
Echoes in Transit: Loudly Waiting at the Paso del Norte Border Region


This series listens to the political, gendered, queer(ed), racial engagements and class entanglements involved in proclaiming out loud: La-TIN-x. ChI-ca-NA. La-TI-ne. ChI-ca-n-@. Xi-can-x. Funded by an Andrew W. Mellon Foundation as part of the Crossing Latinidades Humanities Research Initiative, the Latinx Sound Cultures Studies Working Group critically considers the role of sound and listening in our formation as political subjects. Through both a comparative and cross-regional lens, we invite Latinx Sound Scholars to join us as we dialogue about our place within the larger fields of Chicanx/Latinx Studies and Sound Studies. We are delighted to publish our initial musings with Sounding Out!, a forum that has long prioritized sound from a queered, racial, working-class and “always-from-below” epistemological standpoint. —Ed. Dolores Inés Casillas
—
This post is co-authored by José Manuel Flores & Dolores Inés Casillas
A borderland is a vague and undetermined place created by the emotional residue of an unnatural boundary. It is in a constant state of transition.
Gloria Anzaldúa (1999)
Ciudad Juárez es número uno/
y la frontera más fabulosa y bella del mundo
Juan Gabriel (lyric to “Juárez es el #1” – 1984)
—
Geographically, the Paso del Norte (PdN) region includes the city of El Paso, Texas, Ciudad Juárez, Mexico, as well as neighboring cities in the state of New Mexico (see map). U.S. citizens live and play in Juárez, and those in Juárez (Juarenses), live and work in El Paso with families extended on both sides; continually moving back and forth. Yet, this broader region has long been plagued with sensationalizing headlines, both in the U.S. and in Mexico, that cast violent and limiting portrayals of these borderland communities. Recognized as sister cities, El Paso and Ciudad Juárez are seen less as close-knit siblings and more like distant cousins with Juárez routinely referred to undesirably as the little sister or ugly sister in comparison to El Paso. Indeed these hierarchical north/south (first world/not-quite-first-world) distinctions are products of histories of colonialism, unequal trade policies, and racial capitalist systems galvanized by immigrant detention camps (a tenant of the Immigration Industrial Complex). Within larger conversations about border cities, both Tijuana (San Diego) and Reynosa (McAllen) are recognized as the “primary” border cities due to their larger population size, transnational capital, and industrious reputations.
Two decades ago, Josh Kun’s concept of the “aural border” invited scholars to consider the US/Mexico border as a “field of sound, a terrain of musicality and music-making, of melodic convergence and dissonant clashing” (2000). Kun’s writings over the years have roused generations of sound scholars to listen to borders, border crossings, border communities and how they reverberate their economic, social, and migrant conditions. This essay intentionally moves away from Kun’s (beloved) border city of Tijuana and towards a less-referenced US/Mexico border city: Ciudad Juárez, Mexico. Here, 1,201 kilometers east of Tijuana, we offer an opportunity to listen to Juárez’s everyday bustling of migratory life through the digital sound repository, the Border Soundscapes Project.
Sound structures our social, cultural, and political relations, and as Tom Western reminds us succinctly: “sounds have politics” (2020). Indeed, Juárez’s soundscapes are microcosms of economic, immigration and border enforcement policies as the city’s migratory composition changes depending on the latest economic crisis in the global south. “Whether intentional or unintentional,” Sarah Barns insists “urban soundscapes are by-products of both active design strategies as well as infrastructure and socio-economic organization” (2014). In essence, listening to migrants within Juárez, along with those planning to traverse Ciudad Juárez (to el norte), shapes our multiethnic and multiracial understandings of Latinidad.

Field audio recordings of public life including nuanced linguistic expressions, comprise a rich sonic site that best demonstrates Juárez’s daily sounds of transit. This Project benefits tremendously from José Manuel Flores’s attentive ear, raised as a borderlander himself, and a seasoned crosser of the bridges linking Juárez and El Paso. Flores created this Project in 2018, the same year, Ciudad Juárez became a prominent make-shift, temporary “home” for groups of migrants – currently a majority of Venezuelan-nationals with previous waves of Cubanos and Salvadoreños. Within Juárez, these migrant caravans initially settled on the primary Paso del Norte bridge and later to nearby main border bridges. Migrants have felt comfortable settling in this arid city of approximately 1.5 million people, while others consider Juárez more of a “waiting room” before setting their sights on securing political asylum in the United States. Either way, Juárez becomes part of both their journey and resettlement.
Below are five instances where we listen to migrants in Juárez.
Track 1: Migrants in Ciudad Juarez: “Te traigo un manguito”
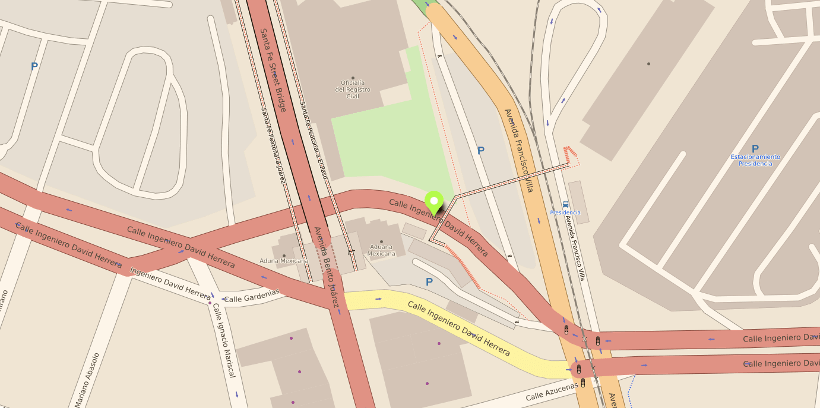
Near the Paso del Nte. International Bridge, in Juárez, on Avenida Juárez, a downtown street where people begin to line up to cross the border. Cars are heard passing. A Venezuelan man wants to rest on this hot day yet his friend cajoles him to get ready to work. He promises his resting friend un mangito o agua (a mango or water) as soon as he’s up and ready to tackle some work.
Track #2: Migrants in Ciudad Juarez: “Cualquier bendición que le sale a tu corazón es buena”
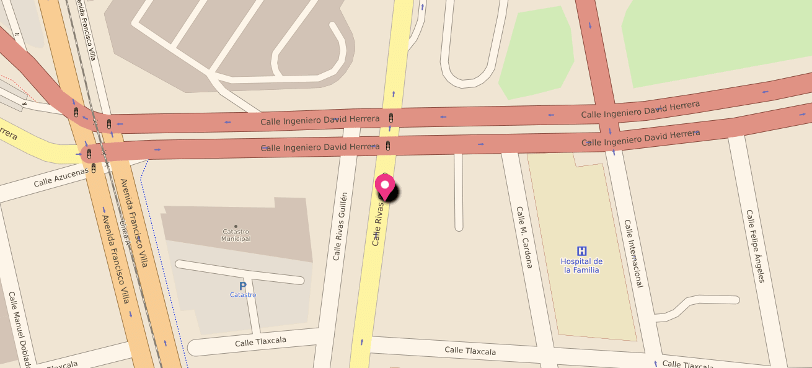
Near Juárez’s Migration’s national institute and Presidencia Municipal de Ciudad Juárez, an older woman cleans car windshields during traffic stops. As she cleans, she is heard laughing while conversing and doling out bendiciones (blessings) to those who gave her work. She’s assumed to be Venezuelan yet her use of the word “carnal” –a Mexican phrase to say brother – indicates that she’s been in Juárez for sometime.
Track #3: Migrants in Ciudad Juarez: “El Escandalo”
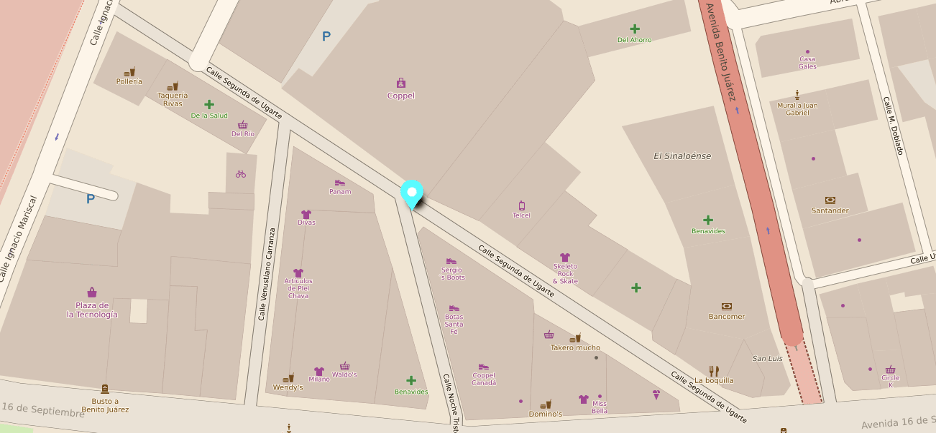
Local news highlights the influx of migrant caravans in promising tones. In an interview for local and national media in Mexico, Mr. José Luis Cruzalta, Cuban migrant, comments that: “no hay que ir para el lado de allá (EE.UU.), aquí se vive igual o mejor que del lado de allá, menos sacrificio, sin meterte en problemas, aquí no hay problemas de ningún tipo.”
“you don’t have to go there (USA), here you live the same or better than on that side, less sacrifice, without getting into trouble, there are no problems of any kind here, they can stay here.”
He later sends assurances that there is enough work for everyone and that only a willingness and desire to work is required, that nothing else.
Track #4: Migrants in Ciudad Juarez: “Rincon Cubano”
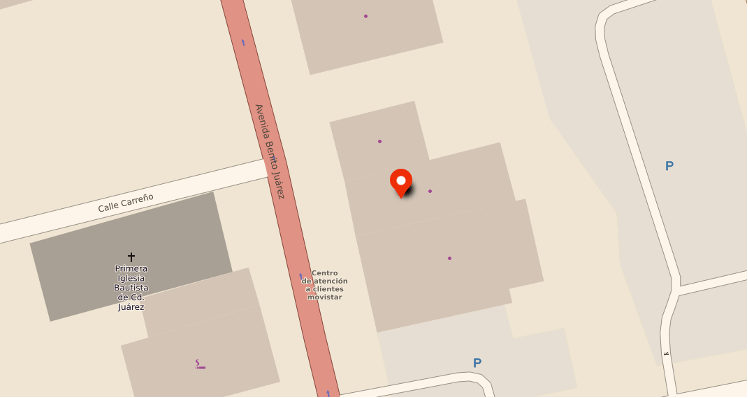
A group of Cuban migrants started a small Creole street food business offering “frituras de maíz” and Cuban “tamales.” The sound space of the downtown of Ciudad Juárez is nourished by the voices of a group of Cubans proclaiming Cuban Corn, “Maíz Cubano”. These contemporary Cuban criers conjure the city’s sonic memories of previous food vendors. Flores remembers fondly as a child the shouting of “Caldo de Oso” (Bear Broth) for sale and the fear that he’d find a grizzly bear in his soup.
Track #5: Migrants In Ciudad Juarez: Haitians Talking in La Taquería
The small restaurant,”La Taqueria,” in downtown Juárez has undergone ethnic transformations. A few years ago it used to be a place known for traditional Cuban food –el rincón cubano–, nowadays it is a place recognized for its tasty, Venezuelan food. Caribbean music attracts some Haitian migrants to this place, inside the restaurant there are some families eating and having a restful moment. Outside the place, there are some Haitian families moving through the city carrying their luggage.
Bonus Track and Outro
The Border Soundscapes Project offers an acoustic ecology of this region through a site that acts as part-archive, part-map, and perhaps even, part-love-song, à la the late singer Juan Gabriel, a globally famous Juaranese who dedicated six songs to his beloved home city.
The Border Soundscapes Project invites listeners to hear for yourself why Juan Gabriel characterized Juárez as the most beautiful borderland in the world. His lyrics fiercely defended Juárez, and decades later, the Border Soundscapes Projects demonstrates how Juarez, the “little sister,” dignifies their migrant communities, in the critical context of Gloría Anzaldúa’s conceptions of borders as vague, “unnatural boundaries” crafted by the “emotional residue” of two other siblings: colonialism and capitalism.
Inspired by the written musings of Valeria Luiselli (2019), the Border Soundscapes Project also functions as an “inventory of echoes,” where sounds are not simply recovered or used within a larger catalog project. Instead, sounds are considered “present in the time of recording and that, when we listen to them, remind us of the ones that are lost” (p. 141), and we would add, in transit. Most importantly, echoes cannot be placed on static, visual representations of standard “maps.” In offering audio snippets of Juárez’s public life, sound becomes a different migrant-led “scale of analysis” (DeLeon 2016); a type of audio counter-mapping of the U.S./Mexico border that lends itself uniquely to sound.
—
Featured Image by Flickr User Simon Foot, “Ciudad Juárez, from El Paso, Texas” (CC BY-NC-ND 2.0)
—
José Manuel Flores is a Ph.D. student in the Rhetoric and Composition Program at The University of Texas at El Paso. He holds an MA in Studies and Creative Processes in Art and Design. He considers that the sounds that arise between the Juarez and El Paso border are relevant because they contribute to the historical heritage of the region. That is why his interest as a researcher focuses on Sound Studies, specifically in the intersection between Soundscapes and philosophy from a disciplinary posture of rhetoric.
Dolores Inés Casillas is Professor of Chicana and Chicano Studies and Director of the Chicano Studies Institute (CSI) at the University of California, Santa Barbara. She is author of Sounds of Belonging: U.S. Spanish-language Radio and Public Advocacy (2014), which received two book prizes, and co-editor of the Companion to Latina/o Media Studies (2016) and Feeling It: Language, Race and Affect in Latinx Youth Learning (2018).
—

REWIND!…If you liked this post, you may also dig:
Xicanacimiento, Life-giving Sonics of Critical Consciousness—Esther Díaz Martín and Kristian E. Vasquez
Ronca Realness: Voices that Sound the Sucia Body—Cloe Gentile Reyes
SO! READS: Melissa Mora Hidalgo’s Mozlandia: Morrissey Fans in the Borderlands–Nabeel Zuberi
Your Voice is (Not) Your Passport–Michelle Pfeiffer
Óyeme Voz: U.S. Latin@ & Immigrant Communities Re-Sound Citizenship and Belonging-Nancy Morales
“Don’t Be Self-Conchas”: Listening to Mexican Styled Phonetics in Popular Culture*–Sara Hinijos and Inés Casillas
“Listening to the Border: ‘”2487″: Giving Voice in Diaspora’ and the Sound Art of Luz María Sánchez”-D. Ines Casillas
Share this:

The Cyborg’s Prosody, or Speech AI and the Displacement of Feeling


In summer 2021, sound artist, engineer, musician, and educator Johann Diedrick convened a panel at the intersection of racial bias, listening, and AI technology at Pioneerworks in Brooklyn, NY. Diedrick, 2021 Mozilla Creative Media award recipient and creator of such works as Dark Matters, is currently working on identifying the origins of racial bias in voice interface systems. Dark Matters, according to Squeaky Wheel, “exposes the absence of Black speech in the datasets used to train voice interface systems in consumer artificial intelligence products such as Alexa and Siri. Utilizing 3D modeling, sound, and storytelling, the project challenges our communities to grapple with racism and inequity through speech and the spoken word, and how AI systems underserve Black communities.” And now, he’s working with SO! as guest editor for this series (along with ed-in-chief JS!). It kicked off with Amina Abbas-Nazari’s post, helping us to understand how Speech AI systems operate from a very limiting set of assumptions about the human voice. Then, Golden Owens took a deep historical dive into the racialized sound of servitude in America and how this impacts Intelligent Virtual Assistants. Last week, Michelle Pfeifer explored how some nations are attempting to draw sonic borders, despite the fact that voices are not passports. Today, Dorothy R. Santos wraps up the series with a meditation on what we lose due to the intensified surveilling, tracking, and modulation of our voices. [To read the full series, click here] –JS
—

In 2010, science fiction writer Charles Yu wrote a story titled “Standard Loneliness Package,” where emotions are outsourced to another human being. While Yu’s story is a literal depiction, albeit fictitious, of what might be entailed and the considerations that need to be made of emotional labor, it was published a year prior to Apple introducing Siri as its official voice assistant for the iPhone. Humans are not meant to be viewed as a type of technology, yet capitalist and neoliberal logics continue to turn to technology as a solution to erase or filter what is least desirable even if that means the literal modification of voice, accent, and language. What do these actions do to the body at risk of severe fragmentation and compartmentalization?
I weep.
I wail.
I gnash my teeth.
Underneath it all, I am smiling. I am giggling.
I am at a funeral. My client’s heart aches, and inside of it is my heart, not aching, the opposite of aching—doing that, whatever it is.
Charles Yu, “Standard Loneliness Package,” Lightspeed: Science Fiction & Fantasy, November 2010
Yu sets the scene by providing specific examples of feelings of pain and loss that might be handed off to an agent who absorbs the feelings. He shows us, in one way, what a world might look and feel like if we were to go to the extreme of eradicating and off loading our most vulnerable moments to an agent or technician meant to take on this labor. Although written well over a decade ago, its prescient take on the future of feelings wasn’t too far off from where we find ourselves in 2023. How does the voice play into these connections between Yu’s story and what we’re facing in the technological age of voice recognition, speech synthesis, and assistive technologies? How might we re-imagine having the choice to displace our burdens onto another being or entity? Taking a cue from Yu’s story, technologies are being created that pull at the heartstrings of our memories and nostalgia. Yet what happens when we are thrust into a perpetual state of grieving and loss?
Humans are made to forget. Unlike a computer, we are fed information required for our survival. When it comes to language and expression, it is often a stochastic process of figuring out for whom we speak and who is on the receiving end of our communication and speech. Artist and scholar Fabiola Hanna believes polyvocality necessitates an active and engaged listener, which then produces our memories. Machines have become the listeners to our sonic landscapes as well as capturers, surveyors, and documents of our utterances.

The past few years may have been a remarkable advancement in voice tech with companies such as Amazon and Sanas AI, a voice recognition platform that allows a user to apply a vocal filter onto any human voice, with a discernible accent, that transforms the speech into Standard American English. Yet their hopes for accent elimination and voice mimicry foreshadow a future of design without justice and software development sans cultural and societal considerations, something I work through in my artwork in progress, The Cyborg’s Prosody (2022-present).
The Cyborg’s Prosody is an interactive web-based artwork (optimized for mobile) that requires participants to read five vignettes that increasingly incorporate Tagalog words and phrases that must be repeated by the player. The work serves as a type of parody, as an “accent induction school” — providing a decolonial method of exploring how language and accents are learned and preserved. The work is a response to the creation of accent reduction schools and coaches in the Philippines. Originally, the work was meant to be a satire and parody of these types of services, but shifted into a docu-poetic work of my mother’s immigration story and learning and becoming fluent in American English.

Even though English is a compulsory language in the Philippines, it is a language learned within the parameters of an educational institution and not common speech outside of schools and businesses. From the call center agents hired at Vox Elite, a BPO company based in the Philippines, to a Filipino immigrant navigating her way through a new environment, the embodiment of language became apparent throughout the stages of research and the creative interventions of the past few years.
In Fall 2022, I gave an artist talk about The Cyborg’s Prosody to a room of predominantly older, white, cisgender male engineers and computer scientists. Apparently, my work caused a stir in one of the conversations between a small group of attendees. A couple of the engineers chose to not address me directly, but I overheard a debate between guests with one of the engineers asking, “What is her project supposed to teach me about prosody? What does mimicking her mom teach me?” He became offended by the prospect of a work that de-centered his language, accent, and what was most familiar to him.The Cyborg’s Prosody is a reversal of what is perceived as a foreign accented voice in the United States into a performance for both the cyborg and the player. I introduce the term western vocal drag to convey the caricature of gender through drag performance, which is apropos and akin to the vocal affect many non-western speakers effectuate in their speech.
The concept of western vocal drag became a way for me to understand and contemplate the ways that language becomes performative through its embodiment. Whether it is learning American vernacular to the complex tenses that give meaning to speech acts, there is always a failure or queering of language when a particular affect and accent is emphasized in one’s speech. The delivery of speech acts is contingent upon setting, cultural context, and whether or not there is a type of transaction occurring between the speaker and listener. In terms of enhancement of speech and accent to conform to a dominant language in the workplace and in relation to global linguistic capitalism, scholar Vijay A. Ramjattan states in that there is no such thing as accent elimination or even reduction. Rather, an accent is modified. The stakes are high when taking into consideration the marketing and branding of software such as Sanas AI that proposes an erasure of non-dominant foreign accented voices.
The biggest fear related to the use of artificial intelligence within voice recognition and speech technologies is the return to a Standard American English (and accent) preferred by a general public that ceases to address, acknowledge, and care about linguistic diversity and inclusion. The technology itself has been marketed as a way for corporations and the BPO companies they hire to mind the mental health of the call center agents subjected to racism and xenophobia just by the mere sound of their voice and accent. The challenge, moving forward, is reversing the need to serve the western world.
A transorality or vocality presents itself when thinking about scholar April Baker-Bell’s work Black Linguistic Consciousness. When Black youth are taught and required to speak with what is considered Standard American English, this presents a type of disciplining that perpetuates raciolinguistic ideologies of what is acceptable speech. Baker-Bell focuses on an antiracist linguistic pedagogy where Black youth are encouraged to express themselves as a shift towards understanding linguistic bias. Deeply inspired by her scholarship, I started to wonder about the process for working on how to begin framing language learning in terms of a multi-consciousness that includes cultural context and affect as a way to bridge gaps in understanding.

Or, let’s re-think this concept or idea that a bad version of English exists. As Cathy Park Hong brilliantly states, “Bad English is my heritage…To other English is to make audible the imperial power sewn into the language, to slit English open so its dark histories slide out.” It is necessary for us all to reconfigure our perceptions of how we listen and communicate that perpetuates seeking familiarity and agreement, but encourages respecting and honoring our differences.
—
Featured Image: Still from artist’s mock-up of The Cyborg’s Prosody(2022-present), copyright Dorothy R. Santos
—
Dorothy R. Santos, Ph.D. (she/they) is a Filipino American storyteller, poet, artist, and scholar whose academic and research interests include feminist media histories, critical medical anthropology, computational media, technology, race, and ethics. She has her Ph.D. in Film and Digital Media with a designated emphasis in Computational Media from the University of California, Santa Cruz and was a Eugene V. Cota-Robles fellow. She received her Master’s degree in Visual and Critical Studies at the California College of the Arts and holds Bachelor’s degrees in Philosophy and Psychology from the University of San Francisco. Her work has been exhibited at Ars Electronica, Rewire Festival, Fort Mason Center for Arts & Culture, Yerba Buena Center for the Arts, and the GLBT Historical Society.
Her writing appears in art21, Art in America, Ars Technica, Hyperallergic, Rhizome, Slate, and Vice Motherboard. Her essay “Materiality to Machines: Manufacturing the Organic and Hypotheses for Future Imaginings,” was published in The Routledge Companion to Biology in Art and Architecture. She is a co-founder of REFRESH, a politically-engaged art and curatorial collective and serves as a member of the Board of Directors for the Processing Foundation. In 2022, she received the Mozilla Creative Media Award for her interactive, docu-poetics work The Cyborg’s Prosody (2022). She serves as an advisory board member for POWRPLNT, slash arts, and House of Alegria.
—

REWIND! . . .If you liked this post, you may also dig:
Your Voice is (Not) Your Passport—Michelle Pfeifer
“Hey Google, Talk Like Issa”: Black Voiced Digital Assistants and the Reshaping of Racial Labor–Golden Owens
Beyond the Every Day: Vocal Potential in AI Mediated Communication –Amina Abbas-Nazari
Voice as Ecology: Voice Donation, Materiality, Identity–Steph Ceraso
The Sound of What Becomes Possible: Language Politics and Jesse Chun’s 술래 SULLAE (2020)—Casey Mecija
Look Who’s Talking, Y’all: Dr. Phil, Vocal Accent and the Politics of Sounding White–Christie Zwahlen
Listening to Modern Family’s Accent–Inés Casillas and Sebastian Ferrada
Share this:





Current Top Posts



April 2021

January 2020

November 2019

October 2019

August 2019

April 2014

November 2017

March 2015

December 2017

October 2015

Recent Comments