
SO! Amplifies: Allison Smartt, Sound Designer of MOM BABY GOD and Mixed-Race Mixtape

 SO! Amplifies. . .a highly-curated, rolling mini-post series by which we editors hip you to cultural makers and organizations doing work we really really dig. You’re welcome!
SO! Amplifies. . .a highly-curated, rolling mini-post series by which we editors hip you to cultural makers and organizations doing work we really really dig. You’re welcome!
—
Currently on the faculty and the associate technical director of California Institute of the Arts Sharon Lund Disney School of Dance, Allison Smartt worked for several years in Hampshire’s dance program as intern-turned-program assistant. A sound engineer, designer, producer, and educator for theater and dance, she has created designs seen and heard at La MaMa, The Yard, Arts In Odd Places Festival, Barrington Stage Company, the Five College Consortium, and other venues.

Allison Smartt
She is also the owner of Smartt Productions, a production company that develops and tours innovative performances about social justice. Its repertory includes the nationally acclaimed solo-show about reproductive rights, MOM BABY GOD, and the empowering, new hip-hop theatre performance, Mixed-Race Mixtape. Her productions have toured 17 U.S. cities and counting.
Ariel Taub is currently interning at Sounding Out! responsible for assisting with layout, scoping out talent and in the process uncovering articles that may relate to or reflect work being done in the field of Sound Studies. She is a Junior pursuing a degree in English and Sociology from Binghamton University.
__
Recently turned on to several of the projects Allison Smartt has been involved in, I became especially fascinated with MOM BABY GOD 3.0, of which Smartt was sound designer and producer. The crew of MOM BABY GOD 3.o sets the stage for what to expect in a performance with the following introduction:
Take a cupcake, put on a name tag, and prepare to be thrown into the world of the Christian Right, where sexual purity workshops and anti-abortion rallies are sandwiched between karaoke sing-alongs, Christian EDM raves and pro-life slumber parties. An immersive dark comedy about American girl culture in the right-wing, written and performed by Madeline Burrows. One is thrown into the world of the Christian Right, where sexual purity workshops and anti-abortion rallies are sandwiched between karaoke sing-alongs, Christian EDM raves and pro-life slumber parties.
It’s 2018 and the anti-abortion movement has a new sense of urgency. Teens 4 Life is video-blogging live from the Students for Life of America Conference, and right-wing teenagers are vying for popularity while preparing for political battle. Our tour guide is fourteen-year-old Destinee Grace Ramsey, ascending to prominence as the new It-Girl of the Christian Right while struggling to contain her crush on John Paul, a flirtatious Christian boy with blossoming Youtube stardom and a purity ring.
MOM BABY GOD toured nationally to sold-out houses from 2013-2015 and was the subject of a national right-wing smear campaign. In a newly expanded and updated version premiering at Forum Theatre and Single Carrot Theatre in March 2017, MOM BABY GOD takes us inside the right-wing’s youth training ground at a more urgent time than ever.
I reached out to Smartt about these endeavors with some sound-specific questions. What follows is our April 2017 email exchange [edited for length].
Ariel Taub (AT): What do you think of the voices Madeline Burrows [the writer and solo actor of MOM BABY GOD] uses in the piece? How important is the role of sound in creating the characters?
Allison Smartt (AS): I want to accurately represent Burrows’s use of voice in the show. For those who haven’t seen it, she’s not an impersonator or impressionist conjuring up voices for solely comedy’s sake. Since she is a woman portraying a wide range of ages and genders on stage and voice is a tool in a toolbox she uses to indicate a character shift. Madeline has a great sense of people’s natural speaking rhythms and an ability to incorporate bits of others’ unique vocal elements into the characters she portrays. Physicality is another tool. Sound cues are yet another…lighting, costume, staging, and so on.
I do think there’s something subversive about a queer woman voicing ideology and portraying people that inherently aim to repress her existence/identity/reproductive rights.
Many times, when actors are learning accents they have a cue line that helps them jump into that accent. Something that they can’t help but say in a southern, or Irish, or Canadian accent. In MOM BABY GOD, I think of my sound design in a similar way. The “I’m a Pro-Life Teen” theme is the most obvious example. It’s short and sweet, with a homemade flair and most importantly: it’s catchy. The audience learns to immediately associate that riff with Destinee (the host of “I’m a Pro-Life Teen”), so much so that I stop playing the full theme almost immediately, yet it still commands the laugh and upbeat response from the audience.
AT: Does [the impersonation and transformation of people on the opposite side of a controversial issues into] characters [mark them as] inherently mockable? (I asked Smartt about this specifically because of the reaction the show elicited from some people in the Pro-Life group.)
AS: Definitely not. I think the context and intention of the show really humanizes the people and movement that Madeline portrays. The show isn’t cruel or demeaning towards the people or movement – if anything, our audience has a lot of fun. But it is essential that Madeline portray the type of leaders in the movement (in any movement really) in a realistic, yet theatrical way. It’s a difficult needle to thread and think she does it really well. A preacher has a certain cadence – it’s mesmerizing, it’s uplifting. A certain type of teen girl is bubbly, dynamic. How does a gruff (some may say manly), galvanizing leader speak? It’s important the audience feel the unique draw of each character – and their voices are a large part of that draw.

Madeline Burrows in character in MOM BABY GOD (National Tour 2013-2015). Photos by Jessica Neria
AT: What sounds [and sound production] were used to help carry the performance [of MOM BABY GOD]? What role does sound have in making plays [and any performance] cohesive?
AS: Sound designing for theatre is a mix of many elements, from pre-show music, sound effects and original music to reinforcement, writing cues, and sound system design. For a lot of projects, I’m also my own sound engineer so I also implement the system designs and make sure everything functions and sounds tip top.
Each design process is a little different. If it’s a new work in development, like MOM BABY GOD and Mixed-Race Mixtape, I am involved in a different way than if I’m designing for a completed work (and designing for dance is a whole other thing). There are constants, however. I’m always asking myself, “Are my ideas supporting the work and its intentions?” I always try to be cognizant of self-indulgence. I may make something really, really cool but that ultimately, after hearing it in context and conversations with the other artistic team members, is obviously doing too much more than supporting the work. A music journalism professor I had used to say, “You have to shoot that puppy.” Meaning, cut the cue you really love for the benefit of the overall piece.
I like to set myself limitations to work within when starting a design. I find that narrowing my focus to say…music only performed on harmonica or sound effects generated only from modes of transportation, help get my creative juices flowing (Sidenote: why is that a phrase? It give me the creeps)[. . .]I may relinquish these limitations later after they’ve helped me launch into creating a sonic character that feels complex, interesting, and fun.
AT: The show is described as being comprised of, “karaoke sing-alongs, Christian EDM raves and pro-life slumber parties,” each of these has its own distinct associations, how do “sing alongs” and “raves” and our connotations with those things add to the pieces?

Madeline Burrows in character in MOM BABY GOD (National Tour 2013-2015). Photos by Jessica Neria
AS: Since sound is subjective, the associations that you make with karaoke sing-alongs are probably slightly different from what I associated with karaoke sing-alongs. You may think karaoke sing-along = a group of drunk BFFs belting Mariah Carey after a long day of work. I may think karaoke sing-alongs = middle aged men and women shoulder to shoulder in a dive bar singing “Friends In Low Places” while clinking their glasses of whiskey and draft beer. The similarity in those two scenarios is people singing along to something, but the character and feeling of each image is very different. You bring that context with you as you read the description of the show and given the challenging themes of the show, this is a real draw for people usually resistant to solo and/or political theatre. The way the description is written and what it highlights intentionally invites the audience to feel invited, excited, and maybe strangely upbeat about going to see a show about reproductive rights.
As a sound designer and theatre artist, one of my favorite moments is when the audience collectively readjusts their idea of a karaoke sing-along to the experience we create for them in the show. I feel everyone silently say, “Oh, this is not what I expected, but I love it,” or “This is exactly what I imagined!” or “I am so uncomfortable but I’m going with it.” I think the marketing of the show does a great job creating excited curiosity, and the show itself harnesses that and morphs it into confused excitement and surprise (reviewers articulate this phenomenon much better that I could).
AT: In this video the intentionally black screen feels like deep space. What sounds [and techniques] are being used? Are we on a train, a space ship, in a Church? What can you [tell us] about this piece?
AS: There are so many different elements in this cue…it’s one of my favorites. This cue is lead in and background to Destinee’s first experience with sexual pleasure. Not to give too much away: She falls asleep and has a sex dream about Justin Bieber. I compiled a bunch of sounds that are anticipatory: a rocket launch, a train pulling into a station, a remix/slowed down version of a Bieber track. These lead into sounds that feel more harsh: alarm clocks, crumpling paper…I also wanted to translate the feeling of being woken up abruptly from a really pleasant dream…like you were being ripped out of heaven or something. It was important to reassociate for Destinee and the audience, sounds that had previously brought joy with this very confusing and painful moment, so it ends with heartbeats and church bells.
I shoved the entire arc of the show into this one sound cue. And Madeline and Kathleen let me and I love them for that.

from madelineburrows.com
AT: What do individuals bring of themselves when they listen to music? How is music a way of entering conversations otherwise avoided?
AS: The answer to this question is deeper than I can articulate but I’ll try.
Talking about bias, race, class, even in MOM BABY GOD introducing a pro-life video blog – broaching these topics are made easier and more interesting through music. Why? I think it’s because you are giving the listener multiple threads from which to sew their own tapestry…their own understanding of the thing. The changing emotions in a score, multiplicity of lyrical meaning, tempo, stage presence, on and on. If you were to just present a lecture on any one of those topics, the messages feel too stark, too heavy to be absorbed (especially to be absorbed by people who don’t already agree with the lecture or are approaching that idea for the first time). Put them to music and suddenly you open up people’s hearts.

Post- Mixed-Race Mixtape love, William Paterson University, 2016 Photo credit: Allison Smartt
As a sound designer, I have to be conscious of what people bring to their listening experience, but can’t let this rule my every decision. The most obvious example is when faced with the request to use popular music. Take maybe one of the most overused classics of the 20th century, “Hallelujah” by Leonard Cohen. If you felt an urge just now to stop reading this interview because you really love that song and how dare I naysay “Hallelujah” – my point has been made. Songs can evoke strong reactions. If you heard “Hallelujah” for the first time while seeing the Northern Lights (which would arguably be pretty epic), then you associate that memory and those emotions with that song. When a designer uses popular music in their design, this is a reality you have to think hard about.

Cassette By David Millan on Flickr.
It’s similar with sound effects. For Mixed-Race Mixtape, Fig wanted to start the show with the sound of a cassette tape being loaded into a deck and played. While I understood why he wanted that sound cue, I had to disagree. Our target demographic are of an age where they may have never seen or used a cassette tape before – and using this sound effect wouldn’t elicit the nostalgic reaction he was hoping for.
Regarding how deeply the show moves people, I give all the credit to Fig’s lyrics and the entire casts’ performance, as well as the construction of the songs by the musicians and composers. As well as to Jorrell, our director, who has focused the intention of all these elements to coalesce very effectively. The cast puts a lot of emotion and energy into their performances and when people are genuine and earnest on stage, audiences can sense that and are deeply engaged.
I do a lot of work in the dance world and have come to understand how essential music and movement are to the human experience. We’ve always made music and moved our bodies and there is something deeply grounding and joining about collective listening and movement – even if it’s just tapping your fingers and toes.
AT: How did you and the other artists involved come up with the name/ idea for Mixed-Race Mixtape? How did the Mixed-Race Mixtape come about?
AS: Mixed-Race Mixtape is the brainchild of writer/performer Andrew “Fig” Figueroa. I’ll let him tell the story.
Andrew “Fig” Figueroa, Hip-Hop artist, theatre maker, and arts educator from Southern California
A mixtape is a collection of music from various artists and genres on one tape, CD or playlist. In Hip-Hop, a mixtape is a rapper’s first attempt to show the world there skills and who they are, more often than not, performing original lyrics over sampled/borrowed instrumentals that compliment their style and vision. The show is about “mixed” identity and I mean, I’m a rapper so thank God “Mixed-Race” rhymed with “Mixtape.”
The show grew from my desire to tell my story/help myself make sense of growing up in a confusing, ambiguous, and colorful culture. I began writing a series of raps and monologues about my family, community and youth and slowly it formed into something cohesive.

AT: I love the quote, “the conversation about race in America is one sided and missing discussions of how class and race are connected and how multiple identities can exist in one person,” how does Mixed-Race Mixtape fill in these gaps?
AS: Mixed-Race Mixtape is an alternative narrative that is complex, personal, and authentic. In America, our ideas about race largely oscillate between White and Black. MRMT is alternative because it tells the story of someone who sits in the grey area of Americans’ concept of race and dispels the racist subtext that middle class America belongs to White people. Because these grey areas are illuminated, I believe a wide variety of people are able to find connections with the story.
AT: In this video people discuss the connection they [felt to the music and performance] even if they weren’t expecting to. What do you think is responsible for sound connecting and moving people from different backgrounds? Why are there the assumptions about the event that there are, that they wouldn’t connect to the Hip Hop or that there would be “good vibes.”
AS: Some people do feel uncertain that they’d be able to connect with the show because it’s a “hip-hop” show. When they see it though, it’s obvious that it extends beyond the bounds of what they imagine a hip-hop show to be. And while I’ve never had someone say they were disappointed or unmoved by the show, I have had people say they couldn’t understand the words. And a lot of times they want to blame that on the reinforcement.
I’d argue that the people who don’t understand the lyrics of MRMT are often the same ones who were trepidatious to begin with, because I think hip-hop is not a genre they have practice listening to. I had to practice really actively listening to rap to train my brain to process words, word play, metaphor, etc. as fast as rap can transmit them. Fig, an experienced hip-hop listener and artist amazes me with how fast he can understand lyrics on the first listen. I’m still learning. And the fact is, it’s not a one and done thing. You have to listen to rap more than once to get all the nuances the artists wrote in. And this extends to hip-hop music, sans lyrics. I miss so many really clever, artful remixes, samples, and references on the first listen. This is one of the reasons we released an EP of some of the songs from the show (and are in the process of recording a full album).
.
The theatre experience obviously provides a tremendously moving experience for the audience, but there’s more to be extracted from the music and lyrics than can be transmitted in one live performance.
AT: What future plans do you have for projects? You mentioned utilizing sounds from protests? How is sound important in protest? What stands out to you about what you recorded?
AS: I have only the vaguest idea of a future project. I participate in a lot of rallies and marches for causes across the spectrum of human rights. At a really basic level, it feels really good to get together with like minded people and shout your frustrations, hopes, and fears into the world for others to hear. I’m interested in translating this catharsis to people who are wary of protests/hate them/don’t understand them. So I’ve started with my iPhone. I record clever chants I’ve never heard, or try to capture the inevitable moment in a large crowd when the front changes the chant and it works its way to the back.
.
I record marching through different spaces…how does it sound when we’re in a tunnel versus in a park or inside a building? I’m not sure where these recordings will lead me, but I felt it was important to take them.
—

REWIND! . . .If you liked this post, you may also dig:
Beyond the Grandiose and the Seductive: Marie Thompson on Noise
Moonlight’s Orchestral Manoeuvers: A duet by Shakira Holt and Christopher Chien
Aural Guidings: The Scores of Ana Carvalho and Live Video’s Relation to Sound
Share this:

Listen to the Sound of My Voice

Betrayal
I first realized there was a problem with my voice on the first day of tenth grade English class. The teacher, Mrs. C, had a formidable reputation of strictness and high standards. She had us sit in alphabetical order row after row, and then insisted on calling roll aloud while she sat at her desk. Each name emerged as both a command and a threat in her firm voice.
“Kelly Barfield?”
“Here,” I mumbled quietly. I was a Honor Roll student with consistent good grades, all A’s and one B on each report card, yet I was shy and softspoken in classes. This was an excellent way to make teachers amiable but largely go unnoticed. The softness of my voice made me less visible and less recognizable.
Mrs. C repeated my name. Caught off guard, I repeated “here” a little more loudly. She rose to her feet to get a better look at me. I knew what she saw: a petite girl with long ash blonde hair, big brown eyes, and overalls embroidered with white daisies on the bib. When her gaze finally met mine, Mrs. C frowned at me and cleared her throat loudly. I curled into my desk, hoping to disappear.

“Lincoln High School 9-16-2007 008” by Flickr user Paul Horst, CC BY-NC 2.0
“Miss Barfield, did you hear me call your name twice? In this class, when I call roll, you respond.” I gave a quick nod, but Mrs. C wasn’t finished: “We use our strong voices in here, not our girly, breathy ones.” My cheeks flushed red while Mrs. C droned on about confidence and classroom expectations.
“Do you understand me?”
I stammered a “yes.” Mrs. C turned her attention back to the roll call. Her harsh words rang in my ears. I sank low in my chair, humiliated and angry. I couldn’t help that I sounded girly: I was, in fact, a girl. This was the way my voice sounded. It was not an attempt to sound like the dumb blonde she appeared to think I was.
That day I decided that I would never speak up in her class. Forget the Honor Roll. If the sound of my voice was such a problem, then my mouth would remain firmly shut in this class and all of my others. I would never speak up again.

“Listen” by Flickr user lambda_x, CC BY-ND 2.0
My vow to stop speaking lived a short life. I enjoyed Mrs. C’s serious fixation on diagramming sentences and her attempts to show sophomores that literature offered ideas and worlds we didn’t quite know. At first, I spoke up with hesitation and fear of the inevitable dismissal, but I continued to speak. Becoming louder became my method to seem confident, even when I felt anything but.
Throughout high school, my voice emerged again and again as a problem. Despite the increased volume, my voice still sounded tremulous, squeaky, hesitant, and shrill to my own ears. Other girls had these steady, warm voices that encouraged others to listen to them. Some had higher voices that were melodic and lovely. I craved a lower, more resonant voice, but I was stuck with what I had. In drama club, our director scolded me with increasing frustration about my tendency to end my lines in the form of a question. My nerves materialized as upspeak. The more he yelled at me, the more pronounced the habit became. He eventually gave up, disgusted by my inability to control my vocal patterns.

By Dvortygirl, Mysid [GFDL (http://www.gnu.org/copyleft/fdl.html) or CC-BY-SA-3.0 (http://creativecommons.org/licenses/by-sa/3.0/)%5D, via Wikimedia Commons
Meanwhile, at a big state university in my native Florida, I learned quickly that a Southern accent marks you as a dumb redneck from some rural town that no one had heard of. Students in my classes asked me to say particular words and then giggled at my pronunciations. “You sound like a Southern belle,” one student noted. This was not really a compliment. According to my peers, Southern belles didn’t have a place in the classroom. Southern belles didn’t easily match up with “college student. As a working-class girl from a trailer park, I learned that I surely didn’t sound like a college student should. I worked desperately to rid myself of any hint of twang. I dropped y’all and reckon.
I listened carefully to how other students talked. I mimicked their speech patterns by being more abrupt and deadpan, slowly killing my drawl. When I finally removed all traces of my hometown from my voice, my friends both from home and from college explained that now I sounded like an extra from Clueless. My voice was all Valley girl. I was smarter, they noted with humor, than I sounded and looked. My voice now alternated between high-pitched and fried. Occasionally, it would squeak or crack. I thought I sounded too feminine and too much like an airhead, even when I avidly tried not to. I began to hate the sound of my voice.
My voice betrayed me because it refused to sound like I thought I needed it to. It refused to sound like anyone but me.
When I started teaching and receiving student evaluations, my voice became the target for students to express their displeasure with the course and me. According to students, my voice was too high and grating. Screechy, even: one student said my voice was at a frequency that only bats could hear. In every set of evaluations, a handful of students declared that I sounded annoying. This experience, however, was not something I alone faced. Women professors and lecturers routinely face gender bias in teaching evaluations. According to the interactive chart, Gender Language in Teaching Evaluations, female professors are more likely to be called “annoying” than their male counterparts in all 25 disciplines evaluated. The sound of my voice was only part of the problem, but I couldn’t help but wonder if how I sounded was an obstacle to what I was teaching them.
Once again, I tried to fix my problematic voice. I lowered it. I listened to NPR hosts in my search for a smooth, accentless, and educated sound, and I attempted to create a sound more like them. I practiced pronouncing words like they did. I modulated my volume. I paid careful attention to the length of my vowels. I avoided my natural drawl. None of my attempts seemed to last. Some days, I dreaded lecturing in my courses. I had to speak, but I didn’t want to. I wondered if my students listened, but I wondered more about what they heard.
Sound
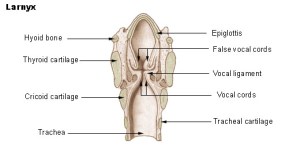
Public Domain, https://commons.wikimedia.org/w/index.php?curid=1393933
The sound of your voice is a distinct trait of each human being, created by your lungs, the length of your vocal cords, and your larnyx. Your lungs provide the air pressure to vibrate your vocal cords. The muscles of your larnyx adjust both the length and the tension of the cords to provide pitch and tone. Your voice is how you sound beyond the resonances that you hear when you speak. It is dependent on both the length and thickness of the vocal cords. Biology determines your pitch and tone. Your pitch is a result of the rate at which your vocal cords vibrate. The faster the rate, the higher your voice. Women tend to have shorter cords than men, which makes our voices higher.
Emotion also alters pitch. Fright, excitement, and nervousness all make your voice sound higher. Nerves would make a teenage girl have an even higher voice than she normally would. Her anxious adult self would too. Her voice would seem tinny because her larnyx clenched her vocal cords tight. Perhaps this is the only sound she can make. Perhaps she is trying to communicate with bats because they at least would attempt to listen.
Biology, the body, gives us the voices we have. Biology doesn’t care if we like the ways in which we sound. Biology might not care, but culture is the real asshole. Culture marks a voice as weak, grating, shrill, or hard to listen to.

“Speak” by Flickr user Megara Tegal, CC BY-NC-ND 2.0
My attempts to change my voice were always destined to fail. I fought against my body and lost. I couldn’t have won even if I tried harder. My vocal cords are determined that my voice would be high, so it is. The culture around me, however, taught me to hate myself for it. Voice and body seem to cast aspersions on intelligence or credentials. It’s the routineness of it all that wears on me. I expect the reactions now.
I wonder if I’m drawn to the quietness of writing because I don’t have to hear myself speak. I crave the silence while simultaneously bristling at it. Why is my voice a problem that I must resolve to placate others? How can I get others to hear me and not the stereotypes that have chased me for years?
Fury
My silence has become fruitful. The words I don’t say appear on the page of an essay, a post, or an article. I type them up. I read aloud what I first refused to say. I wince as I hear my voice reciting my words. I listen carefully to the cadence and tone. This separation of words and voice is why writing appeals to me. I can say what I want to say without the sound of my voice causing things to go awry.
People can read what I write, yet they can’t dismiss my voice by its sound. Instead, they read what I have to say. They imagine my voice; my actual sound can’t bother them. But, they aren’t really hearing me. They just have my words on the page. They don’t know how I wrap the sound around them. They don’t hear me.
Rebecca Solnit, in “Men Explain Things to Me,” writes “Credibility is a basic survival tool.” Solnit continues that to be credible is to be audible. We must be heard to for our credibility to be realized. This right to speak is crucial to Solnit. Too many women have been silenced. Too many men refuse to listen. To speak is essential “to survival, to dignity, and to liberty.”

“Listen” by Flickr user Emily Flores, CC BY-ND 2.0
I agree with her. I underline her words. I say them aloud. The more I engage with her argument, the more I worry. What about our right to be heard? When women speak, do people listen? Women can speak and speak and speak and never be heard. Our words dismissed because of gender and sound. Being able to speak is not enough, we need to be heard.
We get caught up in the power of speaking, but we forget that there’s power in listening too. Listening is political. It is act of compassion and empathy. When we listen, we make space for other people, their stories, their voices. We grant them room to be. We let them inhabit our world, and for a moment, we inhabit theirs. Yes, we need to be able to speak, but the world also needs to be ready to listen us.
We need to be listened to. Will you hear me? Will you hear us? Will you grant us room to be?
When I think of times I’ve been silenced and of the times I haven’t been heard, I feel the sharp pain of exclusion, of realizing that my personhood didn’t matter because of how I sounded. I remember the burning anger because no one would listen. I think of the way that silence and the policing of how I sound made me feel small, unimportant, or disposable. As a teenager, a college student, and a grown woman, I wanted to be heard, but couldn’t figure out exactly how to make that happen. I blamed my voice for a problem that wasn’t its fault. My voice wasn’t the problem at all; the problem was the failure of others to listen.

“listen” by Flickr user Jay Morrison, CC BY-NC-ND 2.0
Loss
While writing this essay on my voice, I almost lost mine, not once but twice. I caught a cold and then the flu. My throat ached, and I found it difficult to swallow. A stuffy nose gave my voice a muted quality, but then, it sounded lower and huskier. I could hear the congestion disrupting the timber of my words. My voice blipped in and out as I were radio finding and losing signal. It hurt to speak, so I was quiet.
“You sound awful,” my husband said in passing. He was right. My voice sounded unfamiliar and monstrous. I tested out this version of my voice. It was rougher and almost masculine. I can’t decide if this is the stronger, more authoritative voice I wanted all along or some crude mockery of what I can never really have. I couldn’t sing along with my favorite songs because my voice breaks at the higher register. I wheezed out words. I croaked my way through conversations. “Are you sick?” my daughter asked, “You don’t sound like you.”
Her passing comment stuck with me. You don’t sound like you. Suddenly, I missed the sound of my voice. I disliked this alien version of it. I craved that problematic voice that I’ve tried to change over the years. I wanted my voice to return.
After twenty years, I decided to acknowledge the sound of me, even if others don’t. I want to be heard, and I’m done trying to make anyone listen.
—
Featured image: “Speak” by Flickr user Ash Zing, CC BY-NC-ND 2.0
—
Kelly Baker is a freelance writer with a religious studies PhD who covers religion, higher education, gender, labor, motherhood, and popular culture. She’s also an essayist, historian, and reporter. You can find her writing at the Chronicle for Higher Education‘s Vitae project, Women in Higher Education, Killing the Buddha, and Sacred Matters. She’s also written for The Atlantic, Bearings, The Rumpus, The Manifest-Station, Religion Dispatches, Christian Century’s Then & Now, Washington Post, and Brain, Child. She’s on Twitter at @kelly_j_baker and at her website.
—
REWIND!…If you liked this post, you may also dig:
Vocal Gender and the Gendered Soundscape: At the Intersection of Gender Studies and Sound Studies — Christine Ehrick
On Sound and Pleasure: Meditations on the Human Voice– Yvon Bonefant
As Loud As I Want To Be: Gender, Loudness, and Respectability Politics — Liana Silva
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments