
Listening to Digitized “Ratatas” or “No Sabo Kids”

This series listens to the political, gendered, queer(ed), racial engagements and class entanglements involved in proclaiming out loud: La-TIN-x. ChI-ca-NA. La-TI-ne. ChI-ca-n-@. Xi-can-x. Funded by an Andrew W. Mellon Foundation as part of the Crossing Latinidades Humanities Research Initiative, the Latinx Sound Cultures Studies Working Group critically considers the role of sound and listening in our formation as political subjects. Through both a comparative and cross-regional lens, we invite Latinx Sound Scholars to join us as we dialogue about our place within the larger fields of Chicanx/Latinx Studies and Sound Studies. We are delighted to publish our initial musings with Sounding Out!, a forum that has long prioritized sound from a queered, racial, working-class and “always-from-below” epistemological standpoint. —Ed. Dolores Inés Casillas
—
This post is co-authored by Sara Veronica Hinojos and Eliana Buenrostro
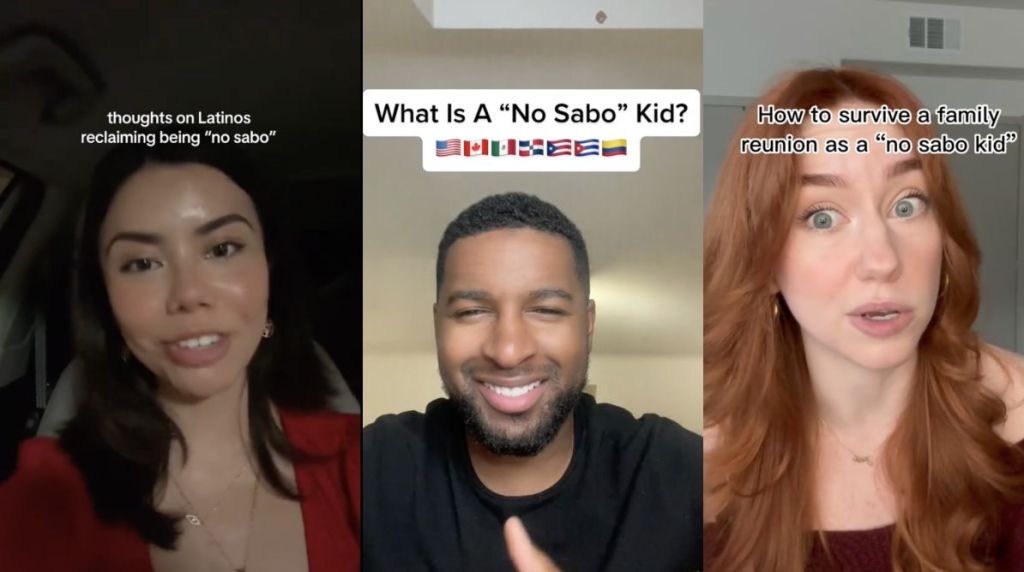
Cardi B eloquently reminds us that our español, as US Latinxs, might seem “muy ratata;” an apt phrase, heard lyrically within her music, used here to characterize inventive, communicative Spanglish word play. Yet, the proliferation of hashtags used to shame and silence second and later generations of Latinx kids runs counter to Cardi B’s ratata blessings.
The hashtags #nosabokid #nosabokids #nosabokidsbelike #nosabokidsorry #iamanosabokid represents a collective acknowledgment of Gloria Anzaldúa’s “linguistic terrorism.” Featured on NBC News, Locatora Radio, the Los Angeles Times and, surely, referenced within familial discussions, #nosabo has brought, once again, to the fore the coupling and, we fiercely argue, the need to decouple language (“proficiency”) from that of Latinx identities. The phrase “no sabo” – a non-standard Spanish conjugation of the phrase “no sé” for “I don’t know” – has become a stand-in as both a linguistic (bad) sign of Americanization and/or a (good) marker of ethnic, bicultural pride.
Anzaldúa has long warned us that, “[e]ven our own people, other Spanish speakers nos quieren poner candados en la boca [want to put locks on our mouths]” (1999, 76). In many ways, the “no sabo” label silences or “locks” one’s mouth. The institutional attempts to Americanize Spanish-speaking individuals constitute a form of violence that has led to the erosion of Spanish spoken among Mexican and Latino families in the United States. Today, children of immigrants are ridiculed for speaking “broken” Spanish, yet, for decades Mexicans raised in the United States experienced harsh consequences and blatant discrimination for speaking Spanish in public; this racism continues today.
As scholars of Latinx listening, these social media posts can be incredibly frustrating. They remind us of the sad reality that many Latinx people do not know their own history or better yet futures. Anzaldúa would describe the intraethnic linguistic policing as, “peleando con nuestra propia sombra” (fighting with our own shadow) (1999, 76); it’s both unproductive and self-inflicting. Poet Michele Serros describes her experiences being policed in her 1993 poem “Mi Problema”:
Eyebrows raise
My sincerity isn’t good enough
when I request:
“Hable mas despacio por favor.”
My skin is brown
just like theirs,
but now I’m unworthy of the color
‘cause I don’t speak Spanish
the way I should.
Then they laugh and talk about
mi problema
in the language I stumble over [. . .]
–Opening stanza of “Mi Problema” from Chicana Falsa
Applied to speakers (mostly kids) whose Spanish is identified as grammatically wrong or heard with an Anglicized accent, “no sabo” hashtags can encourage people to police each other’s tongues. Social media videos even show parents testing their children’s Spanish. When a child cannot remember or (mis)pronounces a Spanish word, or worse, uses a Spanglish iteration, they are disparagingly called “no sabo kids” (Stransky et al. 2023). Other posts reveal Latinx users’ fear of having and raising a “no sabo kid” or not wanting to date a “no sabo kid.”
Lastly, other posts proudly admit to being a “no sabo kid.” The latest series of “no sabo kids” hashtags are also unapologetic declarations that their language does not define the totality of their being or experiences.
Indeed, speaking Anglicized Spanish as Latinx can surface feelings of embarrassment, disappointment, and mockery from presumed “perfect” Spanish speakers or self-appointed “real” Spanish-English bilinguals. Televised instances of Latin Americans chastising the Spanish spoke of Latinx speakers or the public praise thrown at Ben Affleck for his spoken Spanish in comparison to the public side eyes given to wife, Bronx-raised, Jennifer Lopez are both hyper-mediated instances of #nosabokids.
White people might be praised for learning Spanish – no matter how Anglicized their accent – yet Latinx people whose Spanish is detected as Anglicized, are (racially whitewashed) “no sabo kids” (Urciuoli 2013). And yes, the use of the word “kids” alone infantilizes the speaker as some social media posts point to both children and adults as “no sabo.”
Irrespective of the proficiency in English or Spanish, Latinx individuals share experiences of being corrected in educational settings, at home, or online. The misuse of verb conjugation, such as using “sabo” instead of “sé,” is a developmental challenge encountered even by Spanish-speaking children who are learning solely Spanish. In other words, it is not an exclusive practice among Spanish-English bilingual speakers, despite what social media posts insist. The public discourse that some Latinx social media users are battling is what Jonathan Rosa calls “looking like a language” and, in this case, not “sounding like a race” (Rosa 2019).
Speaking, listening, and living “muy ratata” with inventive modes of Spanish and English in the U.S. is clearly heard as threatening. For instance, knowledge of another language has always challenged monolingual conservative speakers. Bilingual speakers and listeners routinely teach us how to resignify language practices and ultimately, the meaning of being a “no sabo kid.” (Or how Nancy Morales argues about Los Jornaleros del Norte and Radio Ambulante in the ways they offer new forms of belonging by understanding themselves and respecting each other.)
Entrepreneurs with Chicana and Latina feminist identities are modeling refashioned ways of belonging. For example, Los Angeles-based brand Hija de tu Madre created t-shirts and crewneck sweatshirts with the words “no sabo” to counter the ridicule heard and circulated within social media and to loudly claim a racial, linguistic identity that has nothing to do with shame. Similarly, the card game “Yo Sabo,” founded by a first generation college student of Mexican descent, Carlos Torres, looks for ways to improve his Spanish and simultaneously creates another way to connect with immigrant family members. Labels like “no sabo ” that are intended to categorize people in harmful ways are being repurposed to build community.
The podcast Locatora Radio: A Radiophonic Novela released an episode on April 12, 2023, Capítulo 160: No Sabo Kids, detailing historical reasons why Latinx ethnicities have structurally been banned from learning and speaking Spanish. Perhaps most importantly, Locatora Radio shares with listeners lengthy listener-recorded testimonios.
They provide diverse personal reasons for identifying as a “no sabo kid.” One listener, Paula, is a transracial adoptee whose first language was Spanish. However, because of forced family separation and the foster care system in Virginia, she “lost” her Spanish. Paula was enrolled in Spanish language classes throughout her formal schooling and accepts that her reclaiming of culture and language is a lifelong process. The use of verbal testimonios, a format that makes it possible for podcast listeners to listen to fellow listeners, moves away from posts above that wag their digital finger at “no sabo kids” and instead gives them a space to speak for themselves.
The intense personal and communal fear of losing aspects of culture or language makes it difficult to understand how shifts in language practices and accents are important new forms of belonging as Latinx in the U.S. If we cannot accept our own linguistic diversity, how do we expect others to listen to us?
—
Featured Image: A selection of TikTok #nosabo memes from @marlene.ramir, @yospanishofficial, and @saianana
—
Sara Veronica Hinojos is an Assistant Professor of Media Studies at Queens College, CUNY. Her research focuses on representation of Chicanx and Latinx within popular film and television with an emphasis on gender, race, language politics, and humor studies. She is currently working on a book manuscript that investigates the racial function of linguistic “accents” within media, called: GWAT?!: Chicanx Mediated Race, Gender, and “Accents” in the US.
Eliana Buenrostro is a Ph.D. student at the University of California, Riverside in the Department of Ethnic Studies. She received her master’s in Latin American and Latino Studies from the University of Illinois at Chicago. Her research examines the criminalization, immigration, and deportation of Chicanes and Latines through the lens of music and other forms of cultural production. She is a recipient of the Crossing Latinidades Mellon Fellowship.
—
—

REWIND!…If you liked this post, you may also dig:
Ronca Realness: Voices that Sound the Sucia Body—Cloe Gentile Reyes
From Spanish to English to Spanish: How Shakira’s VMA Performance Showcases the New Moment in Latin Music “Crossover”—Petra Rivera-Rideau and Vanessa Díaz
Echoes in Transit: Loudly Waiting at the Paso del Norte Border Region—José Manuel Flores & Dolores Inés Casillas
Xicanacimiento, Life-giving Sonics of Critical Consciousness—Esther Díaz Martín and Kristian E. Vasquez
“Don’t Be Self-Conchas”: Listening to Mexican Styled Phonetics in Popular Culture*–Sara Hinijos and Inés Casillas
Share this:

Stir It Up: From Polyphony to Multivocality in A Brief History of Seven Killings

 For many, the audiobook is a source of pleasure and distraction, a way to get through the To Read Pile while washing dishes or commuting. Audiobooks have a stealthy way of rendering invisible the labor of creating this aural experience: the writer, the narrator, the producer, the technology…here at Sounding Out! we want to render that labor visible and, moreover, think of the sound as a focus of analysis in itself.
For many, the audiobook is a source of pleasure and distraction, a way to get through the To Read Pile while washing dishes or commuting. Audiobooks have a stealthy way of rendering invisible the labor of creating this aural experience: the writer, the narrator, the producer, the technology…here at Sounding Out! we want to render that labor visible and, moreover, think of the sound as a focus of analysis in itself.
Over the next few weeks, we will host several authors who will make all of us think differently about the audiobook selections on our phone, in our car, and in our radios. Last week we listened to a book that listens to Dublin, in a post by Shantam Goyal. Today we have seven narrators telling us the story of an assassination attempt on Bob Marley. What will the audiobook whisper to us that the book cannot speak?
—Managing Editor Liana Silva
Reviews of A Brief History of Seven Killings, Marlon James’ 686-page rendering of the echoes of an assassination attempt on Bob Marley, almost invariably invoke the concept of polyphony to name its adroit use of multiple narrators. In The New York Times, Zachary Lazar maintained that the “polyphony and scope” of the 2014 novel made it much more than a saga of drug and gang violence stretching from 1970s Kingston to 1990s New York. And the Booker Prize, which James was the first Jamaican to win, similarly praised it as a “rich, polyphonic study,” with chief judge Michael Wood calling attention to the impressive “range of voices and registers, running from the patois of the street posse to The Book of Revelation.” It was thus not only the sheer number of voices in a preliminary three-page “Cast of Characters” that critics so unanimously admired but also the variety and nuance evident within them. Norwegian publisher Mime Books even took these polyphonic features a step further by hiring not one but twelve translators in a casting process that auditioned prominent novelists, playwrights, and performers.

Cover of the book, under fair use
James recalls realizing early on that this novel would be one “driven only by voice” (687), which might make such enthusiastic responses to its plurality of perspectives seem unsurprising. But what happens when such polyphony leaves the page behind and actual material voices drive its delivery? If the audiobook is a format of the novel (and here I follow Jonathan Sterne’s definition of format in MP3: The Meaning of a Format as “a whole range of decisions that affect the look, feel, experience, and workings of a medium” [7]), what lessons can listeners learn that print cannot provide? As I argue, the 26-hour-long audiobook version of A Brief History, which Highbridge Audio produced with seven actors (Robertson Dean, Cherise Boothe, Dwight Bacquie, Ryan Anderson, Johnathan McClain, Robert Younis, Thom Rivera), allows us to engage with multivocality rather than polyphony, which is to say the multiple vocal performances of a single individual rather than the presence of many narrators within a print work. And just as this novel’s polyphonic structure destabilizes any attempt at a definitive account of the events it portrays, the multifaceted performances of its audio format work to untrain ears that have been conditioned to hear necessary ties between voices and bodies.
Of course, this effect is not one that most listeners consciously seek, as reviews of the audiobook articulating various reasons for turning to this format as well as diverging responses to it readily attest. Gayle, on Audible, began with the print version: “but as soon as I got to the first chapter that was written in Jamaican patois I knew that I was not able to do that in my head and I was going to miss a lot.” Sound here conveys sense more swiftly than the page, the ear apparently better suited than the eye to encounter difference. (Woodsy, another reviewer, even felt emboldened to ventriloquize in text that sonically distinctive speech: “I found that listening to the Audible version was helpful. Now all me need do is stop thinking in Jamaican.”) Yet it was Andre who offered by far the most memorable characterization of the audiobook and its affordances. As he explained, in James’ novel “the language is a thick, tropical forest of words. Audiobook is the machete that slices through this forest of words so I can enjoy the treasures inside.” The violence of this metaphor matches that of the novel’s most disturbing scenes, yet what is most striking is the way it reiterates once more how reviewers found it easier to access the work aurally rather than visually.

“Studio Microphone” by Richard Feliciano, CC BY-NC-ND 2.0
These reviews, and other similarly favorable appraisals, rarely consider the audiobook on its own terms, insisting instead on comparisons with the text. Negative ones, however, often note distinctively sonic features, with some reviewers echoing one of the Booker judges—who reportedly consulted a Jamaican poet about the accuracy of James’ ear for dialogue—by questioning the veracity of the Jamaican accents in a novel that also features American, Colombian, and Cuban ones. Tending to readily identify themselves as Jamaican, these writers and listeners rarely acknowledge that at least some of the actors were born on the island when asserting that the accents are off. In any case, such efforts to link sound and authenticity, as Liana Silva has argued with respect to the audiobook, wrongly suggest that those who belong to a group must conform to a single sound. James, too, distrusts discourses of the authentic, as characters repeatedly cast suspicion and scorn on anyone uttering the phrase “real Jamaica.”
If the polyphony in James’ novel prevents any one perspective from becoming either representative or definitive, the audiobook pushes this process even further by demonstrating how a single performer’s voice can possess such range that it seems to contain multiple ones. Each performer is responsible for all the voices within the sections narrated by their primary characters, which means that the same character can occasionally be voiced by different actors. In one section, a performer does the voices of a tough-talking Chicago-born hitman and the jittery Colombians he speaks with in Miami; in others, that same performer is both a white Rolling Stone journalist from Minnesota who’s attuned to racial difference and the black Jamaicans he converses with in Kingston. Continuity or strict one-to-one correspondences between performer and character ultimately matter less than the displays of vocal difference that allow the audiobook to contest essentialized notions of voice.
As a result, the audiobook articulates just how constructed vocal divisions based on race, gender, and class are by having its performers constantly cross them. It amplifies the very arbitrariness of such divisions and thereby reveals how, if the page is the space of polyphony, then what the audiobook stages is multivocality. Although they might seem like synonyms, these two terms can actually help us appreciate crucial differences and, in doing so, highlight the specificity of the audio format. On the one hand, –phony or phōnē, as Shane Butler reminds us in The Ancient Phonograph, ambiguously refers to both voice and the human capacity for speech (36), whereas –vocality centers the voice. On the other, the shift from the Greek poly- to the Latin multi- signals a contrast in what gets counted: while polyphony names the quantity of perspectives contributing to a narrative (when introducing it in Problems of Dostoevsky’s Poetics, Mikhail Bakhtin emphasized that polyphony consisted of “a plurality of independent and unmerged voices and consciousnesses” [6]), multivocality instead specifies how the number of voices can exceed the number of performers. In this way, the concept of multivocality outlined here with respect to the audiobook resonates with its use in another context by Katherine Meizel, who mobilizes it with reference to singing and the borders of identity. In both cases, voice names a multiplicity of practices rather than an immutable or inevitable expression, which in turn aligns with Nina Sun Eidsheim’s argument in The Race of Sound about the voice being not singular but collective and not innate but cultural (9).

“Last Exit (Recording Studio)” by Flickr user Drew Ressler, CC BY-NC-ND 2.0
We can therefore say that where print-based polyphony works on the eye by placing various perspectives on a page without necessarily challenging visual perceptions of difference, multivocality in the audiobook can retrain an ear’s culturally ingrained ideas about voice. James himself has experience with these seemingly inescapable meanings assigned to vocal sounds. In a moving essay for The New York Times Magazine, he recounts how, even at the age of 28, “I was so convinced that my voice outed me as a fag that I had stopped speaking to people I didn’t know.” That was already long after high school, when, as he remembered in a New Yorker profile, he had begun “tape-recording his efforts to sound masculine, repeating words like ‘bredren’ and ‘boss.’” He was well aware of the links that listeners created between voice and identity and that could, as he suggests, prove risky in a place with overt homophobia like Jamaica. Writing, however, offered him a space to take on any voice and, at the same time, not be concerned with the sound of his own.
Yet if the page allowed James to effortlessly shift among narrative voices, the audiobook format exhibits voices that ostensibly shift without any effort. Perhaps the most compelling example emerges in the work of Cherise Boothe, whose performance of the novel’s sole female primary character presents the voices of other figures as well. Toward the end of the novel, this character, Dorcas Palmer, is a caretaker for a much older and wealthier white man with amnesia in New York. Boothe not only captures the changes as Palmer often eliminates her Jamaican accent and occasionally lets it loose but also registers the man’s moments of lucidity and confusion. Even if, as listeners, we understand that Boothe is the voice behind both of these characters, the two vocal performances are so distinct that they effectively erode the basis for any beliefs about how a certain body should sound.
Adopting different voices is certainly not unique to the audiobook, but it does provide one of the few forms of extended exposure to this practice. Yet it is worth noting that A Brief History markedly differs from the model of a more extensive cast like the one comprised of 166 voices that recorded George Saunders’ Lincoln in the Bardo. By assigning a performer to every character, such productions ultimately emphasize vocal uniqueness in roughly the same way that Adriana Cavarero conceives it, namely as an index of individuality. But there the voice remains something singular or somehow essential, for there is no opportunity to perform the plurality that appears across A Brief History. At the same time, the use of seven actors also offers a contrast with the opposite extreme: a single performer responsible for all the roles, which demonstrates multivocality but does so on such a small scale that it feels exceptional instead of ordinary. The middle ground, which is to say the model found in A Brief History, allows us to hear multiple instances of how the voice is entrained rather than essential, possibility rather than inevitability.

Screenshot from Youtube video “Marlon James: A Brief History of Seven Killings” by Chicago Humanities Festival
When briefly addressing audiobooks in an interview, James remarked that this format possesses a distinct advantage: “even something that is not necessarily plain can be translated because of tone and symbol and voice.” In other words, a voice can register its changing surroundings; conveying these subtle transformations on the page, however, is often far more difficult. This shortcoming is one that Edward Kamau Brathwaithe once memorably described when explaining why he insisted on using a tape recorder in a lecture on language in the Caribbean: “I want you to get the sound of it, rather than the sight of it.” The idiomatic familiarity of the first half, which clashes so sharply with the awkwardness of the second, suggests that the multivocality of an audiobook can open ears by accentuating how the voice is not fixed but in constant formation.
—
Featured Image: “Audiobook” by Flickr user ActuaLitte, CC-BY-SA-2.0
—
Sam Carter is a PhD Candidate in Romance Studies at Cornell University. His work on literature and sound in the Southern Cone has appeared in Latin American Textualities: History, Materiality, and Digital Media and is forthcoming in the Revista Hispánica Moderna.
—
 REWIND! . . .If you liked this post, you may also dig:
REWIND! . . .If you liked this post, you may also dig:
SO! Reads: Jonathan Sterne’s MP3: The Meaning of a Format–Aaron Trammell
Radio de Acción: Violent Circuits, Contentious Voices: Caribbean Radio Histories–Alejandra Bronfman
“Scenes of Subjection: Women’s Voices Narrating Black Death“–Julie Beth Napolin
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments