
“Hey Google, Talk Like Issa”: Black Voiced Digital Assistants and the Reshaping of Racial Labor

.

In summer 2021, sound artist, engineer, musician, and educator Johann Diedrick convened a panel at the intersection of racial bias, listening, and AI technology at Pioneerworks in Brooklyn, NY. Diedrick, 2021 Mozilla Creative Media award recipient and creator of such works as Dark Matters, is currently working on identifying the origins of racial bias in voice interface systems. Dark Matters, according to Squeaky Wheel, “exposes the absence of Black speech in the datasets used to train voice interface systems in consumer artificial intelligence products such as Alexa and Siri. Utilizing 3D modeling, sound, and storytelling, the project challenges our communities to grapple with racism and inequity through speech and the spoken word, and how AI systems underserve Black communities.” And now, he’s working with SO! as guest editor for this series (along with ed-in-chief JS!). It kicked off with Amina Abbas-Nazari’s post, helping us to understand how Speech AI systems operate from a very limiting set of assumptions about the human voice. Today Golden Owens explored what happens when companies sell Black voices along with their Intelligent Virtual Assistants. Tune in for a deep historical dive into the racialized sound of servitude in America. Even though corporations aren’t trying to hear this absolutely critical information–or Black users in general–they better listen up. –JS
—
In October 2019, Google released an ad for their Google Assistant (GA), an intelligent virtual assistant (IVA) that initially debuted in 2016. As revealed by onscreen text and the video’s caption, the ad’s announced that the GA would soon have a new celebrity voice. The ten-second promotion includes a soundbite from this unseen celebrity—who states: “You can still call me your Google Assistant. Now I just sound extra fly”— followed by audio of the speaker’s laughter, a white screen, the GA logo, and a written question: “Can you guess who it is?”
Consumers quickly speculated about the person behind the voice, with many posting their guesses on Reddit. The earliest comments named Tiffany Haddish, Lizzo, and Issa Rae as prospects, with other users affirming these guesses. These women were considered the most popular contenders: two articles written about the new GA voice cited the Reddit post, with one calling these women Redditors’ most popular guesses and the other naming only them as users’ desired choices. Those who guessed Rae were proven correct. One day after the ad, Google released a longer promo revealing her as the GA’s new voice, including footage of Rae recording responses for the assistant. The ad ends with Rae repeating the “extra fly” line from the initial promo, smiling into the camera.
Google’s addition of Rae as an IVA voice option is one of several recent examples of Black people’s voices employed in this manner. Importantly, this trend toward Black-voiced IVAs deviates from the pre-established standard of these digital aides. While there are many voice options available, the default voices for IVAs are white female voices with flat dialects. This shift toward Black American voices is notable not only because of conversations about inclusion—with some Black users saying they feel more represented by these new voices—but because this influx of Black voices marks a spiritual return to the historical employment of Black people as service-providing, labor-performing entities in the United States, thus subliminally reinforcing historical biases about Black people as uniquely suited for performing this type of work.
Marketed as labor-saving devices, IVAs are programmed to assist with cooking and grocery shopping, transmit messages and reminders, and provide entertainment, among other tasks. Since the late 2010s they have also been able to operate other technologies within users’ homes: Alexa, for example, can control Roomba robotic vacuums; IVA-compatible smart plugs or smart home devices enable IVAs to control lights, locks, thermostats, and other such apparatuses. Behaviorally, IVAs are designed and expected to be on-call at all times, but not to speak or act out of turn—with programmers often directed to ensure these aides are relatable, reliable, trustworthy, and unobtrusive.

Far from operating in a vacuum, IVAs eerily evoke the presence of and parameters set for enslaved workers and domestic servants in the U.S.—many of whom have historically been Black American women. Like IVAs, Black women servants cooked, cleaned, entertained children, and otherwise served their (predominantly white) employers, themselves operating as labor-saving devices through their performance of these labors. Employers similarly expected these women to be ever-available, occupy specific areas of the home, and obey all requests and demands—and were unsettled if not infuriated when maids did not behave according to their expectations.
White women being the default voices of IVAs has somewhat obfuscated the degree to which these aides have re-embodied and replaced the Black servants who once predominantly executed this work, but incorporating Black voices into these roles removes this veil, symbolically re-implementing Black people as labor-performing entities by having them operate as the virtual assistants who now perform much of the labor Black workers historically performed. Enabling Black people to be used as IVAs thus re-aligns Black beings with the performance of service and labor.

While Black women were far from the only demographic conscripted into domestic labor, by the 1920s they comprised a “permanent pool of servants” throughout the country, due largely to the egress of white American and immigrant women from domestic service into fields that excluded Black women (183). Black women’s prominence in domestic service was heavily reflected in early U.S. media, which overwhelmingly portrayed domestic servants not just as Black women, but as Black Mammies—domestic servant archetypes originally created to promote the myth that Black women “were contented, even happy as slaves.” Characters like Gone with the Wind’s “Mammy” pulled both from then-current associations of Black women with domestic labor and from white nostalgia for the Antebellum era, and specifically for the archetypal Mammy—marking Black women as idealized labor-performing domestics operating in service of white employers. These on-screen servants were “always around when the boss needed them…[and] always ready to lend a helping hand when times were tough” (36). Historian Donald Bogle dubbed this era of Hollywood the “Age of the Negro Servant,” referenced in this reel from the New York Times.
—-
.
Cinema and television merely built from years of audible racism on the radio—America’s most prominent form of in-home entertainment in the first half of the 20th century—where Black actors also played largely servant and maid roles that demanded they speak in “distorted dialect, exaggerated intonation, rhythmic speech cadences, and particular musical instruments” in order to appear at all (143). This white-contrived portrayal of Black people is known as “Blackvoice,” and essentially functions as “the minstrel show boiled down to pure aurality” (14). These performances allowed familiar ideals of and narratives about Blackness to be communicated and recirculated on a national scale, even without the presence of Black bodies. Labor-performing Black characters like Beulah, Molasses and January, Aunt Jemima, and Amos and Andy were prominent in the Golden Age of Radio, all initially voiced by white actors. In fact, Aunt Jemima’s print advertising was just as dependent on stereotypical representations of her voice as it was on visual “Mammy” imagery.

When Black actors broke through white exclusion on the airwaves, many took over roles once voiced by white men and/or were forced by white radio producers and scriptwriters to “‘talk as white people believed Negroes talked’” so that white audiences could discern them as Black (371). This continuous realignment undoubtedly informs contemporary ideas of labor, labor performance, and laboring bodies, further promoted by the sudden influx of Black voice assistants in 2019.
Specifically, these similarities demonstrate that contemporary IVAs are intrinsically haunted by Black women slaves and servants: built in accordance with and thus inevitably evoking these laborers in their positioning, programming, and task performance. Further facilitating this alignment is the fact that advertisements for Black-voiced IVAs purposefully link well-known Black bodies in conjunction with their Black voices. Excepting Apple’s Black-sounding voice options for Siri, all of the Black IVA voice options since 2019 have belonged to prominent Black American celebrities. Prior to Issa Rae, GA users could employ John Legend as their digital aide (April 2019 until March 2020). Samuel L. Jackson became the first celebrity voice option for Amazon’s Alexa in December 2019, followed by Shaquille O’Neal in July 2021.
The ads for Black-voiced IVAs thus link these disembodied aides not just to Black bodies, but to specific Black bodies as a sales tactic—bodies which signify particular images and embodiments of Blackness. The Samuel L. Jackson Alexa ad utilizes close-ups of Jackson recording lines for the IVA and of Echo speakers with Jackson’s voice emitting from them in response to users. John Legend is physically absent from the ad announcing him as the GA; however, his celebrity wife directs the GA to sing for her instead, after which she states that it is “just like the real John”—thus linking Legend’s body to the GA even without his onscreen presence. Amazon has even explicitly explored the connection between the Black-voiced IVA and the Black body, releasing a 2021 commercial called “Alexa’s Body” that saw Alexa voiced and physically embodied by Michael B. Jordan—with the main character in the commercial insinuating that he is the ideal vessel for Alexa.
By aligning these bodies with, and having them act as, labor-performing devices in service of consumers, these advertisements both re-align Blackness with labor and illuminate how these devices were always already haunted by laboring Black bodies—and especially, given the demographics of the bodies who most performed the types of labors IVAs now execute, laboring Black women’s bodies. That the majority of the Black celebrities employed as Black IVA voices are men suggests some awareness of and attempt to distance from this history and implicit haunting—an effort which itself exposes and illuminates the degree to which this haunting exists.
In some cases, the Black people lending their voices to these IVAs also speak in a way that sonically suggests Blackness: Issa Rae’s “Now I’m just extra fly,” for example, incorporates Black American slang through the use of the word “fly. As part of African American Vernacular English (AAVE), the term “fly” dates back to the 1970s and denotes coolness, attractiveness, and fashionableness. Because of its inclusion in Hip Hop, which has become the dominant music genre in the United States, the term, its meaning, and its racial origins are widely known amongst consumers. By using the word “fly,” Rae nods not only at these qualities but also at her own Blackness in a manner that is recognizable to a mainstream American audience. Due in part to Hip Hop’s popularity, U.S.-based media outlets, corporations, and individuals of varying races and ethnicities regularly appropriate AAVE and Black slang terms, often without regard for the culture that created them or the vernacular they stem from. The ad preceding Issa Rae’s revelation as the GA specifically invited users to align the voice with a celebrity body, and users’ predominant claims that the voice was a Black woman’s suggest that something about the voice conjured Blackness and the Black female body.

This racial marking was also likely facilitated by how people naturally listen and respond to voices. As Nina Sun Eidsheim notes in The Race of Sound, “voices heard are ultimately identified, recognized, and named by listeners at large. In hearing a voice, one also brings forth a series of assumptions about the nature of voice” (12). This series of assumptions, Eidsheim asserts in “The Voice as Action,” is inflected by the “multisensory context” surrounding a given voice, i.e., “a composite of visual, textural, discursive, and other kinds of information” (9). While we imagine our impressions of voices as uniquely meaningful, “we cannot but perceive [them] through filters generated by our own preconceptions” (10). As a result, listening is never a neutral or truly objective practice.
For many consumers, these filters are informed by what Jennifer Lynn Stoever terms the sonic color line, “a socially constructed boundary that racially codes sonic phenomena such as vocal timbre, accents, and musical tones” (11). Where the racial color line allows white people to separate themselves from Black people on the basis of visual and behavioral differences, the sonic color line allows people “to construct and discern racial identities based on voices, sounds, and particular soundscapes” and to assign nonwhite voices with “differential cultural, social, and political value” (11). In the U.S., the sonic color line operates in tandem with the American listening ear, which “normalizes the aural tastes and standards of white elite masculinity as the singular way to interpret sonic information” (13) and therefore marks-as-Other not only the voices and bodies of Black people, but also those of non-males and the non-elite.

Ironically, the very listening practices which make consumers register particular voices and vocal qualities as Black also make Black voices inaccessible to Alexa and other IVAs. Scholarship on Automated Speech Recognition (ASR) systems and Speech AI observes that many Black users find it necessary to code-switch when speaking to IVAs, as the devices fail to comprehend their linguistic specificities. A study by Christina N. Harrington et al. in which Black elders used the Google Home to seek health information discovered that “participants felt that Google Home struggles to understand their communication style (e.g., diction or accent) and language (e.g., dialect) specifically due to the device being based on Standard English” (15). To address these struggles, participants switched to Standard American English (SAE), eliminating informal contractions and changing their tone and verbiage so that the GA would understand them. As one of the study’s participants states,
You do have to change your words. Yes. You do have to change your diction and yes, you have to use… It cannot be an exotic name or a name that’s out of the Caucasian round. …You have to be very clear with the English language. No ebonic (15).
This incomprehension extends to Black Americans of all ages, and to other IVAs. A study by Allison Koenecke et al. on ASR systems produced by Amazon, Google, IBM, Microsoft and Apple discovered that these entities had a harder time accurately transcribing Black speech than white speech, producing “an average word error rate (WER) of 0.35 for black speakers compared with 0.19 for white speakers.” (7684). A study by Zion Mengesha et al. on the impact of these errors on Black Americans—which included participants from different regions with a range of ages, genders, socioeconomic backgrounds and education-levels—discovered that many felt frustrated and othered by these mistakes, and felt further pressure to code-switch so that they would not be misunderstood. Koenecke et al. concluded that ASR systems could not understand the “phonological, phonetic, or prosodic characteristics of” AAVE (7687), and that this ignorance would make the use of these technologies more difficult for Black users—a sentiment that was echoed by participants in the study conducted by Mengesha et al., most of whom marked the technology as working better for white and/or SAE speakers (5).
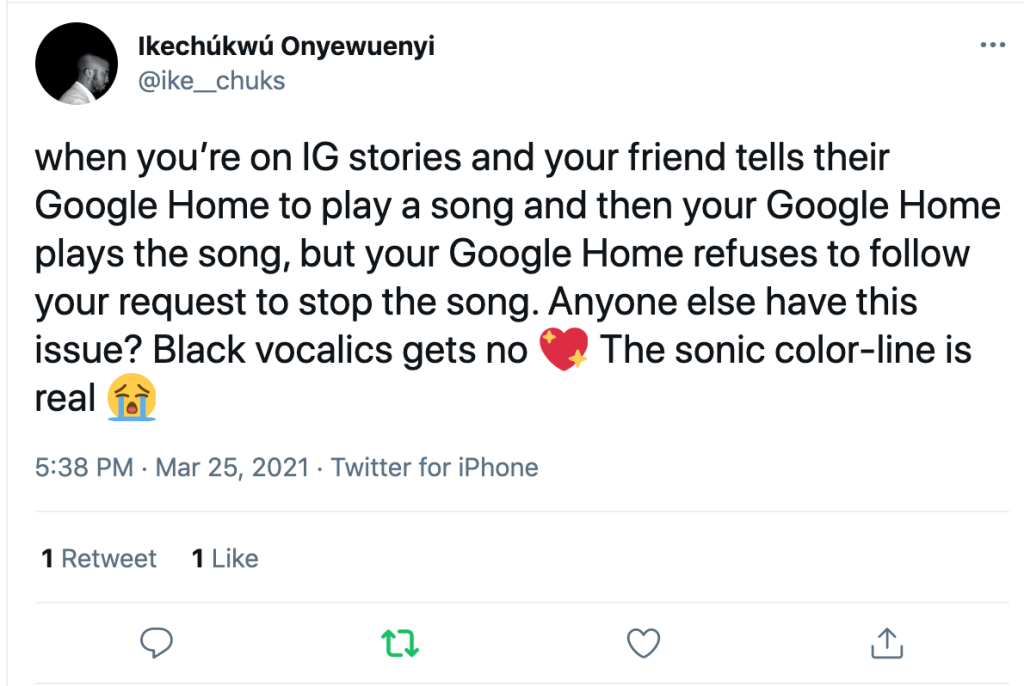
The speech recognition errors these technologies demonstrate—which also extend to speakers in other racial and ethnic groups—illuminate the reality that despite including Black voices as IVAs, these assistant technologies are not truly built for Black people, or for any person that does not speak Standard American English. And where AAVE is largely associated with Blackness, SAE is predominantly associated with whiteness: as a dialect widely perceived to be “lacking any distinctly regional, ethnic, or socioeconomic characteristics,” it is recognized as being “spoken by the majority group or the socially advantaged group” in the United States—both groups which are solely or primarily composed of white people. SAE is so identified with whiteness that Black people who only speak Standard English are often told that they sound and/or “talk” white, and Black people who deliberately invoke SAE in professional and/or interracial settings (i.e., code switching) are described as “talking white” or using their “white voice” when doing so. That IVAs and other ASR systems have such trouble understanding AAVE and other non-standard English dialects suggests that these technologies were not designed to understand any dialect other than SAE—and thus, given SAE’s strong identification with whiteness, were designed specifically to assist, understand, and speak to white users.
Writing on this phenomena as a woman with a non-standard accent, Sinduja Rangarajan highlights in “Hey Siri—Why Don’t You Understand More People Like Me?” that none of the IVAs currently on the market offer any American dialect that is not SAE. And while users can change their IVA’s accents, they are limited to Standard American, British, Irish, Australian, Indian, and South African—which Rangarajan rightly highlights as revealing who the IVAs think they are talking to, rather than who their user actually is. That most of these accents belong to Western, predominantly white countries (or to countries once colonized by white imperialists) strongly suggests that these devices are programmed to speak to—and perform labor for—white consumers specifically.

When considering the primary imagined and target users of IVAs, the sudden influx of Black-voiced IVAs becomes particularly insidious. Though they may indeed make some Black users feel more represented, cultivating this representation is merely a byproduct of their actual purpose. Because these technologies are not built for Black consumers, Black-voiced IVAs are meant to appeal not to Black users, but to white ones. Rae, Jackson, and the other Black celebrity voices may provide a much-needed variety in the types of voices applied to IVAs, but they primarily operate as “further examples of technology companies using Black voices to entertain white consumers while ignoring Black consumers.” Black-voiced assistants, after all, no better understand Black vernacular English than any of the other voice options for IVAs, a reality marking Black speech patterns as enjoyable but not legitimate.
By excluding Black consumers, the companies behind these IVAs insinuate that Blackness is only acceptable and worthy of consideration when operating in service of whiteness. Where Black people as consumers have been delegitimized and disregarded, Black voices as labor-saving assistants have been welcomed and deemed profitable—a reality which further emphasizes how historical constructions of Black people as labor-performing devices haunts these contemporary technologies. Tech companies reinforce historical positionings of white people as ideal consumers and Black people as consumable products—repeating historical demarcations of Blackness and whiteness in the present.
In imagining the futures of IVAs, the companies behind them would need to reconsider how they interact—or fail to interact—with Black users. Both Samuel L. Jackson and Shaquille O’Neal, the last of the Black-celebrity-voiced IVAs still currently available to users, will be removed as Alexa voice options by September 2023, presenting an opportunity for these companies to divest. Whether or not the brands behind these IVAs take this initiative, consumers themselves can be critical of how AI technologies continue to reestablish hierarchical systems, of their own interactions with these devices, and of who these technologies are truly made for. In being critical, we can perhaps begin to envision alternative, reparative modes of AI technology—modes that serve and support more than one kind of user.
—
Featured Image: Issa Rae gif from the 2017 Golden Globes
—
Golden Marie Owens is a PhD candidate in the Screen Cultures program at Northwestern University. Her research interests include representations of race and gender in American media and popular culture, artificial intelligence, and racialized sounds. Her doctoral dissertation, “Mechanical Maids: Digital Assistants, Domestic Spaces, and the Spectre(s) of Black Women’s
Labor,” examines how intelligent virtual assistants such as Apple’s Siri and Amazon’s Alexa evoke and are haunted by Black women slaves, servants, and houseworkers in the United States. In her time at Northwestern, she has had internal fellowships through the Office of Fellowships and the Alice Kaplan Institute for the Humanities. She currently holds an MMUF Dissertation Grant through the Institute for Citizens and Scholars and Ford Dissertation Fellowship through the National Academy for Sciences, Engineering, and Medicine.
—

REWIND! . . .If you liked this post, you may also dig:
Beyond the Every Day: Vocal Potential in AI Mediated Communication –Amina Abbas-Nazari
Voice as Ecology: Voice Donation, Materiality, Identity–Steph Ceraso
Mr. and Mrs. Talking Machine: The Euphonia, the Phonograph, and the Gendering of Nineteenth Century Mechanical Speech – J. Martin Vest
Echo and the Chorus of Female Machines—AO Roberts
Black Excellence on the Airwaves: Nora Holt and the American Negro Artist Program —Chelsea Daniel and Samantha Ege
Spaces of Sounds: The Peoples of the African Diaspora and Protest in the United States–Vanessa Valdes
On Whiteness and Sound Studies–Gus Stadler
Share this:

Echo and the Chorus of Female Machines

 Editor’s Note: February may be over, but our forum is still on! Today I bring you installment #5 of Sounding Out!‘s blog forum on gender and voice. Last week Art Blake talked about how his experience shifting his voice from feminine to masculine as a transgender man intersects with his work on John Cage. Before that, Regina Bradley put the soundtrack of Scandal in conversation with race and gender. The week before I talked about what it meant to have people call me, a woman of color, “loud.” That post was preceded by Christine Ehrick‘s selections from her forthcoming book, on the gendered soundscape. We have one more left! Robin James will round out our forum with an analysis of how ideas of what women should sound like have roots in Greek philosophy.
Editor’s Note: February may be over, but our forum is still on! Today I bring you installment #5 of Sounding Out!‘s blog forum on gender and voice. Last week Art Blake talked about how his experience shifting his voice from feminine to masculine as a transgender man intersects with his work on John Cage. Before that, Regina Bradley put the soundtrack of Scandal in conversation with race and gender. The week before I talked about what it meant to have people call me, a woman of color, “loud.” That post was preceded by Christine Ehrick‘s selections from her forthcoming book, on the gendered soundscape. We have one more left! Robin James will round out our forum with an analysis of how ideas of what women should sound like have roots in Greek philosophy.
This week Canadian artist and writer AO Roberts takes us into the arena of speech synthesis and makes us wonder about what it means that the voices are so often female. So, lean in, close your eyes, and don’t be afraid of the robots’ voices. –Liana M. Silva, Managing Editor
—
I used Apple’s SIRI for the first time on an iPhone 4S. After hundreds of miles in a van full of people on a cross-country tour, all of the music had been played and the comedy mp3s entirely depleted. So, like so many first time SIRI users, we killed time by asking questions that went from the obscure to the absurd. Passive, awaiting command, prone to glitches: there was something both comedic and insidious about SIRI as female-gendered program, something that seemed to bind up the technology with stereotypical ideas of femininity.

“Maria the Maschinenmensch” by Flickr user Timothy Rose, CC BY-NC-SA 2.0
Speech synthesis is the artificial simulation of the human voice through hardware or software, and SIRI is but one incarnation of the historical chorus of machines speaking what we code to be female. Starting from the early 20th century Voder, to the Cold-War era Silvia and Audrey, up to Amazon’s newly released Echo, researchers have by and large developed these applications as female personae. Each program articulates an individual timbre and character, soothing soft spoken or matter of fact; this is your mother, sister, or lover, here to affirm your interests while reminding you about that missed birthday. She is easy to call up in memory, tones rounded at the edges, like Scarlett Johansson’s smoky conviviality as Samantha in Spike Jonze’s Her, a bodiless purr. Simulated speech articulates a series of assumptions about what neutral articulation is, what a female voice is, and whose voice technology can ventriloquize.
The ways computers hear and speak the human voice are as complex as they are rapidly expanding. But in robotics gender is charted down to actual wavelength, actively policed around 100-150 HZ (male) and 200-250 HZ (female). Now prevalent in entertainment, navigation, law enforcement, surveillance, security, and communications, speech synthesis and recognition hold up an acoustic mirror to the dominant cultures from which they materialize. While they might provide useful tools for everything from time management to self-improvement, they also reinforce cisheteronormative definitions of personhood. Like the binary code that now gives it form, the development of speech recognition separated the entire spectrum of vocal expression into rigid biologically based categories. Ideas of a real voice vs. fake voice, in all their resonances with passing or failing one’s gender performance, have through this process been designed into the technology itself.
A SERIES OF MISERABLE GRUNTS

“Kempelen Speakingmachine” by Fabian Brackhane (Quintatoen), Saarbrücken – Own work. Licensed under Public Domain via Wikimedia Commons –
The first voice to be synthesized was a reed and bellows box invented by Wolfgang Von Kempelen in 1791 and shown off in the courts of the Hapsburg Empire. Von Kempelen had gained renown for his chess-playing Turk, a racist cartoon of an automaton that made waves amongst the nobles until it was revealed that underneath the tabletop was a small man secretly moving the chess player’s limbs. Von Kempelen’s second work, the speaking machine, wowed its audiences thoroughly. The player wheedled and squeezed the contraption, pushing air through its reed larynx to replicate simple words like mama and papa.
Synthesizing the voice has always required some level of making strange, of phonemic abstraction. Bell Laboratories originally developed The Voder, the earliest incarnation of the vocoder, as a cryptographic device for WWII military communications. The machine split the human voice into a spectral representation, fragmenting the source into number of different frequencies that were then recombined into synthetic speech. Noise and unintelligibility shielded the Allies’ phone calls from Nazi interception. The Vocoder’s developer, Ralph Miller, bemoaned the atrocities the machine performed on language, reducing it to a “series of miserable grunts.”

From website Binary Heap-
In his history of the The Vocoder, How to Wreck a Nice Beach, Dave Tompkins tells how the apparatus originally took up an entire wall and was played solely by female phone operators, but the pitch of the female voice was said to be too high to be heard by the nascent technology. In fact, when it debuted at the 1939 World’s Fair, only men were chosen to experience the roboticization of their voice. The Voder was, in fact, originally created to only hear pitches in the range of 100-150 HZ, a designed exclusion from the start. So when the Signal Corps of the Army convinced President Eisenhower to call his wife via Voder from North Africa, Miller and the developers panicked for fear she wouldn’t be heard. Entering the Pentagon late at night, Mamie Eisenhower spoke into the telephone and a fragmented version of her words travelled across the Atlantic. Resurfacing in angular vocoded form, her voice urged her husband to come home, and he had no problem hearing her. Instead of giving the developers pause to question their own definitions of gender, this interaction is told as a derisive footnote of in the history of the sound and technology: the punchline being that the first lady’s voice was heard because it was as low as a man’s.
WAKE WORDS

Screen shot of Amazon’s page for Echo
In fall 2014 Amazon launched Echo, their new personal assistant device. Echo is a 12-inch long plain black cone that stands upright on a tabletop, similar in appearance to a telephoto camera lens. Equipped with far field mics, Echo has a female voice, connected to the cloud and always on standby. Users engage Echo with their own chosen ‘wake’ word. The linguistic similarity to a BDSM safe word could have been lost on developers. Although here inverted, the word is used to engage rather than halt action, awakening an instrument that lays dormant awaiting command.
Amazon’s much-parodied promotional video for Echo is narrated by the innocent voice of the youngest daughter in a happy, straight, white, middle-class family. While the son pitches Oedipal jabs at the father for his dubious role as patriarchal translator of technology, each member of the family soon discovers the ways Echo is useful to them. They name it Alexa and move from questions like: “Alexa how many teaspoons in a tablespoon” and “How tall is Mt. Everest?” to commands for dance mixes and cute jokes. Echo enacts a hybrid role as mother, surrogate companion, and nanny of sorts not through any real aspects of labor but through the intangible contribution of information. As a female-voiced oracle in the early pantheon of the Internet of Things, Echo’s use value is squarely placed in the realm of cisheteronormative domestic knowledge production. Gone are the tongue-in-cheek existential questions proffered to SIRI upon its release. The future with Echo is clean, wholesome, and absolutely SFW. But what does it mean for Echo to be accepted into the home, as a female gendered speaking subject?
Concerns over privacy and surveillance quickly followed Echo’s release, alarms mostly sounding over its “always on” function. Amazon banks on the safety and intimacy we culturally associate with the female voice to ease the transition of robots and AI into the home. If the promotional video painted an accurate picture of Echo’s usage, it would appear that Amazon had successfully launched Echo as a bodiless voice over the uncanny valley, the chasm below littered with broken phalanxes of female machines. Masahiro Mori coined the now familiar term uncanny valley in 1970 to describe the dip in empathic response to humanoid robots as they approach realism.
If we listen to the litany of reactions to robot voices through the filters of gender and sexuality it reveals the stark inclines of what we might think of as a queer uncanny valley. Paulina Palmer wrote in The Queer Uncanny about reoccurring tropes in queer film and literature, expanding upon what Freud saw as a prototypical aspect of the uncanny: the doubling and interchanging of the self. In the queer uncanny we see another kind of rift: that between signifier and signified embodied by trans people, the tearing apart of gender from its biological basis. The non-linear algebra of difference posed by queer and trans bodies is akin to the blurring of divisions between human and machine represented by the cyborg. This is the coupling of transphobic and automatonophobic anxieties, defined always in relation to the responses and preoccupations of a white, able bodied, cisgendered male norm. This is the queer uncanny valley. For the synthesized voice to function here, it must ease the chasm, like Echo: sutured by a voice coded as neutral, but premised upon the imagined body of a white, heterosexual, educated middle class woman.
22% Female
 My own voice spans a range that would have dismayed someone like Ralph Miller. I sang tenor in Junior High choir until I was found out for straying, and then warned to stay properly in the realms of alto, but preferably soprano range. Around the same time I saw a late night feature of Audrey Hepburn in My Fair Lady, struggling to lose her crass proletariat inflection. So I, a working class gender ambivalent kid, walked around with books on my head muttering The Rain In Spain Falls Mainly on the Plain for weeks after. I’m generally loud, opinionated and people remember me for my laugh. I have sung in doom metal and grindcore punk bands, using both screeching highs and the growling “cookie monster” vocal technique mostly employed by cismales.
My own voice spans a range that would have dismayed someone like Ralph Miller. I sang tenor in Junior High choir until I was found out for straying, and then warned to stay properly in the realms of alto, but preferably soprano range. Around the same time I saw a late night feature of Audrey Hepburn in My Fair Lady, struggling to lose her crass proletariat inflection. So I, a working class gender ambivalent kid, walked around with books on my head muttering The Rain In Spain Falls Mainly on the Plain for weeks after. I’m generally loud, opinionated and people remember me for my laugh. I have sung in doom metal and grindcore punk bands, using both screeching highs and the growling “cookie monster” vocal technique mostly employed by cismales.
 Given my own history of toying with and estrangement from what my voice is supposed to sound like, I was interested to try out a new app on the market, the Exceptional Voice App (EVA ), touted as “The World’s First and Only Transgender Voice Training App.” Functioning as a speech recognition program, EVA analyzes the pitch, respiration, and character of your voice with the stated goal of providing training to sound more like one’s authentic self. Behind EVA is Kathe Perez, a speech pathologist and businesswoman, the developer and provider of code to the circuit. And behind the code is the promise of giving proper form to rough sounds, pitch-perfect prosody, safety, acceptance, and wholeness. Informational and training videos are integrated with tonal mimicry for phrases like hee, haa, and ooh. User progress is rated and logged with options to share goals reached on Twitter and Facebook. Customers can buy EVA for Gals or EVA for Guys. I purchased the app online for my iPhone for $5.97.
Given my own history of toying with and estrangement from what my voice is supposed to sound like, I was interested to try out a new app on the market, the Exceptional Voice App (EVA ), touted as “The World’s First and Only Transgender Voice Training App.” Functioning as a speech recognition program, EVA analyzes the pitch, respiration, and character of your voice with the stated goal of providing training to sound more like one’s authentic self. Behind EVA is Kathe Perez, a speech pathologist and businesswoman, the developer and provider of code to the circuit. And behind the code is the promise of giving proper form to rough sounds, pitch-perfect prosody, safety, acceptance, and wholeness. Informational and training videos are integrated with tonal mimicry for phrases like hee, haa, and ooh. User progress is rated and logged with options to share goals reached on Twitter and Facebook. Customers can buy EVA for Gals or EVA for Guys. I purchased the app online for my iPhone for $5.97.
My initial EVA training scores informed me I was 22% female; a recurring number I receive in interfaces with identity recognition software. Facial recognition programs consistently rate my face at 22% female. If I smile I tend to get a higher female response than my neutral face, coded and read as male. Technology is caught up in these translations of gender: we socialize women to smile more than men, then write code for machines to recognize a woman in a face that smiles.
As for EVA’s usage, it seems to be a helpful pedagogical tool with more people sharing their positive results and reviews on trans forums every day. With violence against trans people persisting—even increasing—at alarming rates, experienced worst by trans women of color, the way one’s voice is heard and perceived is a real issue of safety. Programs like EVA can be employed to increase ease of mobility throughout the world. However, EVA is also out of reach to many, a classed capitalist venture that tautologically defines and creates users with supply. The context for EVA is the systems of legal, medical, and scientific categories inherited from Foucault’s era of discipline; the predetermined hallucination of normal sexuality, the invention of biological criteria to define the sexes and the pathologization of those outside each box, controlled by systems of biopower.
Despite all these tools we’ll never really know how we sound. It is true that the resonant chamber of our own skull provides us with a different acoustic image of our own voice. We hate to hear our voice recorded because suddenly we catch a sonic glimpse of what other people hear: sharper more angular tones, higher pitch, less warmth. Speech recognition and synthesis work upon the same logic, the shifting away from interiority; a just off the mark approximation. So the question remains what would a gender variant voice synthesis and recognition sound like? How much is reliant upon the technology and how much depends upon individual listeners, their culture, and what they project upon the voice? As markets grow, so too have more internationally accented English dialects been added to computer programs with voice synthesis. Thai, Indian, Arabic and Eastern European English were added to Mac OSX Lion in 2011. Can we hope to soon offer our voices to the industry not as a set of data to be mined into caricatures, but as a way to assist in the opening up in gender definitions? We would be better served to resist the urge to chime in and listen to the field in the same way we suddenly hear our recorded voice played back, with a focus on the sour notes of cold translation.
—
Featured image: “Golden People love Gold Jewelry Robots” by Flickr user epSos.de, CC BY 2.0
—
AO Roberts is a Canadian intermedia artist and writer based in Oakland whose work explores gender, technology and embodiment through sound, installation and print. A founding member of Winnipeg’s NGTVSPC feminist artist collective, they have shown their work at galleries and festivals internationally. They have also destroyed their vocal chords, played bass and made terrible sounds in a long line of noise projects and grindcore bands, including VOR, Hoover Death, Kursk and Wolbachia. They hold a BFA from the University of Manitoba and a MFA in Sculpture from California College of the Arts.
—
 REWIND!…If you liked this post, you may also dig:
REWIND!…If you liked this post, you may also dig:
Hearing Queerly: NBC’s “The Voice”—Karen Tongson
On Sound and Pleasure: Meditations on the Human Voice—Yvon Bonefant
I Been On: BaddieBey and Beyoncé’s Sonic Masculinity—Regina Bradley
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments