
SO! Reads: Justin Eckstein’s Sound Tactics: Auditory Power in Political Protests


Justin Eckstein’s Sound Tactics: Auditory Power in Political Protests (Penn State University Press) is a book “about the sounds made by those seeking change” (5). It situates these sounds within a broader inquiry into rhetoric as sonic event and sonic action—forms of practice that are collective, embodied, and necessarily relational. It also addresses a long-standing question shared by many of us in rhetorical studies: Where did the sound go? And specifically, in a field that had centered at least half of its disciplinary identity around the oral/aural phenomena of speech, why did the study of sound and rhetoric require the rise of sound studies as a distinct field before it could regain traction?
Eckstein confronts this silence with urgency and clarity, offering a compelling case for how sound operates not just as a sensory experience but as a rhetorical force in public life. By analyzing protest environments where sound is both a tactic and a terrain of struggle, Sound Tactics reinvigorates our understanding of rhetoric’s embodied, affective, and spatial dimensions. What’s more, it serves as an important reminder that sound has always played an important role in studies of speech communication.

Rhetoric emerged in the Western tradition as the study and practice of persuasive speech. From Aristotle through his Greek predecessors and Roman successors, theorists recognized that democratic life required not just the ability to speak, but the ability to persuade. They developed taxonomies of effective strategies—structures, tropes, stylistic devices, and techniques—that citizens were expected to master if they hoped to argue convincingly in court, deliberate in the assembly, or perform in ceremonial life.
We’ve inherited this rhetorical tradition, though, as Eckstein notes early in Sound Tactics, in the academy it eventually splintered into two fields: one that continued to study rhetoric as speech, and another that focused on rhetoric as a writing practice. But somewhere along the way, even rhetoricians with a primary interest in speech moved toward textual representation of speech, rather than the embodied, oral/aural, sonic event that make up speech acts (see pgs 49-50).
Sound Tactics corrects this oversight first by broadening what counts as a “speech act”—not only individual enunciations, but also collective, coordinated noise. Eckstein then offers updated terminology and analytical tools for studying a wide range of sonic rhetorics. The book presents three chapter-length case studies that demonstrate these tools in action.
The first examines the digital soundbite or “cut-out” from X González’s protest speech following the school shooting at Marjory Stoneman Douglas High School in Parkland, Florida. The second focuses on the rhythmic, call-and-response “heckling” by HU Resist during their occupation of a Howard University building in protest of a financial aid scandal. The third analyzes the noisy “Casseroles” retaliatory protests in Québec, where demonstrators banged pots and pans in response to Bill 78’s attempts to curtail public protest.
A full recounting of the book’s case studies isn’t possible here, but they are worth highlighting—not only for the issues Eckstein brings to light, but for how clearly they showcase his analytical tools and methods in action. These methods, in my estimation, are the book’s most significant contribution to rhetorical studies and to scholars more broadly interested in sound analysis.
Eckstein’s analytical focus is on what he calls the “sound tactic,” which is “the sound (adjective) use of sound (noun) in the act of demanding” (2). Soundness in this double sense is both effective and affective at the sensory level. It is rhetoric that both does and is sound work—and soundness can only be so within a particular social context. For Eckstein, soundness is “a holistic assessment of whether an argument is good or good for something” (14). Sound tactics, then, utilize a carefully curated set of rhetorical tools to accomplish specific argumentative ends within a particular social collective or audience capable of phronesis or sound practical judgement (16). Unsound tactics occur when sound ceases to resonate due to social disconnection and breakage within a sonic pathway (see Eckstein’s conclusion, where he analyzes Canadian COVID-19 protests that began with long-haul truck drivers, but lost soundness once it was detached from its original context and co-opted by the far right).

Just as rhetorical studies has benefitted from the influence of sound studies, Eckstein brings rhetorical methods to sound studies. He argues that rhetoric offers a grounding corrective to what he calls “the universalization of technical reason” or “the tendency to focus on the what for so long that we forget to attend to the why” (29). Following Robin James’s The Sonic Episteme: Acoustic Resonance, Neoliberalism, and Biopolitics, he argues that sound studies work can objectify and thus reify sound qua sound, whereas rhetoric’s speaker/audience orientation instead foregrounds sound as crafted composition—shaped by circumstance, structured by power, and animated by human agency. Eckstein finds in sound studies the terminology for such work, drawing together terms such as acousmatics, waveform, immediacy, immersion, and intensity to aid his rhetorical approach. Each name an aspect of the sonic ecology.
Rhetoricians often speak of the “rhetorical situation” or the circumstances that create the opportunity or exigence for rhetorical action and help to define the relationship between rhetor and audience. While the rhetorical action itself is typically concrete and recognizable, the situation itself—which is always in motion—is more difficult to pin down. “Acousmatics” names a similar phenomenon within a sonic landscape. Noise becomes signal as auditors recognize and respond to particular kinds of sound—a process that requires cultural knowledge, attention, and the proverbial ear to hear. A sound’s origins within that situation may be difficult to parse. Acousmastics accounts for sound’s situatedness (or situation-ness) within a diffuse media landscape where listeners discern signal-through-noise, and bring it together causally as a sound body, giving it shape, direction, and purchase. As such a “sound body” has a presence and power that a single auditor may not possess.

Eckstein defines “sound body” as “our imaginative response to auditory cues, painting vivid, often meaningful narratives when the source remains unseen or unknown” (10). And while the sound body is “unbounded,” it “conveys the immediacy, proximity, and urgency typically associated with a physical presence (12). Thus, a sound body (unlike the human bodies it contains) is unseen, but nonetheless contained within rhetorical situations, constitutive of the ways that power, agency, and constraint are distributed within a given rhetorical context. Eckstein’s sound body is thus distinct from recent work exploring the “vocal body” by Dolores Inés Casillas, Sebastian Ferrada, and Sara Hinojos in “The ‘Accent’ on Modern Family: Listening to Vocal Representations of the Latina Body” (2018, 63), though it might be nuanced and extended through engagement with the latter. A focus on the vocal body brings renewed attention to the materialities of the voice—“a person’s speech, such as perceived accent(s), intonation, speaking volume, and word choice” and thus to sonic elements of race, gender, and sexuality. These elements might have been more explicitly addressed and explored in Eckstein’s case studies.
Eckstein uses these terms to help us understand the rhetorical complexities of social movements in our contemporary, digital world—movements that extend beyond the traditional public square into the diverse forms of activism made possible by the digital’s multiplicities. In that framework he offers the “waveform” as a guiding theoretical concept, useful for discerning the sound tactics of social movements. A waveform—the digital, visual representation of a sonic artifact—provides a model for understanding how sound takes shape, circulates, and exerts force. Waveforms also obscure a sound’s originating source and thus act acousmastically.
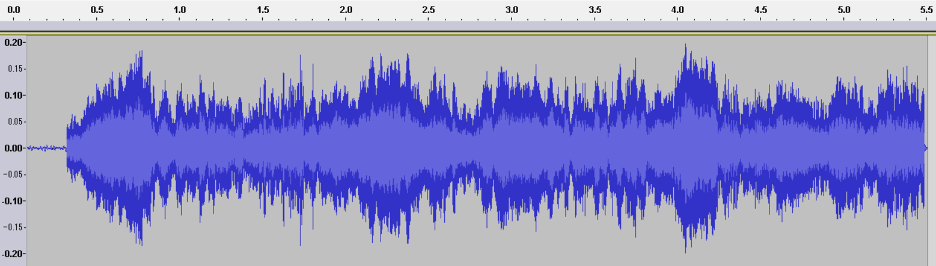
“[A] waveform is a visual representation of sound that measures vibration along three coordinates: amplitude, frequency, and time” (50). Eckstein draws on the waveform’s “crystallization” of a sonic moment as a metaphor to show sound’s transportability, reproducibility, and flexibility as a media object, and then develops a set of analytical tools for rhetorical analysis that match these coordinates: immediacy, immersion, and intensity. As he describes:
Immediacy involves the relationship between the time of a vibration’s start and end. In any perception of sound, there can be many different sounds starting and stopping, giving the potential for many other points of identification. Immersion encompasses vibration’s capacity to reverberate in space and impart a temporal signature that helps locate someone in an area; think of the difference between an echo in a canyon and the roar of a crowd when you’re in a stadium. Finally, intensity describes the pressure put on a listener to act. Intensity provides the feelings that underwrite the force to compel another to act. Each of these features and the corresponding impact of this experience offer rhetorical intervention potential for social movements. (51)
This toolset is, in my estimation, the book’s most cogent contribution for those working with or interested in sonic rhetorics. Eckstein’s case studies—which elucidate moments of resistance to both broad and incidental social problems—offer clear examples of how these interrelated aspects of the waveform might be brought to bear in the analysis of sound when utilized in both individual and collective acts of social resistance.
To highlight just one example from Eckstein’s three detailed case studies, consider the rhetorical use of immediacy in the chapter titled “The Cut-Out and the Parkland Kid.” The analysis centers on a speech delivered by X González, a survivor of the February 14, 2018, Marjory Stoneman Douglas High School shooting in Parkland, Florida. Speaking at a gun control rally in Ft. Lauderdale six weeks after the tragedy, González employed the “cut-out,” a sound tactic that punctuated their testimony with silence.
Embed from Getty Images.
As the final speaker, González reflected on the students lost that day—students who would no longer know the day-to-day pleasures of friendship, education, and the promise of adulthood. The “cut-out” came directly after these remembrances: an extended silence that unsettled the expectations of a live audience disrupting the immediacy of such an event. As the crowd sat waiting, González remained resolute until finally breaking the silence: “Since the time that I came out here, it has been six minutes and twenty seconds […] The shooter has ceased shooting and will soon abandon his rifle, blend in with the students as they escape, and walk free for an hour before arrest” (69–70).
As Eckstein explains, González “needed a way to express how terrifying it was to hide while not knowing what was happening to their friends during a school shooting” (61). By timing the silence to match the duration of the shooting, the focus shifted from the speech itself to an embodied sense of time—an imaginary waveform of sorts that placed the audience inside the terror through what Eckstein calls “durational immediacy.” In this way, silence operated as a medium of memory, binding audience and victims together through shared exposure to the horrors wrought over a short period of time.
…
Sound Tactics is a must-read for those interested in a better understanding of sound’s rhetorical power—and especially how sonic means aid social movements. In conclusion, I would mention one minor limitation of Eckstein’s approach. As much as I appreciated his acknowledgement of sound’s absence from the Communication side of rhetoric, such a proclamation might have benefited from a more careful accounting of sound-related works in rhetorical studies writ large over the last few decades. Without that fuller context, readers may conclude that rhetorical studies has—with a few exceptions—not been engaged with sound. To be fair, the space and focus of Sound Tactics likely did not permit an extended literature review. There is thus an opportunity here to connect Eckstein’s important intervention with the work of other rhetoricians who have also been advancing sound studies.
I am including here a link to a robust (if incomplete) bibliography of sound-related scholarship that I and several colleagues have been compiling, one that reaches across Communication and Writing disciplines and beyond.
—
Featured Image: Family at the CLASSE (Coalition large de l’ASSÉ ) Demonstration in Montreal, Day 111 in 2012 by Flicker User scottmontreal CC BY-NC 2.0
—
Jonathan W. Stone is Associate Professor of Writing and Rhetoric at the University of Utah, where he also serves as Director of First-Year Writing. Stone studies writing and rhetoric as emergent from—and constitutive of—the mythologies that accompany notions of technological advance, with particular attention to sensory experience. His current research examines how the persisting mythos of the American Southwest shapes contemporary and historical efforts related to environmental protection, Indigenous sovereignty, and racial justice, with a focus on how these dynamics are felt, heard, and lived. This work informs a book project in progress, tentatively titled A Sense of Home.
Stone has long been engaged in research that theorizes the rhetorical affordances of sound. He has published on recorded sound’s influence in historical, cultural, and vernacular contexts, including folksongs, popular music, religious podcasts, and radio programs. His open-source, NEH-supported book, Listening to the Lomax Archive, was published in 2021 by the University of Michigan Press and investigates the sonic archive John and Alan Lomax created for the Library of Congress during the Great Depression. Stone is also co-editor, with Steph Ceraso, of the forthcoming collection Sensory Rhetorics: Sensation, Persuasion, and the Politics of Feeling (Penn State U Press), to be published in January 2026.
—

REWIND!…If you liked this post, check out:
SO! Reads: Marisol Negrón’s Made in NuYoRico: Fania Records, Latin Music, and Salsa’s Nuyorican Meanings –Vanessa Valdés
Quebec’s #casseroles: on participation, percussion and protest–-Jonathan Sterne
SO! Reads: Steph Ceraso’s Sounding Composition: Multimodal Pedagogies for Embodied Listening-–Airek Beauchamp
Faithful Listening: Notes Toward a Latinx Listening Methodology––Wanda Alarcón, Dolores Inés Casillas, Esther Díaz Martín, Sara Veronica Hinojos, and Cloe Gentile Reyes
The Sounds of Equality: Reciting Resilience, Singing Revolutions–Mukesh Kulriya
SO! Reads: Todd Craig’s “K for the Way”: DJ Rhetoric and Literacy for 21st Century Writing Studies—DeVaughn Harris
Share this:

Sound and Sanity: Rallying Against “The Voice”
 John Stewart’s recent Rally to Restore Sanity was an important political demonstration for all of the fairly-busy people in the USA. It was a moment when those who work forty hours per week or who have too many social bookings were able to come to the United States Capitol in order to proclaim with their “indoor voices” that the current political debates in America are characterized by too much irrationality and fear. As the RTRS website states, Stewart’s rally was expressly for “the people who think shouting is annoying, counterproductive, and terrible for your throat; who feel that the loudest voices shouldn’t be the only ones that get heard; and who believe that the only time it’s appropriate to draw a Hitler mustache on someone is when that person is actually Hitler. Or Charlie Chaplin in certain roles.” It’s interesting that the aim of this rally was ostensibly against the “shouting” and the “loudest voices” rather than any specific ideas, statements, or political positions. In other words, the problem, as Stewart sees it, is that public debates are too full of noise. And it is this noise that must be vanquished—or that, at least, should be modulated to an “indoor” level.
John Stewart’s recent Rally to Restore Sanity was an important political demonstration for all of the fairly-busy people in the USA. It was a moment when those who work forty hours per week or who have too many social bookings were able to come to the United States Capitol in order to proclaim with their “indoor voices” that the current political debates in America are characterized by too much irrationality and fear. As the RTRS website states, Stewart’s rally was expressly for “the people who think shouting is annoying, counterproductive, and terrible for your throat; who feel that the loudest voices shouldn’t be the only ones that get heard; and who believe that the only time it’s appropriate to draw a Hitler mustache on someone is when that person is actually Hitler. Or Charlie Chaplin in certain roles.” It’s interesting that the aim of this rally was ostensibly against the “shouting” and the “loudest voices” rather than any specific ideas, statements, or political positions. In other words, the problem, as Stewart sees it, is that public debates are too full of noise. And it is this noise that must be vanquished—or that, at least, should be modulated to an “indoor” level.
Stewart’s opposition between sound and sanity is actually quite common. Public noise is senseless sound, while rational debate is meaningful sound. The logic goes, then, that public debates need to have less sound or, at least, regulated sound. They must have two people who are willing to speak quietly and rationally, hear each other’s points, and raise and answer each other’s objections until some kind of consensus is built. Good public debates require less sound and more sanity.
But is this sonic modulation the right way to conduct public debate and to persuade others? The truth is that the relation between noise and reason, between senselessness and sanity, is very, very complicated. In fact, although it is a collective national fantasy that good debate is built on reason, there are lots of reasons to suggest that reason doesn’t always (or even predominately) come first. Rather, it’s often the sound that convinces people in an argument—not the reason. And in public debate, the particular sound is “The Voice.”
By looking at an episode of the animated TV show Batman: The Brave and the Bold let’s listen to how The Voice can persuade people to act against their own sanity. In “Mayhem of the Music Meister,” Neil Patrick Harris gives voice to the Music Meister, a singing villain whose tone and rhythm instantly hypnotize those who hear him and bend their actions to his will:
As the opening sequence begins, the audience is prepped for a standard showdown between three villains: Black Manta, Gorilla Grodd, and Clock King, who plan to steal a communications satellite; and three heroes: Black Canary, Green Arrow, and  Aquaman, who are prepared to save the day and stop the theft of the industrial hardware. But this showdown is interrupted when–to his surprise and seemingly against his self-control–Black Manta bursts into song, crooning, “I’m sounding shrill against my will.” Soon the other villains and heroes follow suit. All lose control of their voices and begin singing and acting against their own will. What’s interesting about this moment is that losing control of their voices signals a complete loss of self-control. Yet this loss brings with it a division within themselves. On one hand, they recognize that they are singing. On the other hand, they are conscious of the fact that they are equally unable to prevent their own actions. They must sing; they must dance; they must dissolve the initial division between heroes and villains and join together in a revised plan to launch the communications satellite.
Aquaman, who are prepared to save the day and stop the theft of the industrial hardware. But this showdown is interrupted when–to his surprise and seemingly against his self-control–Black Manta bursts into song, crooning, “I’m sounding shrill against my will.” Soon the other villains and heroes follow suit. All lose control of their voices and begin singing and acting against their own will. What’s interesting about this moment is that losing control of their voices signals a complete loss of self-control. Yet this loss brings with it a division within themselves. On one hand, they recognize that they are singing. On the other hand, they are conscious of the fact that they are equally unable to prevent their own actions. They must sing; they must dance; they must dissolve the initial division between heroes and villains and join together in a revised plan to launch the communications satellite.
From this vantage point, we can return to the alleged difference between sound and sanity. The first problem is that The Voice bypasses reason, making people comply without, or even in spite of, critical reflection. It generally does this in two ways. As the Music Meister episode illustrates, The Voice divides the hearer against himself, taking over his body while he remains fully aware of the situation. In other words, the Voice exerts a direct control over a body while the hearer remains in control of his or her consciousness. The Voice is a science fiction staple. For example, in Frank Herbert’s Dune, the Bene Gesserit are able to speak directly to the unconscious of the hearer while the conscious mind is aware that the body is controlled by The Voice. In the filmed version, an extra quality is added to The Voice in order to highlight the difference between its conscious and subconscious aspects. The Voice must sound different from the voice.
The second way that the Voice bypasses reason is in the way in which a voice– often described musically–makes people lose control of their ability for critical reflection. An example of this form of The Voice also comes from science fiction: the Jedi Mind Trick made famous in Star Wars. In this case, Obi Wan Kenobi bypasses the storm troopers’ ability to recognize the droids they are looking for, even as C3-PO and R2-D2 hang awkwardly from the back of his sandspeeder.
 When the logical reasons inevitably fail to account for the act of persuasion in public discourse, others come to the forefront. Often people will say the speaker has charisma, but often they are really referring to The Voice’s role as the persuasive element. What persuades? Not the logical argument, not sanity, but The Voice. And, often, this is against our better judgments or in spite of ourselves. So when Stewart acknowleges the role that “senseless” sound plays in public debates, he goes too far when he calls for “meaningful” sound instead. The two are not in opposition as the RTRS suggested. When all is said and done, sanity almost always depends on so-called senseless sound.
When the logical reasons inevitably fail to account for the act of persuasion in public discourse, others come to the forefront. Often people will say the speaker has charisma, but often they are really referring to The Voice’s role as the persuasive element. What persuades? Not the logical argument, not sanity, but The Voice. And, often, this is against our better judgments or in spite of ourselves. So when Stewart acknowleges the role that “senseless” sound plays in public debates, he goes too far when he calls for “meaningful” sound instead. The two are not in opposition as the RTRS suggested. When all is said and done, sanity almost always depends on so-called senseless sound.












![]()
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments