
El Llanto Against I.C.E.: Toward a Latinx Sonic Phenomenology of the Dignified Cry

It is July 4, 2025. The air is hot; the sun is beaming on concrete and asphalt. Sweat is accumulating on my cotton Disrupt band t-shirt. My skin is sticky. Inside a suffocating room, the volume penetrating my ears is the racket of voices producing a steady pulsation of disunified sounds. A brown noise. In a studio room in Boyle Heights, the acoustics create a space-time of rebellious gravity. There’s something gestating. We are in that in-between aural space, the time-lag between speaker, musician, or performance. The MC is letting the crowd know what is next. We all desired to know.
Yaotl—the vocalist of Xicano hip-hop/punk group Aztlán Underground—is the MC. He is speaking to the crowd during that transition to the next set. Doing so, Yaotl used this exact instance to identify the political moment we were all witness to, the historical cause for the event here, and then, surprising everyone, facilitated a collective llanto. He called it “scream therapy.” The dignified cry, as I am calling it, for him, is sticky, piercing, and angry—a sonorous form of dignified rage. We are all here for Xican@ Records and Film annual cultural event, the Farce of July that hosts vendors and musicians. Yaotl readies the crowd, his contagious call for a llanto also fused with the intimate violences of coloniality, what decolonial theorists of modernity, such as semiotician Walter Mignolo, have called its darker side or underside. “I want everyone to scream your fucking rage against all this shit.” He counts to three. One. Two. Three. We scream. We yell. We cry and cry out together. We manifest the sound of el llanto.

Gritos, llantos, sonidos, caos, and roncas are not new in Latinx Sound Studies. Their history, particularly in Latinx cultural studies, is intimate with the genealogy of not only musical or popular cultural forms (think rancheras in Mexico) but ancestral ceremony, rituals, and mythic stories (like La Llorona). From the invasion of Mexico-Tenochtitlan by Cortés in 1519 to the sonic protest of the 2018 Llanto Colectivo against the Otay Mesa Detention Center in San Diego, we can adequately identify the historically loud opposition against racism and coloniality in the United States. I explore the function of el llanto in relationship to a generalized response to the fascist sequences of repression emerging in the United States, showing how llantos orient both the listener and participant toward a discernment of grief and catharsis. This twofold function facilitates an embodied practice of corporeal sound-making and its therapeutic effect, which I ground here as a form of affective suture. Suffering, transmuted into coraje (angry-tinged courage), generates a collective sounding that pulls listeners into the acoustic llanto. In doing so, it transforms the listener into an agent of dignified rage.
Theorizing llantos requires a Latinx sound and listening methodology grounded in sonic phenomenology—drawing from phenomenological and sound studies traditions—that develop an “acoustic perception” sensitive to the “sonic environment.” I contribute to the notes toward a Latinx listening methodology introduced by Wanda Alarcón, Dolores Inés Casillas, Esther Díaz Martín, Sara Veronica Hinojos, and Cloe Gentile Reyes, who affirm faithful listening as, “attuned not only to sound, but to histories, structures, and acts of refusal that resist dehumanization.” Historically, phenomenologists have privileged the visual phenomenal field, the primacy of visuality being the ocular sense to discern or disclose the meaning of consciousness and lived experience. The sonic phenomenologist tunes into the soundscape as the totality of the aural experience.
The sonic phenomenologist of el llanto, or the dignified cry, develops a decolonial listening technique to perceive the aural structure of coloniality, the audition of dispossession mediated by anti-migrant animus, and the desire for emancipation from such sonic hauntings in everyday life. Many who let out a llanto do so in the face of anti-immigrant, anti-Latinx racism. It emerges as a vocal response to coloniality as lived and enforced through everyday regimes of racialized governance, from linguistic profiling and labor precarity to the slow violence of immigration delay and the spectacle of public kidnappings.
The collective llanto in July came at a time when in Los Angeles, California a popular revolt broke out in the early days of June amongst dissenters against I.C.E. raids and the Trump administration’s deployment of the National Guard to the streets. The spectacle, of a Xicano hip-hop/punk ensemble inviting a collective llanto, became much more than the cacophony of discordant screams but the dissensus of an aggrieved community. In their grief, mediated by the capture, detainment, and transport of undocumented migrants to detention centers, the catharsis of a llanto fueled the connection between desire and social movement. The sounds exiting the body, resonating as vibration in a shared room, identified the mutual feelings of others, in the exhalation of a noisy, impulsive breath.
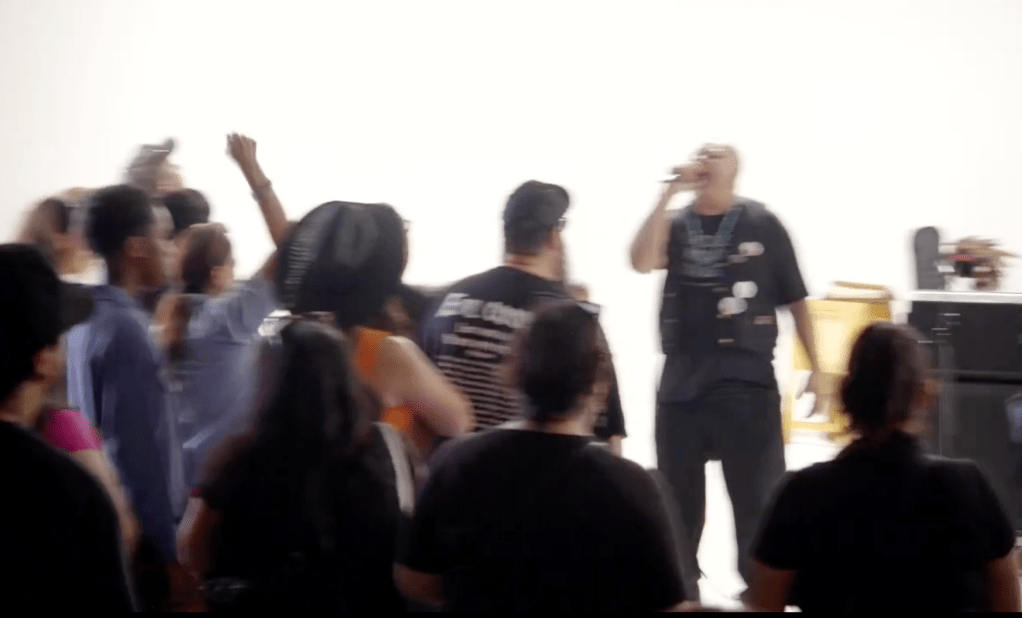
This was not euphoria.
This instance of a rageful cry—loud, infectious, piercing – builds on the “faithful witnessing” articulated by María Lugones and Yomaira Figueroa-Vásquez, disclosing collective anguish fused with a tender fury. The listener must resist the organization of the dignified cry as melodic, rhythmic, or joyful. Rather, the llanto disturbs, ruptures, and erupts as a thunderous dissonance. Its saturation of auditory space interrupts the experience of conviviality or seriality and enchants the temporal form of the ensemble where the participants disappear behind the guttural and raucous sounds.
Faithful listening not only decolonizes racializing sonic structures but amplifies resistance, revolt, and coraje. Llantos are spontaneous, organized, lived. To voice el llanto is to become el llanto; an affective suture where a new auditory imaginary links with the Xicanacimiento of Yaotl’s specificity. Llantos, thus, are particular vocal moments continually shaped and fashioned. For the critical Latinx listener, el llanto offers a few seconds of catharsis and collective grief.
—
Featured Image: Aztlan Underground en Tenochtitlán by Flickr User Joél Martínez CC BY-NC-SA 2.0
—
Kristian E. Vasquez is a Ph.D. candidate in the Department of Chicana and Chicano Studies at the University of California, Santa Barbara. His research on the affects, performances, sounds, and semiosis of La Xicanada expands the concept of Xicanacimiento, centering the aesthetic force of expressive cultural forms in California.
—
.

REWIND!…If you liked this post, you may also dig:
Boom! Boom! Boom!: Banda, Dissident Vibrations, and Sonic Gentrification in Mazatlán—Kristie Valdez-Guillen
Listening to MAGA Politics within US/Mexico’s Lucha Libre –Esther Díaz Martín and Rebeca Rivas
Ronca Realness: Voices that Sound the Sucia Body—Cloe Gentile Reyes
Echoes in Transit: Loudly Waiting at the Paso del Norte Border Region—José Manuel Flores & Dolores Inés Casillas
Share this:

SO! Reads: Alexis McGee’s From Blues To Beyoncé: A Century of Black Women’s Generational Sonic Rhetorics


From Blues To Beyoncé: A Century of Black Women’s Generational Sonic Rhetorics (SUNY Press, 2024) by Alexis McGee explores Black women’s creative labor and cultural production. The book offers a searing critique of both record industry exploitation and sound studies’ white gaze. By focusing on quotidian engagement with sound, McGee speaks simultaneously to linguists, rhetoricians, and ethnomusicologists, demonstrating how each discipline has overlooked Black women’s fundamental contributions to our understanding of language and cultural expression. This is not merely an additive project seeking inclusion within existing frameworks, but rather a fundamental reconceptualization of how we study Black women’s sounds.
McGee, currently Associate Professor at the University of British Columbia’s School of Journalism, Writing, and Media, mobilizes her training in linguistics, rhetoric, and composition to analyze everyday communicative practices and generational knowledge systems passed down between Black women. McGee joins other recent texts such as Earl Brooks’s On Rhetoric and Black Music (2024) in critical conversations around “sonic rhetoric.” In From Blues to Beyoncé, McGee theorizes sonic rhetoric as a collection of cultural technologies for storytelling that “act as methods of communicating knowledge that can be used to persuade or inform (younger) generations about topics like survival, liberation, and care” (6). Examining artists from the 19th, 20th, and 21st centuries through personal experience, archival material, biographies, interviews, and popular media, McGee demonstrates the critical necessity of taking seriously the generational cultural knowledge embedded in Black women’s creative practices within an anti-Black and misogynist world.

At its core, the book introduces “sonic sharecropping” as a term that illuminates the lopsided relationship between Black women creatives (tenants), their sonic and musical creations (crops), and wealthier, more powerful recording industry players (landlords, music labels, copyright holders). The sharecropping metaphor reveals how the music industry extracts value from Black women’s cultural labor while denying them ownership and fair compensation. McGee further develops the concept of “audibility of advice” to name the intergenerational mentorship and fugitive pedagogy that Black women practice as they navigate this exploitative system—showing how even the transmission of survival knowledge between generations becomes entangled in the same structures designed to profit from Black women’s creative work.
The book’s chapters traverse an impressive range of cultural moments. Opening with Cardi B’s attempted trademark of “okurrr,” McGee demonstrates how legal and social structures systematically prevent Black women from securing intellectual property rights over cultural innovations that white industry executives appropriate without restriction.
This contemporary case illuminates sonic sharecropping: Black women are expected to create cultural property that record labels then own and sell back to them. McGee then traces these dynamics historically, analyzing business practices of major labels like Atlantic Records. By drawing parallels between sharecropping contracts and recording agreements, the analysis reveals how the music industry has historically relied on discretionary ethical conduct by executives rather than equitable contractual structures, perpetuating exploitative relationships reminiscent of post-Reconstruction economic arrangements.
In what is perhaps the book’s most compelling chapter, McGee examines successive performances of “Strange Fruit,” tracing how Nina Simone and later artists like Missy Elliott and Janelle Monáe have reinterpreted Billie Holiday’s haunting meditation on lynching.
McGee builds on Amiri Baraka’s concept of the “changing same”, to show that antiblackness persists throughout time though it changes form. McGee demonstrates how Black women performers resist being treated as interchangeable vessels for Black cultural expression. Rather than presenting generic renditions, each artist asserts her distinctive voice and perspective that reiterates the enduring violence perpetuated against Black bodies.
Each performance carries its own rhetorical power while participating in “sankofarration,” a neologism from artist, writer, and media studies professor John Jennings that combines “sankofa” (a West African concept symbolizing learning from the past to move forward) with “narration” to describe a rhetorical worldview premised on understanding time as cyclical rather than linear. Sankofarration positions past and future as interconnected forces that actively shape the present. Crucially, McGee connects Lawrence Beitler’s commercial sale of lynching photographs (depicting the hanged bodies of Thomas Shipp and Abram Smith) to the visual and sonic rhetorical devices in these musical works. Through this framework, Black women artists transform historical trauma into ongoing political commentary and visions for future liberation. Black women’s creative work, she argues, consistently foregrounds documented histories of racial violence alongside the willful ignorance that upholds white supremacy and patriarchy. By listening critically to Black women’s sonic rhetorics, we can access pathways toward collective liberation.

Despite the book’s title, McGee’s engagement with Beyoncé focuses narrowly on the lemon-to-lemonade metaphor in the album, Lemonade. Her analysis of other Black women artists, however, anticipated critiques later directed at Cowboy Carter, highlighting a double standard: as a Black woman, Beyoncé faces moral scrutiny for engaging with country music—positioned as both capitalist enterprise and white cultural property—while white and male artists have participated in the same commercial structures for centuries without comparable ethical condemnation.
This defense raises the book’s most provocative question, one McGee gestures toward but leaves unresolved: if the inequitable standards applied to Black women artists are symptoms of a fundamentally exploitative system, what would liberation from that system actually entail? Does it require dismantling existing structures of cultural ownership and profit, or can it be achieved through expanded access and recognition within them?
While McGee does not directly engage Matthew Morrison’s recent work Blacksound: Making Race and Popular Music in the United States, her analysis clearly converses with his examination of how Black cultural products have been reproduced for white consumption, particularly through the ongoing afterlives of blackface minstrelsy. McGee’s focus on Black women specifically adds crucial gender analysis to ongoing scholarly conversations about racial capitalism and cultural appropriation.
McGee acknowledges that capitalism itself, rather than Black women’s participation in it, constitutes the fundamental problem. However, the analysis stops short of fully theorizing alternatives to existing structures of Western sound production and commodification. Readers familiar with Sylvia Wynter’s insistence on distinguishing the map from the territory, or Audre Lorde’s warning that “the master’s tools will never dismantle the master’s house,” may desire more sustained engagement with radical alternatives and additional tool building necessary for Black liberation from existing antiblack social and political structures. What might Black women’s sonic practices look like in anticapitalist frameworks of collective ownership and exchange? How might Black femme and queer performances expand or complicate these intergenerational transmissions of knowledge? How might Black women’s intergenerational knowledge systems point toward alternative epistemologies that refuse the terms of racial capitalism altogether?

This theoretical restraint appears strategic rather than accidental. From Blues to Beyoncé navigates carefully between colleagues unfamiliar with Black feminist and womanist theory, who require accessible entry points, and specialists seeking new takes on traversing multiple disciplines at once. In threading this needle, McGee prioritizes disciplinary bridge-building before radical dismantling of capitalist structures and academic knowledge production systems.
These limitations notwithstanding, the book represents an essential contribution to multiple fields. It insists that scholars of sound studies, rhetoric, and Black feminist thought must engage one another—that these conversations can no longer proceed in isolation. Methodologically, it offers both theoretical sophistication and practical analytical tools, making it intellectually substantive for non-specialists while providing specialists a compelling model for interdisciplinary synthesis. Most importantly, McGee demonstrates that we cannot understand American culture, sound, or rhetoric without recognizing Black women’s voices as foundational rather than supplementary.
This book transforms its disciplines by interrogating their foundational assumptions, asking us not simply to include Black women in sound studies, but to recognize how their systematic exclusion has rendered the entire field epistemologically incomplete. In raising these questions, even without fully resolving them, McGee provides both rigorous foundation and invitation to continue the work.
—
Featured Image: Janelle Monae on the Dirty Computer Tour at Madison Square Garden in 2018 by Flickr User Raph_PH. License: CC BY 2.0
—
Joe Zavaan Johnson (he/they) is a multi-instrumentalist, arts educator, and Black music researcher. Currently an Ethnomusicology Ph.D. Candidate at Indiana University-Bloomington, he examines the Black banjo renaissance through Black studies, human geography, folklore, and ethnomusicology. Johnson frequently collaborates with grassroots organizations focused on coalition building, community healing, and cultural reparations, bridging scholarship with community-engaged practice. His forthcoming dissertation, Black Banjo Bodylands: Recovering an African American Instrument, explores the relationship between Black people, lands, and banjos as ancestral technology.
—

REWIND!…If you liked this post, check out:
SO! Reads: Marisol Negrón’s Made in NuYoRico: Fania Records, Latin Music, and Salsa’s Nuyorican Meanings –Vanessa Valdés
SO! Reads: Justin Eckstein’s Sound Tactics: Auditory Power in Political Protests––Jonathan Stone
“I’m on my New York s**t”: Jean Grae’s Sonic Claims on the City--Liana Silva
Love and Hip Hop: (Re)Gendering The Debate Over Hip Hop Studies--Travis Gosa
My Music and My Message is Powerful: It Shouldn’t Be Florence Price or “Nothing”-Samantha Ege
I Been On: BaddieBey and Beyoncé’s Sonic Masculinity — Regina Bradley
Cardi B: Bringing the Cold and Sexy to Hip Hop–Ashley Luthers
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments