason Lee Oakes of the Oxford Handbook of Hip Hop Music Studies (2017). You can catch him at justindburton.com and on Twitter @justindburton. His favorite rapper is Right Said Fred.
—
 REWIND!…If you liked this post, you may also dig:
REWIND!…If you liked this post, you may also dig:
Slow, Loud, and Bangin’: Paul Wall talks “slab god” sonics–Doug Doneson
“The (Magic) Upper Room: Sonic Pleasure Politics in Southern Hip Hop“–Regina Bradley
“Tomahawk Chopped and Screwed: The Indeterminacy of Listening“–Justin Burton
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments