
Re-orienting Sound Studies’ Aural Fixation: Christine Sun Kim’s “Subjective Loudness”

 Editors’ note: As an interdisciplinary field, sound studies is unique in its scope—under its purview we find the science of acoustics, cultural representation through the auditory, and, to perhaps mis-paraphrase Donna Haraway, emergent ontologies. Not only are we able to see how sound impacts the physical world, but how that impact plays out in bodies and cultural tropes. Most importantly, we are able to imagine new ways of describing, adapting, and revising the aural into aspirant, liberatory ontologies. The essays in this series all aim to push what we know a bit, to question our own knowledges and see where we might be headed. In this series, co-edited by Airek Beauchamp and Jennifer Stoever you will find new takes on sound and embodiment, cultural expression, and what it means to hear. –AB
Editors’ note: As an interdisciplinary field, sound studies is unique in its scope—under its purview we find the science of acoustics, cultural representation through the auditory, and, to perhaps mis-paraphrase Donna Haraway, emergent ontologies. Not only are we able to see how sound impacts the physical world, but how that impact plays out in bodies and cultural tropes. Most importantly, we are able to imagine new ways of describing, adapting, and revising the aural into aspirant, liberatory ontologies. The essays in this series all aim to push what we know a bit, to question our own knowledges and see where we might be headed. In this series, co-edited by Airek Beauchamp and Jennifer Stoever you will find new takes on sound and embodiment, cultural expression, and what it means to hear. –AB
—
A stage full of opera performers stands, silent, looking eager and exhilarated, matching their expressions to the word that appears on the iPad in front of them. As the word “excited” dissolves from the iPad screen, the next emotion, “sad” appears and the performers’ expressions shift from enthusiastic to solemn and downcast to visually represent the word on the screen. The “singers” are performing in Christine Sun Kim’s conceptual sound artistic performance entitled, Face Opera.
The singers do not use audible voices for their dramatic interpretation, as they would in a conventional opera, but rather use their faces to convey meaning and emotion keyed to the text that appears on the iPad in front of them. Challenging the traditional notions of dramatic interpretation, as well as the concepts of who is considered a singer and what it means to sing, this art performance is just one way Kim calls into question the nature of sound and our relationship to it.
Audible sound is, of course, essential to sound studies though sound itself is not audist, as it can be experienced in a multitude of ways. The contemporary multi-modal turn in sound studies enables ways to theorize how more bodies can experience sound, including audible sound, motion, vibration, and visuals. All humans are somewhere on a spectrum between enabled and disabled and between hearing and deaf. As we grow older most people move farther toward the disabled and deaf ends of the spectrum. In order to experience sound for a lifetime, it is imperative to explore multi-modal ways of experiencing sound. For instance, the Deaf community rejects the term disabled, yet realizes it is actually normative constructs of hearing, sound, and music that disable Deaf people. But, as Kim demonstrates, Deaf people engage with sound all of the time. In this case, Deaf individuals are not disabled but rather, what I identify as difabled (differently-abled) in their relationship with sound. While this term is not yet used in disability scholarship, it is not completely unique, as there is a Difabled Twitter page dedicated to, “Ameliorating inclusion in technology, business and society.” Rejection of the word disabled inspires me to adopt difabled to challenge the cultural binary of ability and embrace a more multi-modal approach.
Kim’s art explores sound in a variety of modalities to decenter hearing as the only, or even primary, way to experience sound. A conceptual sound artist who was born profoundly deaf, Kim describes her move into the sound artistic landscape: “In the back of my mind, I’ve always felt that sound was your thing, a hearing person’s thing. And sound is so powerful that it could either disempower me and my artwork or it could empower me. I chose to be empowered.”
For sound to empower, however, cultural perception has to move beyond the ear – a move that sound studies is uniquely poised to enable. Using Kim’s art as a guide, I investigate potential places for Deaf within sound studies. I ask if there are alternative ways to listen in a field devoted to sound. Bridging sound studies and Deaf studies it is possible to see that sound is not ableist and audist, but sound studies traditionally has suffered from an aural fixation, a fetishization of hearing as the best or only way to experience sound.
Pushing beyond the understanding of hearing as the primary (or only) sound precept, some scholars have begun to recognize the centrality of the body’s senses in sound experience. For instance, in his research on reggae, Julian Henriques coined the term sonic dominance to refer to sound that is not just heard but that “pervades, or even invades the body” (9). This experience renders the sound experience as tactile, felt within the body. Anne Cranny-Francis, who writes on multi-modal literacies, describes the intimate relationship between hearing and sound, believing that “sound literally touches us,” This process of listening is described as an embodied experience that is “intimate” and “visceral.” Steph Ceraso calls this multi-modal listening. By opening up the body to listen in multi-modal ways, full-bodied, multi-sense experiences of sound are possible. Anthropologist Roshanak Kheshti believes that the differentiation of our senses created a division of labor for our senses – a colonizing process that maximizes the use-value and profit of each individual sense. She reminds her audience that “sound is experienced (felt) by the whole body intertwining what is heard by the ears with what is felt on the flesh, tasted on the tongue, and imagined in the psyche” (714), a process she calls touch listening.
Other scholars continue to advocate for a place for the body in sound studies. For instance, according to Nina Sun Eidsheim, in Sensing Sound, sound allows us to posit questions about objectivity and reality (1), as posed in the age-old question, “If a tree falls in the forest and no one is there to hear it, does it make a sound?” Eidsheim challenges the notion of a sound, particularly music, as fixed by exploring multiple ways sound may be sensed within the body. Airek Beauchamp, through his notion of sonic tremblings, detaches sound from the realm of the static by returning to the materiality of the body as a site of dynamic processes and experiences that “engages with the world via a series of shimmers and impulses.” Understanding the body as a place of engagement rather than censorship, Cara Lynne Cardinale calls for a critical practice of look-listening that reconceptualizes the modalities of the tongue and hands.

Vibrant Vibrations by Flickr User The Manic Macrographer (CC BY 2.0)
As these scholars have identified, privileging audible sound over other senses reinforces normative ideas of communication and presumes that individuals hear, speak, and experience sound in normative ways. These ableist and audist rhetorics are particularly harmful for individuals who are Deaf. Deaf community members actively resist these ableist and audist assumptions to show that sound is not just for hearing. Kim identifies as part of the Deaf community and uses her art to challenge the ableist and audist ideologies of the sound experience. Through exploring one of Christine Sun Kim’s performance pieces, Subjective Loudness, I argue that we can conceptualize sound studies in the absence of auditory sound through the two concepts Kim’s piece were named for, subjectivity and loudness.
In creating Subjective Loudness, Kim asked 200 Tokyo residents to help her create a musical score. Hearing participants were asked to use their bodies to replicate sounds of common 85 dB noises into microphones. The sounds Kim selected included: the swishing of a washing machine, the repetitive rotation of printing press, the chaos of a loud urban street, and the harsh static of a food blender. After the list was complete, Kim has the sounds translated into a musical score, sung by four of Kim’s closest friends. The noises then become music, which Kim lowers below normal human hearing range for a vibratory experience accessible to hearing and non-hearing individuals alike; The result is music that is not heard but rather felt. As vibrations shake the walls, windows, and furniture audience members feel the music.
Kim’s performance expands upon current understandings of the body in sound by incorporating multiple materialities of sound into one experience. Rather than simply looking at an existing sound in a new way, she develops and executes the sound experience for her participants. Kim types the names of common 85 dB sounds, what most hearing people may call “noise” on an iPad – a visual representation of the sound.
By asking participants to use their bodies to replicate these sounds – to change words into noise – Kim moves visual representation moves into the audible domain. This phase is contingent on each participant’s subjective experience with the particular sound, yet it also relies on the materiality of the human body to be able to replicate complex sounds. The audible sounds were then returned to a visual state as they were translated into a musical score. In this phase, noise is silenced as it is placed as musical notes on a page. The score is then sung, audibly, once again shifting visual into audible. Noise becomes music.
Yet even in the absence of hearing the performers sing, observers can see and perhaps feel the performance. Similar to Kim’s Face Opera, this performance is not just for the ear. The music is then silenced by reducing its volume beyond that of normal hearing range. Vibrations surround the participants for a tactile experience of sound. But participants aren’t just feeling the vibrations, they are instruments of vibration as well, exerting energy back into the space that then alters the sound experience for other bodies. The materiality of the body allows for a subjective experience of sound that Kim would not be able to as easily manipulate if she simply asked audience members to feel vibrations from a washing machine or printing press. But Kim doesn’t just tinker with the subjectivity of modality, she also plays with loudness.

Christine Sun Kim at Work, Image by Flickr User Joi Ito, (CC BY 2.0)
In this performance Kim creates a think interweaving of modalities. Part of this interplay involves challenging our understanding of loudness. For instance, participants recreate loud noises, but then the loud noise is reduced to silence as it is translated into a musical score. The volume has been dialed down, as has the intensity as the musical score isolates participates. The sound experience, as the score, is then sung, reconnecting the audience to a shared experience. Floating with the ebb and flow of the sound, participants are surrounded by sound, then removed from it, only to then be surrounded again. Finally, as the sound is reduced beyond hearing range, the vibrations are loud, not in volume but in intensity. The participants are enveloped in a sonorous envelope of sonic experience, one that is felt through and within the body. This performance combats a long-standing belief Kim had about her relationship with sound.
As a child, Kim was taught, “sound wasn’t a part of my life.” She recounted in a TED talk that her experience was like living in a foreign country, “blindly following its rules, behaviors, and norms.” But Kim recognized the similarities between sound and ASL. “In Deaf culture, movement is equivalent to sound,” Kim stated in the same talk. Equating music with ASL, Kim notes that neither a musical note nor an ASL sign represented on paper can fully capture what a music note or sign are. Kim uses a piano metaphor to make her point better understood to a hearing audience. “English is a linear language, as if one key is being pressed at a time. However, ASL is more like a chord, all ten fingers need to come down simultaneously to express a clear concept in ASL.” If one key were to change, the entire meaning would change. Subjective Loudness attempts to demonstrate this, as Kim moves visual to sound and back again before moving sound to vibration. Each one, individually, cannot capture the fullness of the word or musical note. Taken as a performative whole, however, it becomes easier to conceptualize vibration and movement as sound.

Christine Sun Kim speaking ASL, Image by Flickr User Joi Ito, (CC BY 2.0)
In Subjective Loudness, Kim’s performance has sonic dominance in the absence of hearing. “Sonic dominance,” Henriques writes, “is stuff and guts…[I]t’s felt over the entire surface of the skin. The bass line beats on your chest, vibrating the flesh, playing on the bone, and resonating in the genitals” (58). As Kim’s audience placed hands on walls, reaching out to to feel the music, it is possible to see that Kim’s performance allowed for full-bodied experiences of sound – a process of touch listening. And finally, incorporating Deaf and hearing individuals in her performance, Kim shows that all bodies can utilize multi-modal listening as a way to experience sound. Kim’s performances re-centers alternative ways of listening. Sound can be felt through vibration. Sound can be seen in visual representations such as ASL or visual art.
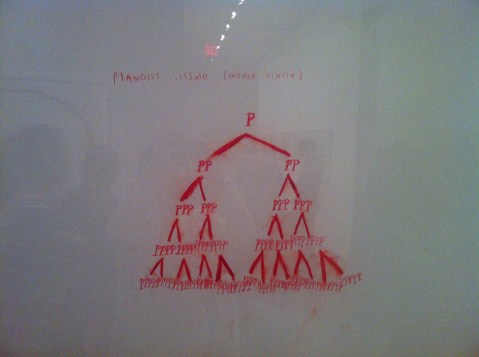
Image of Christine Sun Kim’s painting “Pianoiss….issmo” by Flickr User watashiwani (CC BY 2.0)
Through Subjective Loudness, it is possible to investigate subjectivity and loudness of sound experiences. Kim does not only explore sound represented in multi-modal ways, but weaves sound through the modalities, moving the audible to the visual to the tactile and often back again. This sound-play allows audiences to question current conceptions of sound, to explore sounds in multi-modalities, and to use our subjectivities in sharing our experiences of sound with others. Kim’s art performances are interactive by design because the materiality and subjectivity of bodies is what makes her art so powerful and recognizable. Toying with loudness as intensity, Kim challenges her audience to feel intensity in the absence of volume and spark the recognition that not all bodies experience sound in normative ways. Deaf bodies are vitally part of the soundscape, experiencing and producing sound. Kim’s work shows Deaf bodies as listening bodies, and amplifies the fact that Deaf bodies have something to say.
—
Featured image: Screen capture by Flickr User evan p. cordes, (CC BY 2.0)
—
Sarah Mayberry Scott is an Instructor of Communication Studies at Arkansas State University. Sarah is also a doctoral student in Communication and Rhetoric at the University of Memphis. Her current research focuses on disability and ableist rhetorics, specifically in d/Deafness. Her dissertation uses the work of Christine Sun Kim and other Deaf artists to explore the rhetoricity of d/Deaf sound performances and examine how those performances may continue to expand and diversify the sound studies and disability studies landscapes.
—
 REWIND! . . .If you liked this post, you may also dig:
REWIND! . . .If you liked this post, you may also dig:
Introduction to Sound, Ability, and Emergence Forum –Airek Beauchamp
The Listening Body in Death— Denise Gill
Unlearning Black Sound in Black Artistry: Examining the Quiet in Solange’s A Seat At the Table — Kimberly Williams
Technological Interventions, or Between AUMI and Afrocuban Timba –Caleb Lázaro Moreno
“Sensing Voice”*–-Nina Sun Eidsheim
Share this:

Going Hard: Bassweight, Sonic Warfare, & the “Brostep” Aesthetic


[Editor’s Note 01/24/14 10:00 am: this post has been corrected. In response to a critique from DJ Rupture, the author has apologized for an initial misquoting of an article by Julianne Escobedo Shepherd, and edited the phrase in question. Please see Comments section for discussion]
Time to ring the bell: this year, Sounding Out! is opening a brand-new stream of content to run on Thursdays. Every few weeks, we’ll be bringing in a new Guest Editor to curate a series of posts on a particular theme that opens up new ground in areas of thought and practice where sound meets media. Most of our writers and editors will be new to the site, and many will be joining us from the ranks of the Sound Studies and Radio Studies Scholarly Interest Groups at the Society for Cinema and Media Studies, as well as from the Sound Studies Caucus from the American Studies Association. I’m overjoyed to come on board as SCMS/ASA Editor to help curate this material, working with my good friends here at SO!
For our first Guest series, let me welcome Justin Burton, Assistant Professor of Music at Rider University, where he teaches in the Popular Music and Culture program. Justin also serves on the executive committee of the International Association for the Study of Popular Music-US Branch. We’re honored to have Justin help us launch this new stream.
His series? He calls it The Wobble Continuum. Let’s follow him down into the low frequencies to learn more …
Neil Verma
—
Things have gotten wobbly. The cross-rhythms of low-frequency oscillations (LFO) pulsate through dance and pop music, bubbling up and dropping low across the radio dial. At its most extreme, the wobble both rends and sutures, tearing at the rhythmic and melodic fabric of a song at the same time that it holds it together on a structural level. In this three-part series, Mike D’Errico, Christina Giacona, and Justin D Burton listen to the wobble from a number of vantage points, from the user plugged into the Virtual Studio Technology (VST) of a Digital Audio Workstation (DAW) to the sounds of the songs themselves to the listeners awash in bass tremolos. In remixing these components—musician, music, audience—we trace the unlikely material activities of sounds and sounders.
In our first post, Mike will consider the ways a producer working with a VST is not simply inputting commands but is collaborating with an entire culture of maximalism, teasing out an ethics of brostep production outside the usual urge for transcendence. In the second post, Christina will listen to the song “Braves” by a Tribe Called Red (ATCR), which, through its play with racist signifiers, remixes performer and audience, placing ATCR and its listeners in an uncanny relationship. In the final post, Justin will work with Karen Barad’s theory of posthuman performativity to consider how the kind of hypermasculinist and racist signifiers discussed in Mike’s and Christina’s pieces embed themselves in listening bodies that become sounding bodies. In each instance, we wade into the wobble listening for the flow of activity among the entanglement of producer, sound, and listener while also keeping our ears peeled for the cross-rhythms of (hyper)masculinist and racist materials that course through and around the musical phenomena.
So hold on tight. It’s about to drop.
Justin Burton
—
As an electronic dance music DJ and producer, an avid video gamer, a cage fighting connoisseur, and a die-hard Dwayne “The Rock” Johnson fan, I’m no stranger to fist pumps, headshots, and what has become a general cultural sensibility of “hardness” associated with “bro” culture. But what broader affect lies behind this culture? Speaking specifically to recent trends in popular music, Simon Reynolds describes a “digital maximalism,” in which cultural practice involves “a hell of a lot of inputs, in terms of influences and sources, and a hell of a lot of outputs, in terms of density, scale, structural convolution, and sheer majesty” (“Maximal Nation”). We could broaden this concept of maximalism, both (1) to describe a wider variety of contemporary media (from film to video games and mobile media), and (2) to theorize it as a tool for transducing affect between various media, and among various industries within global capitalism. The goal of this essay is to tease out the ways in which maximalist techniques of one kind of digital media production—dubstep—become codified as broader social and political practices. Indeed, the proliferation of maximalism suggests that hypermediation and hypermasculinity have already become dominant aesthetic forms of digital entertainment.

“DJ Pauly D” by Flickr user Eva Rinaldi, CC-BY-SA-2.0
More than any other electronic dance music (EDM) genre, dubstep—and the various hypermasculine cultures in which it has bound itself—has wholeheartedly embraced “digital maximalism” as its core aesthetic form. In recent years, the musical style has emerged as both the dominant idiom within EDM culture, as well as the soundtrack to various hypermasculine forms of entertainment, from sports such as football and professional wrestling to action movies and first-person shooter video games. As a result of the music’s widespread popularity within the specific cultural space of a post-Jersey Shore “bro” culture, the term “brostep” has emerged as an accepted title for the ultra-macho, adrenaline-pumping performances of masculinity that have defined contemporary forms of digital entertainment. This essay posits digital audio production practices in “brostep” as hypermediated forms of masculinity that exist as part of a broader cultural and aesthetic web of media convergence in the digital age.
CONVERGENCE CULTURES
Media theorist Henry Jenkins defines “convergence culture” as “the flow of content across multiple media platforms, the cooperation between multiple media industries, and the migratory behavior of media audiences who will go almost anywhere in search of the kinds of entertainment experiences they want” (Convergence Culture, 2). The most prominent use of “brostep” as a transmedial form comes from video game and movie trailers. From the fast-paced, neo-cyborg and alien action thrillers such as Transformers (2007-present), Cowboys & Aliens (2011), and G.I. Joe (2012), to dystopian first-person shooter video games such as Borderlands (2012), Far Cry 3 (2012), and Call of Duty: Black Ops 2 (2012), modulated oscillator wobbles and bass portamento drops consistently serve as sonic amplifiers of the male action hero at the edge.
Assault rifle barrages are echoed by quick rhythmic bass and percussion chops, while the visceral contact of pistol whips and lobbed grenades marks ruptures in time and space as slow motion frame rates mirror bass “drops” in sonic texture and rhythmic pacing. “Hardness” is the overriding affect here; compressed, gated kick and snare drum samples combine with coagulated, “overproduced” basslines made up of multiple oscillators vibrating at broad frequency ranges, colonizing the soundscape by filling every chasm of the frequency spectrum. The music—and the media forms with which it has become entwined—has served as the affective catalyst and effective backdrop for the emergence of an unabashedly assertive, physically domineering, and adrenaline-addicted “bro” culture.
Film theorist Lorrie Palmer argues for a relational link among gender, technology, and modes of production through hypermasculinity in these types of films and video games. Some definitive features of this convergence of hypermediation and hypermasculinity include an emphasis on “excess and spectacle, the centrality of surface over substance… ADHD cinema… transitory kinetic sensations that decenter spatial legibility… an impact aesthetic, [and] an ear-splitting, frenetic style” (“Cranked Masculinity,” 7). Both Robin James and Steven Shaviro have defined the overall aesthetic of these practices as “post-cinematic”: a regime “centered on computer games” and emphasizing “the logic of control and gamespace, which is the dominant logic of entertainment programming today.” On a sonic level, “brostep” aligns itself with many of these cinematic descriptions. Julianne Escobedo Shepherd describes the style of Borgore, one particular dubstep DJ and producer, as “misogy blow-job beats.” Other commenters have made more obvious semiotic connections between filmic imagery and the music, as Nitsuh Abebe describes brostep basslines as conjuring “obviously cool images like being inside the gleaming metal torso of a planet-sized robot while it punches an even bigger robot.”

“Ultra Music Festival 2013″ by Wikimedia user Vinch, CC-BY-SA-3.0
MASCULINITY AND DIGITAL AUDIO PRODUCTION
While the sound has developed gradually over at least the past decade, the ubiquity of the distinctive mid-range “brostep” wobble bass can fundamentally be attributed to a single instrument. Massive, a software synthesizer developed by the Berlin and Los Angeles-based Native Instruments, combines the precise timbral shaping capabilities of modular synthesizers with the real-time automation capabilities of digital waveform editors. As a VST (Virtual Studio Technology) plug-in, the device exemplifies the inherently transmedial nature of many digital tools, bridging studio techniques between digital audio workstations and analog synthesis, and acting as just one of many control signals within the multi-windowed world of digital audio production. In this way, Massive may be characterized as an intersonic control network in which sounds are controlled and modulated by other sounds through constantly shifting software algorithms. Through analysis of the intersubjective control network of a program such as Massive we are able to hear the convergence of hypermediation and hypermasculinity as aesthetic forms.

“Massive:Electronica” by Flickr user matt.searles, CC-BY-NC-SA-2.0
Media theorist Mara Mills details the notion of technical “scripts” embedded both within technological devices as well as user experiences. According to Mills, scripts are best defined as “the representation of users embedded within technology… Designers do not simply ‘project’ users into [technological devices]; these devices are inscribed with the competencies, tolerances, desires, and psychoacoustics of users” (“Do Signals Have Politics?” 338). In short, electroacoustic objects have politics, and in the case of Massive, the politics of the script are quite conventional and historically familiar. The rhythmic and timbral control network of the software aligns itself with what Tara Rodgers describes as a long history of violent masculinist control logics in electronic music, from DJs “battling” to producers “triggering” a sample with a “controller” or “executing” a programming “command” or typing a “bang” to send a signal” (“Towards a Feminist Historiography of Electronic Music,” 476).
In Massive, the primary control mechanism is the LFO (low frequency oscillator), an infrasonic electronic signal whose primary purpose is to modulate various parameters of a synthesizer tone. Dubstep artists most frequently apply the LFO to a low-pass filter, generating a control algorithm in which an LFO filters and masks specific frequencies at a periodic rate (thus creating a “wobbling” frequency effect), which, in turn, modulates the cutoff frequency of up to three oscillating frequencies at a time (maximizing the “wobble”). When this process is applied to multiple oscillators simultaneously—each operating at disparate levels of the frequency spectrum—the effect is akin to a spectral and spatial form of what Julian Henriques calls “sonic dominance.” Massive allows the user to record “automations” on the rhythm, tempo, and quantization level of the bass wobble, effectively turning the physical gestures initially required to create and modulate synthesizer sounds—such as knob-turning and fader-sliding—into digitally-inscribed algorithms.
SONIC WARFARE AND THE ETHICS OF VIRTUALITY
By positing the logic of digital audio production within a broader network of control mechanisms in digital culture, I am not simply presenting a hermeneutic metaphor. Convergence media has not only shaped the content of various multimedia but has redefined digital form, allowing us to witness a clear—and potentially dangerous—virtual politics of viral capitalism. The emergence of a Military Entertainment Complex (MEC) is the most recent instance of this virtual politics of convergence, as it encompasses broad phenomena including the use of music as torture, the design of video games for military training (and increasing collaboration between military personnel and video game designers in general), and drone warfare. The defining characteristic of this political and virtual space is a desire to simultaneously redefine the limits of the physical body and overcome those very limitations. The MEC, as well as broader digital convergence cultures, has molded this desire into a coherent hegemonic aesthetic form.
Following videogame theorist Jane McGonigal, virtual environments push the individual to “work at the very limits of their ability” in a state of infinite self-transition (Reality is Broken, 24). Yet, automation and modular control networks in the virtual environments of digital audio production continue to encourage the historical masculinist trope of “mastery,” thus further solidifying the connection between music and military technologies sounded in the examples above. In detailing hypermediation and hypermasculinity as dominant aesthetic forms of digital entertainment, it is not my goal to simply reiterate the Adornian nightmare of “rhythm as coercion,” or the more recent Congressional fears over the potential for video games and other media to cause violence. The fact that music and video games in the MEC are simultaneously being used to reinscribe the systemic violence of the Military Industrial Complex, as well as to create virtual and actual communities (DJ culture and the proliferation of online music and gaming communities), pinpoints precisely its hegemonic capabilities.

“Gear porn” by Flickr user Matthew Trentacoste, CC-BY-NC-ND-2.0
In the face of the perennial “mastery” trope, I propose that we must develop a relational ethics of virtuality. While it seems to offer the virtue of a limitless infinity for the autonomous (often male) individual, technological interfaces form the skin of the ethical subject, establishing the boundaries of a body both corporeal and virtual. In the context of digital audio production, then, the producer is not struggling against the technical limitations of the material interface, but rather emerging from the multiple relationships forming at the interface between one’s actual and virtual self and embracing a contingent and liminal identity; to quote philosopher Adriana Cavarero, “a fragile and unmasterable self” (Relating Narratives, 84).
—
Featured Image: Skrillex – Hovefestivalen 2012 by Flickr User NRK P3
—
Mike D’Errico is a PhD student in the UCLA Department of Musicology and a researcher at the Center for Digital Humanities. His research interests and performance activities include hip-hop, electronic dance music, and sound design for software applications. He is currently working on a dissertation that deals with digital audio production across media, from electronic dance music to video games and mobile media. Mike is the web editor and social media manager for the US branch of the International Association for the Study of Popular Music, as well as two UCLA music journals, Echo: a music-centered journal and Ethnomusicology Review.
—
 REWIND! . . .If you liked this post, you may also dig:
REWIND! . . .If you liked this post, you may also dig:
Toward a Practical Language for Live Electronic Performance-Primus Luta
Music Meant to Make You Move: Considering the Aural Kinesthetic-Dr. Imani Kai Johnson
Listening to Robots Sing: GarageBand on the iPad-Aaron Trammell
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments