
Gendered Voices and Social Harmony

 Editor’s Note: Our forum on gender and voice comes to a close today—and what a forum it has been! Last week AO Roberts talked about speech synthesis and why the robotic voices are so often female. That post followed Art Blake’s, where he talked about how his experience shifting his voice from feminine to masculine as a transgender man intersects with his work on John Cage. Before that, Regina Bradley put the soundtrack of Scandal in conversation with race and gender. The week before I talked about what it meant to have people call me, a woman of color, “loud.” The post that started it all? Christine Ehrick‘s selections from her forthcoming book, on the gendered soundscape.
Editor’s Note: Our forum on gender and voice comes to a close today—and what a forum it has been! Last week AO Roberts talked about speech synthesis and why the robotic voices are so often female. That post followed Art Blake’s, where he talked about how his experience shifting his voice from feminine to masculine as a transgender man intersects with his work on John Cage. Before that, Regina Bradley put the soundtrack of Scandal in conversation with race and gender. The week before I talked about what it meant to have people call me, a woman of color, “loud.” The post that started it all? Christine Ehrick‘s selections from her forthcoming book, on the gendered soundscape.
This week Robin James returns to SO! to round out our forum with an analysis of how ideas of what women should sound like have roots in Greek philosophy. So, lean in, close your eyes, and let the voices take you back in time. –Liana M. Silva, Managing Editor
—
Dove and Twitter’s #SpeakBeautiful tries to market its brand by getting Twitter users to rally behind the hashtag. The idea is to encourage women to talk about their bodies and other women’s bodies only in positive terms–and to encourage interaction on Twitter. But why is tweeting, which is entirely text-based, called “speaking”? And what does it mean to speak beautifully, since beauty is usually an issue of body image? In other words, why give this campaign that specific name?
Their promotional video has a clue. As on Twitter, there is no voice, only text; however, there is an instrumental soundtrack throughout. It begins in a minor mode, traditionally associated with negative emotions. Then, around the 0:19 mark, once the blue Dove domino has started knocking down all the white dominoes with negative comments printed on them, the soundtrack shifts to major mode, which is traditionally associated with positive emotions. The video equates social media performance with musical harmony: negative comments are dissonant, positive ones are consonant.
“Speaking beautifully” means adopting the tone or attunement expected of the social media performance. But this still doesn’t tell us why it makes sense for Dove to describe women’s ability to follow social (media) norms as speaking, as making a particular kind of sound. #SpeakBeautiful is just the latest example of a convention that dates back thousands of years: patriarchy moderates women’s literal and metaphoric voices to control their participation in and affect on society, ensuring that these voices don’t disrupt a so-called harmoniously-ordered society. In what follows, I look to the origin of that convention in so we can better understand how it works today.
***
Anne Carson’s essay “The Gender of Sound” focuses mainly on ancient Greek literature and philosophy. “In general,” she argues, “the women of classical literature are a species given to disorderly and uncontrolled outflow of sound” (126). Unless carefully managed by husbands and the law, women’s loose lips (in both senses of the term) will upset overall “harmonious” order of the city. That’s why the ancient Greeks thought women’s disharmonious sounds acted “as political disease” (127).

“Eglise de Commana2012 469” by Lamiot – Own work. Licensed under CC BY-SA 3.0 via Wikimedia Commons
Emphasizing the relationship the Greeks drew between sonic harmony and social harmony, Carson’s analysis hinges on the concept of sophrosyne; often translated as “moderation,” the ancient Greeks understood sophrosyne as a type of harmony, and often explicitly connected it to musical harmony. Understanding the connection between sophrosyne and ancient Greek theories of musical harmony (which are very different than contemporary European ones) makes it easy to update Carson’s analysis to account for contemporary appraisals of women’s voices, such as the view that some feminist voices on social media are “toxic.”
According to Carson, the ancient Greeks thought women’s voices were immoderate when they exhibited excessive frequency: they could talk either at too high a pitch, or just talk too much. As Carson explains,
verbal continence is an essential feature of the masculine virtue of sophrosyne…[A]ncient discussions of the virtue of sophrosyne demonstrate clearly that, where it is applied to women, this word has a different definition than for men. Female sophrosyne is coextensive with female obedience to male direction and rarely means more than chastity. When it does mean more, the allusion is often to sound. A husband exhorting his wife or concubine to sophrosyne is likely to mean ‘Be quiet!’ (126).
So, (certain kinds of) men were thought to be capable of embodying (masculine) sophrosyne, that is, of comporting their bodies in accord with the order of the city, so that when they did speak, their speech contributed to social harmony and orderliness. The practice of sophrosyne aligns one’s body with the logos of a properly-ordered society, and, indeed, a properly-ordered cosmos. As Judith Periano puts it, moderation “tunes the soul to the cosmic scale (rather than the physical body)” (33). Women (and slaves, and some other kinds of men) were thought to be incapable of embodying this logos, of transforming their bodies into microcosms of the well-ordered city and harmonious cosmos. Their speech would disrupt social and cosmic harmony with dissonant, disorganized material. Silence, then, is how women contributed to social and cosmic harmony: their verbal and sexual chastity preserved the optimal, most well-balanced political and metaphysical order.

“Sanzio 01 Plato Aristotle” by Raphael – Web Gallery of Art: Image Info about artwork. Licensed under Public Domain via Wikimedia Commons
Women couldn’t embody the logos because they had “the wrong kind of flesh and the wrong alignment of pores for the production of low vocal pitches, no matter how hard they exercised” (Carson 120). Women’s disproportional “alignment of pores” matters, and Ancient Greek music theory is key to understanding why. Though there was widespread disagreement as to the specific ratios that were the most consonant and harmonious, there was a general consensus among music theorists and philosophers that musical harmony was a matter of geometric proportion. For example, Plato says in Timaeus 32c that the cosmos “was harmonized by proportion.” Proportion, for the ancient Greeks is both a ratio and a hierarchical ordering, a relational distribution that is also a series. Plato’s myth of the metals, for example, is both proportional (the “gold” get the most responsibility) and hierarchical (the gold are on the top). There is a right place for everything, and harmony is the effect of everything being in its right, appropriately proportionate place.
Harmonious sounds are side-effects of harmoniously proportioned material bodies–or rather, sonic harmony occurs when the relationship between an instrument’s internal structure and external emission (e.g., between body and speech) is itself proportionate. For example, on a pipe organ, a pipe’s size is directly and consistently proportional to the pitch it emits, such that the geometric relationships among pipes are directly and consistently proportional to the relationships among pitches. Woodwinds, on the other hand, exhibit no such direct, consistent relationship between material configuration and emitted pitch. On an oboe, the geometric relationship between the instrument as it plays a middle C and a high C does not mirror to the acoustic relationship between those pitches. As Plato puts it “in the case of flute-playing, the harmonies are found not by measurement but by the hit and miss of training, and quite generally music tries to find the measure by observing vibrating strings. So there is a lot of imprecision mixed up in it and very little reliability” (Philebus 56a). Here, he expresses the then-typical view that musical harmony ought to be a mathematically consistent effect of geometric relationships among the instrument’s parts (e.g., vibrating strings). The problem with the flute is that the relationships among its pitches is merely sonic, and cannot be inferred from the geometric relationships among its parts. Its sounds do not exhibit a consistent, proportional, moderate relationship to its material structure.
This is the same problem Carson identifies with women: the orderliness of their vocal emissions cannot be reliably inferred from the visible arrangement of their body and its constitutent parts. Like the flute, a feminine body cannot emit a moderate sound because the proportions of women’s bodies are out of whack; they don’t exhibit the proper ratio between parts, or between inner constitution and outer expression.

“Banquet Euaion Louvre G467 n2” by English: Euaion Painter – Jastrow (2008). Licensed under Public Domain via Wikimedia Commons
Women’s voices are “bad to hear or make men uncomfortable” (Carson, 129) not just because the voices themselves are disharmoniously feminine, but because they upset the social and cosmic order, specifically, the balance between inside and outside (129), intelligible and visible. Just as the aulos (an ancient Greek double-reeded instrument, somewhat like a modern oboe) upsets the proper, ideal relationship between an instrument’s physical structure (the part that commands, the mathematical logos of proportionality) and acoustic tuning (the part that obeys, pitches), women’s emissions mess up the proper, logical relationship between “the part that commands and the part that obeys” (Foucault, The History of Sexuality Vol. 2, 87), that is, between inner and outer, soul and body, private and public. Carson says, “By projections and leakages of all kinds–somatic, vocal, emotional, sexual–females expose or expend what should be kept in” (129). Sophrosyne is what keeps things in their right place as they get outwardly expressed.
When men practice “masculine” sophrosyne, they shape their bodies, their resonating innards, so to speak, into a form that will lend itself to rational, proportional outer expression, i.e., speech. Women’s feminine sophrosyne, public silence, keeps their irrational bodies from outwardly expressing disharmonious, disproportionate phenomena that would knock everything out of balance. Masculine sophrosyne is a technique for embodying the logos at the individual, social, and cosmic levels; feminine sophrosyne is a technique for keeping the cosmic/social logos from being disturbed.
Nowadays, though, we don’t expect “good” women to be seen and not heard–we praise (some) women for making the right noises in the right contexts. For example, Rebecca Solnit wrote that 2014 was, for women, “a year of mounting refusal to be silent…It was loud, discordant, and maybe transformative, because important things were said…and heard as never before.” Proclamations of women’s envoicement–of women’s full inclusion and participation in society–are central to post-feminist patriarchy, which functions best when there is a little bit of “feminist” noise mixed in with its signal. The audibility of some women’s “feminist” voices serves as (misleading) evidence that patriarchy is over (or on the way there), and lets patriarchy and the intersectional work it does pass unnoticed. Whereas the ancient Greeks thought women’s voices were absent from a harmonious society, contemporary (neo)liberal democracies think a harmonious society includes a certain amount of feminist noise.

“Christine de Pisan – cathedra” by From compendium of Christine de Pizan’s works, 1413. Produced in her scriptorium in Paris – http://bcm.bc.edu/issues/winter_2010/endnotes/an-educated-lady.html. Licensed under Public Domain via Wikimedia Commons
But not too much feminist noise: feminist noise must be moderate. Moderation still matters–it’s just measured differently than it was in ancient Greece. It isn’t a matter of geometric proportion, but of dynamic range. From a post-feminist perspective, feminist voices that call attention to ongoing patriarchy and misogyny feel too loud. Sara Ahmed explains, “words like “racism” and “sexism” are heard as abrasive because they name what has receded from view.” Voices that speak of ongoing racism and sexism are charged with the same flaws attributed to artificially loudened, overcompressed music: inflexibility, lack of variability, and ineffectiveness. Just as overcompressed music is thought to, as Suhas Sreedhar describes “sacrifice…the natural ebb and flow of music,” feminist activists are thought to to sacrifice the natural ebb and flow of social harmony.
In a post-feminist, post-race society, people who continually insist on the existence of sexism and racism appear to be similarly stuck on an irrelevant issue and lacking in expressive range. Similarly, in music lacking dynamic range, “the sound becomes analogous to someone constantly shouting everything he or she says. Not only is all impact lost, but the constant level of the sound is fatiguing to the ear (Sreedhar).” Because it stays more or less fixed at the same amplitude of sound, loud music is thought to be both ineffective and unhealthy for those subjected to it. Similarly, liberal critics of women of color activists often characterize them as hostile, uncivil, or overly aggressive in tone, which supposedly diminishes the impact of their work and both upsets the healthy process of social change and fatigues the public. They are, in Michelle Goldberg’s terms, “toxic.”
This “ebb and flow” is not a geometric proportion, but a frequency or statistical distribution that can be represented as a sine wave. As I have argued here, contemporary concepts of social harmony aren’t based in ancient Greek music theory, but on acoustics. For example, Alex Pentland’s theory of “social physics” or, “the reliable, mathematical connections between information and idea flow…and people’s behavior” (2), treats individual and group behavior as predictable patterns that emerge, as signal, from noisy data streams, just as harmonics and partials emerge from interacting sound frequencies.
 In this context, “loud” feminist voices feel like they’re upsetting the ebb and flow, the dynamic range and variability, of information and idea flow. But the thing is, they aren’t upsetting the flow, but intensifying it: their perceived loudness incites others to respond with trolling, harassing, and other kinds of policing speech, often in massive scale. When philosopher Cheryl Abbate told her students that it was unacceptable to express homophobic views in class, John McAdams, a tenured faculty member in the department where Abbate is a doctoral student, wrote a blog post accusing her of inhibiting the free expression of a diverse range of opinions. Her “loud” feminism masked the “healthy diversity” of opinions. McAdams’s post led Abbate to be targeted by a tsunami of harassment, from individuals emailing her, to social media attacks, to attacks from mainstream media and political organizations. When feminist voices make noise, patriarchy amps up its own frequencies to bring the mix back in proper balance so that patriarchy is what emerges from feminist noise. In this context, voices are harmonious when, together, their ebb and flow predictably transmits patriarchal signal into the future. Sophrosyne is a feature of voices that interact so that patriarchal power relations emerge from them: they might actually have an extremely high volume, but they feel moderate because they restore the “normal” ebb and flow of society.
In this context, “loud” feminist voices feel like they’re upsetting the ebb and flow, the dynamic range and variability, of information and idea flow. But the thing is, they aren’t upsetting the flow, but intensifying it: their perceived loudness incites others to respond with trolling, harassing, and other kinds of policing speech, often in massive scale. When philosopher Cheryl Abbate told her students that it was unacceptable to express homophobic views in class, John McAdams, a tenured faculty member in the department where Abbate is a doctoral student, wrote a blog post accusing her of inhibiting the free expression of a diverse range of opinions. Her “loud” feminism masked the “healthy diversity” of opinions. McAdams’s post led Abbate to be targeted by a tsunami of harassment, from individuals emailing her, to social media attacks, to attacks from mainstream media and political organizations. When feminist voices make noise, patriarchy amps up its own frequencies to bring the mix back in proper balance so that patriarchy is what emerges from feminist noise. In this context, voices are harmonious when, together, their ebb and flow predictably transmits patriarchal signal into the future. Sophrosyne is a feature of voices that interact so that patriarchal power relations emerge from them: they might actually have an extremely high volume, but they feel moderate because they restore the “normal” ebb and flow of society.
When Dove and Twitter urge women to “speak beautifully,” they’re really demanding that women practice sophrosyne: that they make just enough ‘feminist’ noise without being too loud–i.e., loud enough to distort the brand image of Unilever and Twitter. So, even though ancient Greek concepts of musical harmony and patriarchy are vastly different than contemporary (neo)liberal democratic ones, each era uses its own version of sophrosyne to shape women’s voices into something consonant with a social order that privileges men and masculinity.
—
Featured image: “” by Flickr user Ed Lynch-Bell, CC BY-NC 2.0
—
Robin James is Associate Professor of Philosophy at UNC Charlotte. She is author of two books: Resilience & Melancholy: pop music, feminism, and neoliberalism, published by Zer0 books last year, and The Conjectural Body: gender, race and the philosophy of music was published by Lexington Books in 2010. Her work on feminism, race, contemporary continental philosophy, pop music, and sound studies has appeared in The New Inquiry, Hypatia, differences, Contemporary Aesthetics, and the Journal of Popular Music Studies. She is also a digital sound artist and musician. She blogs at its-her-factory.com and is a regular contributor to Cyborgology.
—
 REWIND!…If you liked this post, check out:
REWIND!…If you liked this post, check out:
Top 40 Democracy: Taylor Swift’s Election Day Victory—Eric Weisbard
Vocal Gender and the Gendered Soundscape: At the Intersection of Gender Studies and Sound Studies—Christine Ehrick
On Sound and Pleasure: Meditations on the Human Voice– Yvon Bonefant
Share this:

Vocal Gender and the Gendered Soundscape: At the Intersection of Gender Studies and Sound Studies

Editor’s Note: Welcome to Sounding Out!‘s annual February forum! This month, we’re wondering: what ideas regarding gender and sound do voices call forth? To think through this question, we’ve recruited several great writers who will be covering different aspects of gender and sound. Regular writer Regina Bradley will look at how music is gendered in Shonda Rhimes’ hit show Scandal. A.O. Roberts will discuss synthesized voices and gender. Art Blake will share with us his reflections on how his experience shifting his voice from feminine to masculine as a transgender man intersects with his work on John Cage. Robin James will return to SO! with an analysis of how ideas of what women should sound like have roots in Greek philosophy. Me? I’ll share a personal essay/analysis of what it means to be called a “loud woman.”
Today we start our February forum on gender and sound with Christine Ehrick‘s selections from her forthcoming book Radio and the Gendered Soundscape in Latin America. Below, she introduces us to the idea of the gendered soundscape, which she uses in her analysis on women’s radio speech from the 1930s to the 1950s. She will make you think twice about the voices you hear on the radio, in podcasts, over the phone…
In the meantime, lean in, close your eyes, and let the voices whisk you away.–Liana M. Silva, Managing Editor
—
Several years ago, while aboard a commercial airline awaiting take off, I heard the expected sound of a voice emerging from the cockpit, transmitted via the plane’s P.A. system. The voice gave passengers the usual greeting and general information about weather conditions, flight time, etc. What was unusual, and caught the otherwise distracted passengers’ attention, was the fact that the voice speaking was female. People looked up from their magazines and devices not because of the “message” but because of the “medium”: a voice that deviated from the standard soundscape of commercial aviation, a field comprised mostly of men.
For this historian, interested in vocal gender and the female voice in particular, the incident was a fascinating demonstration of both the voice as performance of the gendered body, and the fact that the human voice can and often does communicate beyond (and sometimes despite) the words being spoken. In this essay I want to briefly discuss some of the ideas I explore more fully in my forthcoming book, a study of women/gender and golden age radio titled Radio and the Gendered Soundscape in Latin America: Women and Broadcasting in Argentina and Uruguay, 1930-1950 (forthcoming, Cambridge 2015). In this book, I use the stories of five women and one radio station to explore the possibilities and limits for women’s radio speech, and to pose some larger questions about vocal gender and the gendered soundscape. For this post, I present the conceptual framework that I use to understand how gender is constructed through the voice.

“DSC00814” by Flickr user jordan weaver, CC BY-NC-ND 2.0
Gender and sound have both been explored as categories of historical analysis, but largely in isolation from one another. The historiographical impact of gender analysis is almost too obvious to mention; suffice to say that attention to gender has altered the very questions historians ask of the past and the way we understand structures of power and historical change. More recently, historians have begun to incorporate R. Murray Schafer’s concept of the soundscape and what Jonathan Sterne has called “sonic thinking” into their analysis of the past (The Sound Studies Reader, 3). But not enough consideration has been given within the field of history to the ways sound may be gendered and gender sounded.
I bring these three threads together – gender, sound, and history – via the concept of the gendered soundscape. Helmi Järviluoma, Pirkko Moisala and Anni Vilkko introduce the term in their book Gender and Qualitative Methods (2004), which asks readers to contemplate the way gender – and gendered hierarchies – may be projected and/or heard in sound environments. We not only “learn gender through the total sensorium,” as they put it; gender is also represented, contested and reinforced through the aural (85). Thinking historically about gendered soundscapes can help us conceptualize sound as a space where categories of “male” and “female” are constituted within the context of particular events over time, and by extension the ways that power, inequality and agency might be expressed in the sonic realm—in other words, tuning in to sound as a signifier of power. Although many of us have been well-trained to look for gender, I consider what it means to listen for it.

“Untitled” by Flickr user Observe The Banana, CC BY-NC 2.0
The soundscape, of course, is not only gendered; other aspects of social hierarchy, such as race, class and sexuality, are also performed and perceived in the aural realm. Greg Goodale’s analysis in Sonic Persuasion: Reading Sound in the Recorded Age (2011) of “the race of sound,” which argues that sound constructs rather than simply reiterating race, provides a useful framework for understanding both what we might call the gender of sound and the ways gender and race might intersect in the soundscape (76-105). As we learn to become more “ear-oriented” scholars, in other words, we come to perceive power, oppression, and agency in entirely new ways.
One of the most immediately gendered sound categories is the human voice, a richly historical convergence of human biology, technology and culture. We can and do hear gender in most human vocalizations; linguists seem to agree that, when listening to adult (non-elderly) voices speaking above a whisper “gender determination is usually a simple task” (See, for example, David Puts, Steven Gaulin and Katherine Verdolini in “Dominance and the Evolution of Sexual Dimorphism in Human Voice Pitch” and Michael Jessen in “Speaker Classification in Forensic Phonetics and Acoustics”). When we hear a voice without visual referent, as in the airplane example above or when listening to the radio, we immediately tend to classify the voices as “male” or “female.”
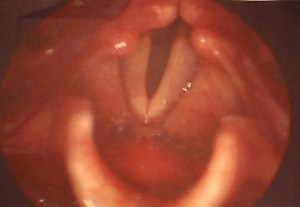
“my vocal cords.” by Flickr user Dan Simpson, CC BY-NC 2.0
Voice differences have roots in biological sex difference. With the onset of puberty, the larynx is enlarged and vocal folds increase in length and in thickness, resulting in a decrease in frequency (Hz) of vocal fold vibration and thus a lowering of voice pitch. But while bodies classified as biologically female experience about a one-half octave average drop in voice pitch with puberty, biological males tend to experience a full octave average drop in pitch, with the result being that adult male voices tend to operate within a lower frequency range than female voices. However, gendered constructions of the human voice vary widely over time and place.
Biology (body size, hormonal secretions, age, and other physiological factors) is no way destiny when it comes to the human voice. Linguists distinguish between “anatomical voice quality features,” which in essence set the parameters of comfortable pitch range given a person’s vocal anatomy (the range outside of which is difficult to easily maintain one’s speaking voice) and “voice quality settings,” which refers to where someone places their voice within that range (See Monique Adriana Johanna Biemans’ thesis, Gender variation in voice quality.) Bound to some degree by these physiological parameters, humans can and do place their voices in ways that are consistent with the performative aspects of gender, and voice pitch is both highly variable and subject to cultural/historical framing and self-fashioning (For more on this subject, see Anne Karpf, The Human Voice: How this Extraordinary Instrument Reveals Essential Clues About Who We Are, 2006). Thus like other aspects of gender, voice is culturally and historically constructed and performative.
Conceptualizing the voice as a sonic expression of the gendered body requires revisiting both the tendency of feminist scholars to equate “women’s voice” with writing or discourse, and the tendency of some media scholars to refer to voices without immediate visual referent (in film, radio) as “disembodied.” In their Introduction to Embodied Voices: Representing Female Vocality in Western Culture (1997), Leslie C. Dunn and Nancy A. Jones concisely articulate the challenge for scholars interested in the sonic/acoustic dimensions of women’s voices:
Feminists have used the word “voice” to refer to a wide range of aspirations: cultural agency, political enfranchisement, sexual autonomy, and expressive freedom, all of which have been historically denied to women. In this context, “voice” has become a metaphor for textual authority…This metaphor has become so pervasive, so intrinsic to feminist discourse that it makes us too easily forget (or repress) the concrete physical dimensions of the female voice upon which this metaphor was based. (1)
Thinking about voice in terms of vocal gender brings us to the complex relationship between voice and body. The concept of disembodiment conveys the sometimes uncanny effect of hearing (especially female) voices without an immediately discernible source. It also underscores the destabilizing effect of these unseen female voices liberated thus from patriarchy’s specular regime. Yet to refer to voices from an unseen source as “disembodied” is to suggest that the voice is somehow separate from the body, a problematic formulation.

“Untitled” by Flickr user Luci Correia, CC BY 2.0
Simply: if the voice is not the body, what is it? Even when it travels over long distances (via telephone or radio, for example) and/or if its source remains out of sight, the body is there, present via the sound vibrations it produces. Stepping away from concepts like disembodiment frees us to explore the nuances of the relationship between the voice and the body, and the presence of gendered bodies in the soundscape, particularly with regard to the vertiginous relationships between bodies and voices that are gendered female.
Gender and history impact how we read the tone, velocity and pitch of the voice, but they also shape parameters of where and when particular voices are invited to speak or expected to remain silent. And here of course we encounter the ways gender hierarchy is expressed and constructed in the acoustic/vocal arena, as well as racial categorization. Kathleen Hall Jamieson puts it succinctly in Eloquence in an Electronic Age: The Transformation of Political Speechmaking (1990): “History has many themes. One of them is that women should be quiet” (67). While by no means absent, women’s voices have remained largely outside of the realm of what Schafer calls “signal”: sounds listened to consciously and that often convey messages and/of authority. Just as other aspects of gender inequality become naturalized, patriarchy tunes our ears to listen to certain voices differently. In these formulations, women’s voices are thus subject to categorization as “noise” or “unwanted sound” (see Mike Goldsmith, Discord: The Story of Noise) and therefore dissonant, disruptive, and potentially dangerous.
The discomfort (or dissonance) with women’s voices, especially women’s voices speaking publicly and/or with authority, carried over into and shaped the history of radio, making early and golden age broadcasting an ideal venue for an historical exploration of gender and voice. What did it mean to hear women’s voices on the radio? How did radio rework the gendered dimensions of public and private space, and by extension the place of the female voice in the public sphere?
The emergence of radio in the early twentieth century was part of a larger revolution in human communication which Walter Ong termed in Orality and Literacy: The Technologizing the Word (1983) a “secondary orality,” an historical moment which reawakened older oral traditions and communal listening in a very different historical and technological context (3). It also reawakened a focus on the human voice, with all of its implications for the gendered soundscape.

“Jane Hoffman, Tobey Weinberg, Ruth Goodman, and Amelia Romano read for a radio broadcast about the Triangle Fire” by Flickr user Kheel Center, CC BY 2.0
In many parts of the world, the rise of radio also coincided with an upsurge in feminist politics and discourses calling for women’s full citizenship and other related matters. As Kate Lacey notes in Feminine Frequencies: Gender, German Radio and the Public Sphere 1923-1945 (1997), “the arrival of radio heralded the modern era of mass communication, while women’s enfranchisement confirmed the onset of mass politics in the twentieth century.” Researching the history of women and radio – and particularly the sometimes hostile reactions to women’s radio voices – led me to appreciate the ways gender is performed and perceived via the voice, and from there into larger questions about the way social hierarchies – of gender, but also of race/ethnicity, class and sexuality – are reproduced and challenged within the sonic realm.
In this way we can better begin to contemplate the historical significance of women’s radio speech in understanding the sonic construction of gender. Depending on content and context, these voices carried the potential to not only challenge taboos on women’s oratory, but to assert the female body into spaces from which it had previously been excluded—like the cockpits (can’t help but note the name here) of commercial airliners.
–
Featured image: “ateliers claus – 140522 – monophonic – Radio Femmes Fatales” by Flickr user fabonthemoon, CC BY-NC-SA 2.0
–
Christine Ehrick is an Associate Professor in the Department of History at the University of Louisville. Her second book, Radio and the Gendered Soundscape in Latin America: Women and Broadcasting in Argentina and Uruguay, 1930-1950 will be published by Cambridge University Press in Fall 2015. This book explores women’s presence and especially their voices – on the airwaves in the two leading South American radio markets of Buenos Aires and Montevideo. Her current work looks at comedy, gender and voice, with a focus on mid-twentieth century Argentine comedians Niní Marshall and Tomás Simari.
Thanks to Cambridge UP for allowing me to use some excerpts from the forthcoming book in this essay.
–
 REWIND! . . .If you liked this post, you may also dig:
REWIND! . . .If you liked this post, you may also dig:
Look Who’s Talking, Y’all: Dr. Phil, Vocal Accent and the Politics of Sounding White– Christie Zwahlen
On Sound and Pleasure: Meditations on the Human Voice– Yvon Bonefant
Heard Any Good Games Recently?: Listening to the Sportscape–Kaj Ahlsved
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments